 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAMI: Training-Free Bias Mitigation in GUI Grounding
May 07, 2026GUI grounding is a critical capability for enabling GUI agents to execute tasks such as clicking and dragging. However, in complex scenarios like the ScreenSpot-Pro benchmark, existing models often suffer from suboptimal performance. Utilizing the proposed \textbf{Masked Prediction Distribution (MPD)} attribution method, we identify that the primary sources of errors are twofold: high image resolution (leading to precision bias) and intricate interface elements (resulting in ambiguity bias). To address these challenges, we introduce \textbf{Bias-Aware Manipulation Inference (BAMI)}, which incorporates two key manipulations, coarse-to-fine focus and candidate selection, to effectively mitigate these biases. Our extensive experimental results demonstrate that BAMI significantly enhances the accuracy of various GUI grounding models in a training-free setting. For instance, applying our method to the TianXi-Action-7B model boosts its accuracy on the ScreenSpot-Pro benchmark from 51.9\% to 57.8\%. Furthermore, ablation studies confirm the robustness of the BAMI approach across diverse parameter configurations, highlighting its stability and effectiveness. Code is available at https://github.com/Neur-IO/BAMI.
AdaZoom-GUI: Adaptive Zoom-based GUI Grounding with Instruction Refinement
Mar 18, 2026GUI grounding is a critical capability for vision-language models (VLMs) that enables automated interaction with graphical user interfaces by locating target elements from natural language instructions. However, grounding on GUI screenshots remains challenging due to high-resolution images, small UI elements, and ambiguous user instructions. In this work, we propose AdaZoom-GUI, an adaptive zoom-based GUI grounding framework that improves both localization accuracy and instruction understanding. Our approach introduces an instruction refinement module that rewrites natural language commands into explicit and detailed descriptions, allowing the grounding model to focus on precise element localization. In addition, we design a conditional zoom-in strategy that selectively performs a second-stage inference on predicted small elements, improving localization accuracy while avoiding unnecessary computation and context loss on simpler cases. To support this framework, we construct a high-quality GUI grounding dataset and train the grounding model using Group Relative Policy Optimization (GRPO), enabling the model to predict both click coordinates and element bounding boxes. Experiments on public benchmarks demonstrate that our method achieves state-of-the-art performance among models with comparable or even larger parameter sizes, highlighting its effectiveness for high-resolution GUI understanding and practical GUI agent deployment.
WildGHand: Learning Anti-Perturbation Gaussian Hand Avatars from Monocular In-the-Wild Videos
Feb 24, 2026Despite recent progress in 3D hand reconstruction from monocular videos, most existing methods rely on data captured in well-controlled environments and therefore degrade in real-world settings with severe perturbations, such as hand-object interactions, extreme poses, illumination changes, and motion blur. To tackle these issues, we introduce WildGHand, an optimization-based framework that enables self-adaptive 3D Gaussian splatting on in-the-wild videos and produces high-fidelity hand avatars. WildGHand incorporates two key components: (i) a dynamic perturbation disentanglement module that explicitly represents perturbations as time-varying biases on 3D Gaussian attributes during optimization, and (ii) a perturbation-aware optimization strategy that generates per-frame anisotropic weighted masks to guide optimization. Together, these components allow the framework to identify and suppress perturbations across both spatial and temporal dimensions. We further curate a dataset of monocular hand videos captured under diverse perturbations to benchmark in-the-wild hand avatar reconstruction. Extensive experiments on this dataset and two public datasets demonstrate that WildGHand achieves state-of-the-art performance and substantially improves over its base model across multiple metrics (e.g., up to a $15.8\%$ relative gain in PSNR and a $23.1\%$ relative reduction in LPIPS). Our implementation and dataset are available at https://github.com/XuanHuang0/WildGHand.
LaVieID: Local Autoregressive Diffusion Transformers for Identity-Preserving Video Creation
Aug 11, 2025

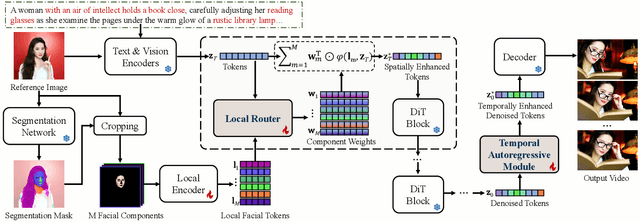

In this paper, we present LaVieID, a novel \underline{l}ocal \underline{a}utoregressive \underline{vi}d\underline{e}o diffusion framework designed to tackle the challenging \underline{id}entity-preserving text-to-video task. The key idea of LaVieID is to mitigate the loss of identity information inherent in the stochastic global generation process of diffusion transformers (DiTs) from both spatial and temporal perspectives. Specifically, unlike the global and unstructured modeling of facial latent states in existing DiTs, LaVieID introduces a local router to explicitly represent latent states by weighted combinations of fine-grained local facial structures. This alleviates undesirable feature interference and encourages DiTs to capture distinctive facial characteristics. Furthermore, a temporal autoregressive module is integrated into LaVieID to refine denoised latent tokens before video decoding. This module divides latent tokens temporally into chunks, exploiting their long-range temporal dependencies to predict biases for rectifying tokens, thereby significantly enhancing inter-frame identity consistency. Consequently, LaVieID can generate high-fidelity personalized videos and achieve state-of-the-art performance. Our code and models are available at https://github.com/ssugarwh/LaVieID.
SEA: Self-Evolution Agent with Step-wise Reward for Computer Use
Aug 06, 2025Computer use agent is an emerging area in artificial intelligence that aims to operate the computers to achieve the user's tasks, which attracts a lot of attention from both industry and academia. However, the present agents' performance is far from being used. In this paper, we propose the Self-Evolution Agent (SEA) for computer use, and to develop this agent, we propose creative methods in data generation, reinforcement learning, and model enhancement. Specifically, we first propose an automatic pipeline to generate the verifiable trajectory for training. And then, we propose efficient step-wise reinforcement learning to alleviate the significant computational requirements for long-horizon training. In the end, we propose the enhancement method to merge the grounding and planning ability into one model without any extra training. Accordingly, based on our proposed innovation of data generation, training strategy, and enhancement, we get the Selfevolution Agent (SEA) for computer use with only 7B parameters, which outperforms models with the same number of parameters and has comparable performance to larger ones. We will make the models' weight and related codes open-source in the future.
EffOWT: Transfer Visual Language Models to Open-World Tracking Efficiently and Effectively
Apr 09, 2025Open-World Tracking (OWT) aims to track every object of any category, which requires the model to have strong generalization capabilities. Trackers can improve their generalization ability by leveraging Visual Language Models (VLMs). However, challenges arise with the fine-tuning strategies when VLMs are transferred to OWT: full fine-tuning results in excessive parameter and memory costs, while the zero-shot strategy leads to sub-optimal performance. To solve the problem, EffOWT is proposed for efficiently transferring VLMs to OWT. Specifically, we build a small and independent learnable side network outside the VLM backbone. By freezing the backbone and only executing