 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePROF: An LLM-based Reward Code Preference Optimization Framework for Offline Imitation Learning
Nov 14, 2025



Offline imitation learning (offline IL) enables training effective policies without requiring explicit reward annotations. Recent approaches attempt to estimate rewards for unlabeled datasets using a small set of expert demonstrations. However, these methods often assume that the similarity between a trajectory and an expert demonstration is positively correlated with the reward, which oversimplifies the underlying reward structure. We propose PROF, a novel framework that leverages large language models (LLMs) to generate and improve executable reward function codes from natural language descriptions and a single expert trajectory. We propose Reward Preference Ranking (RPR), a novel reward function quality assessment and ranking strategy without requiring environment interactions or RL training. RPR calculates the dominance scores of the reward functions, where higher scores indicate better alignment with expert preferences. By alternating between RPR and text-based gradient optimization, PROF fully automates the selection and refinement of optimal reward functions for downstream policy learning. Empirical results on D4RL demonstrate that PROF surpasses or matches recent strong baselines across numerous datasets and domains, highlighting the effectiveness of our approach.
Attention as a Compass: Efficient Exploration for Process-Supervised RL in Reasoning Models
Sep 30, 2025Reinforcement Learning (RL) has shown remarkable success in enhancing the reasoning capabilities of Large Language Models (LLMs). Process-Supervised RL (PSRL) has emerged as a more effective paradigm compared to outcome-based RL. However, existing PSRL approaches suffer from limited exploration efficiency, both in terms of branching positions and sampling. In this paper, we introduce a novel PSRL framework (AttnRL), which enables efficient exploration for reasoning models. Motivated by preliminary observations that steps exhibiting high attention scores correlate with reasoning behaviors, we propose to branch from positions with high values. Furthermore, we develop an adaptive sampling strategy that accounts for problem difficulty and historical batch size, ensuring that the whole training batch maintains non-zero advantage values. To further improve sampling efficiency, we design a one-step off-policy training pipeline for PSRL. Extensive experiments on multiple challenging mathematical reasoning benchmarks demonstrate that our method consistently outperforms prior approaches in terms of performance and sampling and training efficiency.
TCPO: Thought-Centric Preference Optimization for Effective Embodied Decision-making
Sep 10, 2025



Using effective generalization capabilities of vision language models (VLMs) in context-specific dynamic tasks for embodied artificial intelligence remains a significant challenge. Although supervised fine-tuned models can better align with the real physical world, they still exhibit sluggish responses and hallucination issues in dynamically changing environments, necessitating further alignment. Existing post-SFT methods, reliant on reinforcement learning and chain-of-thought (CoT) approaches, are constrained by sparse rewards and action-only optimization, resulting in low sample efficiency, poor consistency, and model degradation. To address these issues, this paper proposes Thought-Centric Preference Optimization (TCPO) for effective embodied decision-making. Specifically, TCPO introduces a stepwise preference-based optimization approach, transforming sparse reward signals into richer step sample pairs. It emphasizes the alignment of the model's intermediate reasoning process, mitigating the problem of model degradation. Moreover, by incorporating Action Policy Consistency Constraint (APC), it further imposes consistency constraints on the model output. Experiments in the ALFWorld environment demonstrate an average success rate of 26.67%, achieving a 6% improvement over RL4VLM and validating the effectiveness of our approach in mitigating model degradation after fine-tuning. These results highlight the potential of integrating preference-based learning techniques with CoT processes to enhance the decision-making capabilities of vision-language models in embodied agents.
HERO: Hierarchical Extrapolation and Refresh for Efficient World Models
Aug 25, 2025



Generation-driven world models create immersive virtual environments but suffer slow inference due to the iterative nature of diffusion models. While recent advances have improved diffusion model efficiency, directly applying these techniques to world models introduces limitations such as quality degradation. In this paper, we present HERO, a training-free hierarchical acceleration framework tailored for efficient world models. Owing to the multi-modal nature of world models, we identify a feature coupling phenomenon, wherein shallow layers exhibit high temporal variability, while deeper layers yield more stable feature representations. Motivated by this, HERO adopts hierarchical strategies to accelerate inference: (i) In shallow layers, a patch-wise refresh mechanism efficiently selects tokens for recomputation. With patch-wise sampling and frequency-aware tracking, it avoids extra metric computation and remain compatible with FlashAttention. (ii) In deeper layers, a linear extrapolation scheme directly estimates intermediate features. This completely bypasses the computations in attention modules and feed-forward networks. Our experiments show that HERO achieves a 1.73$\times$ speedup with minimal quality degradation, significantly outperforming existing diffusion acceleration methods.
Puppeteer: Rig and Animate Your 3D Models
Aug 14, 2025



Modern interactive applications increasingly demand dynamic 3D content, yet the transformation of static 3D models into animated assets constitutes a significant bottleneck in content creation pipelines. While recent advances in generative AI have revolutionized static 3D model creation, rigging and animation continue to depend heavily on expert intervention. We present Puppeteer, a comprehensive framework that addresses both automatic rigging and animation for diverse 3D objects. Our system first predicts plausible skeletal structures via an auto-regressive transformer that introduces a joint-based tokenization strategy for compact representation and a hierarchical ordering methodology with stochastic perturbation that enhances bidirectional learning capabilities. It then infers skinning weights via an attention-based architecture incorporating topology-aware joint attention that explicitly encodes inter-joint relationships based on skeletal graph distances. Finally, we complement these rigging advances with a differentiable optimization-based animation pipeline that generates stable, high-fidelity animations while being computationally more efficient than existing approaches. Extensive evaluations across multiple benchmarks demonstrate that our method significantly outperforms state-of-the-art techniques in both skeletal prediction accuracy and skinning quality. The system robustly processes diverse 3D content, ranging from professionally designed game assets to AI-generated shapes, producing temporally coherent animations that eliminate the jittering issues common in existing methods.
InterSyn: Interleaved Learning for Dynamic Motion Synthesis in the Wild
Aug 14, 2025We present Interleaved Learning for Motion Synthesis (InterSyn), a novel framework that targets the generation of realistic interaction motions by learning from integrated motions that consider both solo and multi-person dynamics. Unlike previous methods that treat these components separately, InterSyn employs an interleaved learning strategy to capture the natural, dynamic interactions and nuanced coordination inherent in real-world scenarios. Our framework comprises two key modules: the Interleaved Interaction Synthesis (INS) module, which jointly models solo and interactive behaviors in a unified paradigm from a first-person perspective to support multiple character interactions, and the Relative Coordination Refinement (REC) module, which refines mutual dynamics and ensures synchronized motions among characters. Experimental results show that the motion sequences generated by InterSyn exhibit higher text-to-motion alignment and improved diversity compared with recent methods, setting a new benchmark for robust and natural motion synthesis. Additionally, our code will be open-sourced in the future to promote further research and development in this area.
LoRA-Gen: Specializing Large Language Model via Online LoRA Generation
Jun 13, 2025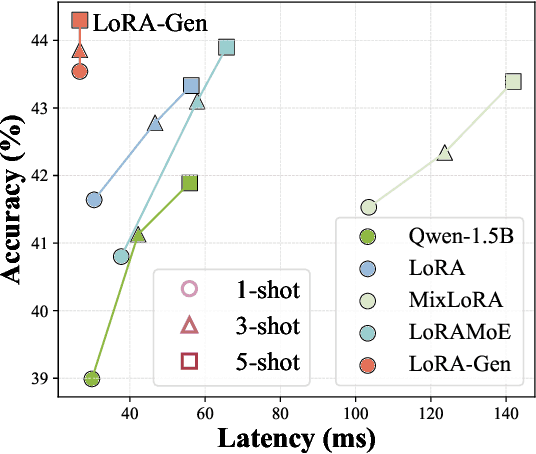

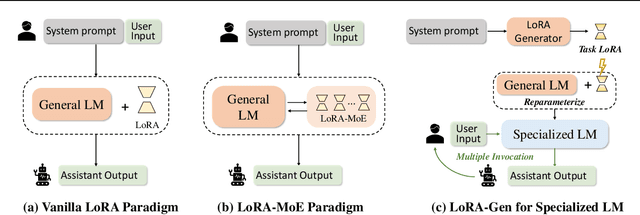
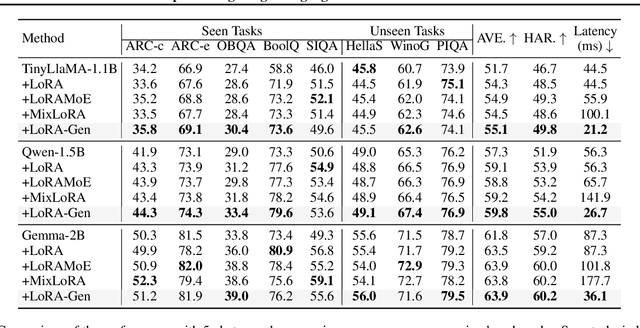
Recent advances have highlighted the benefits of scaling language models to enhance performance across a wide range of NLP tasks. However, these approaches still face limitations in effectiveness and efficiency when applied to domain-specific tasks, particularly for small edge-side models. We propose the LoRA-Gen framework, which utilizes a large cloud-side model to generate LoRA parameters for edge-side models based on task descriptions. By employing the reparameterization technique, we merge the LoRA parameters into the edge-side model to achieve flexible specialization. Our method facilitates knowledge transfer between models while significantly improving the inference efficiency of the specialized model by reducing the input context length. Without specialized training, LoRA-Gen outperforms conventional LoRA fine-tuning, which achieves competitive accuracy and a 2.1x speedup with TinyLLaMA-1.1B in reasoning tasks. Besides, our method delivers a compression ratio of 10.1x with Gemma-2B on intelligent agent tasks.
Uncertainty-Masked Bernoulli Diffusion for Camouflaged Object Detection Refinement
Jun 12, 2025



Camouflaged Object Detection (COD) presents inherent challenges due to the subtle visual differences between targets and their backgrounds. While existing methods have made notable progress, there remains significant potential for post-processing refinement that has yet to be fully explored. To address this limitation, we propose the Uncertainty-Masked Bernoulli Diffusion (UMBD) model, the first generative refinement framework specifically designed for COD. UMBD introduces an uncertainty-guided masking mechanism that selectively applies Bernoulli diffusion to residual regions with poor segmentation quality, enabling targeted refinement while preserving correctly segmented areas. To support this process, we design the Hybrid Uncertainty Quantification Network (HUQNet), which employs a multi-branch architecture and fuses uncertainty from multiple sources to improve estimation accuracy. This enables adaptive guidance during the generative sampling process. The proposed UMBD framework can be seamlessly integrated with a wide range of existing Encoder-Decoder-based COD models, combining their discriminative capabilities with the generative advantages of diffusion-based refinement. Extensive experiments across multiple COD benchmarks demonstrate consistent performance improvements, achieving average gains of 5.5% in MAE and 3.2% in weighted F-measure with only modest computational overhead. Code will be released.
Segment Concealed Objects with Incomplete Supervision
Jun 10, 2025Incompletely-Supervised Concealed Object Segmentation (ISCOS) involves segmenting objects that seamlessly blend into their surrounding environments, utilizing incompletely annotated data, such as weak and semi-annotations, for model training. This task remains highly challenging due to (1) the limited supervision provided by the incompletely annotated training data, and (2) the difficulty of distinguishing concealed objects from the background, which arises from the intrinsic similarities in concealed scenarios. In this paper, we introduce the first unified method for ISCOS to address these challenges. To tackle the issue of incomplete supervision, we propose a unified mean-teacher framework, SEE, that leverages the vision foundation model, ``\emph{Segment Anything Model (SAM)}'', to generate pseudo-labels using coarse masks produced by the teacher model as prompts. To mitigate the effect of low-quality segmentation masks, we introduce a series of strategies for pseudo-label generation, storage, and supervision. These strategies aim to produce informative pseudo-labels, store the best pseudo-labels generated, and select the most reliable components to guide the student model, thereby ensuring robust network training. Additionally, to tackle the issue of intrinsic similarity, we design a hybrid-granularity feature grouping module that groups features at different granularities and aggregates these results. By clustering similar features, this module promotes segmentation coherence, facilitating more complete segmentation for both single-object and multiple-object images. We validate the effectiveness of our approach across multiple ISCOS tasks, and experimental results demonstrate that our method achieves state-of-the-art performance. Furthermore, SEE can serve as a plug-and-play solution, enhancing the performance of existing models.
* IEEE TPAMI
ADG: Ambient Diffusion-Guided Dataset Recovery for Corruption-Robust Offline Reinforcement Learning
May 29, 2025Real-world datasets collected from sensors or human inputs are prone to noise and errors, posing significant challenges for applying offline reinforcement learning (RL). While existing methods have made progress in addressing corrupted actions and rewards, they remain insufficient for handling corruption in high-dimensional state spaces and for cases where multiple elements in the dataset are corrupted simultaneously. Diffusion models, known for their strong denoising capabilities, offer a promising direction for this problem-but their tendency to overfit noisy samples limits their direct applicability. To overcome this, we propose Ambient Diffusion-Guided Dataset Recovery (ADG), a novel approach that pioneers the use of diffusion models to tackle data corruption in offline RL. First, we introduce Ambient Denoising Diffusion Probabilistic Models (DDPM) from approximated distributions, which enable learning on partially corrupted datasets with theoretical guarantees. Second, we use the noise-prediction property of Ambient DDPM to distinguish between clean and corrupted data, and then use the clean subset to train a standard DDPM. Third, we employ the trained standard DDPM to refine the previously identified corrupted data, enhancing data quality for subsequent offline RL training. A notable strength of ADG is its versatility-it can be seamlessly integrated with any offline RL algorithm. Experiments on a range of benchmarks, including MuJoCo, Kitchen, and Adroit, demonstrate that ADG effectively mitigates the impact of corrupted data and improves the robustness of offline RL under various noise settings, achieving state-of-the-art results.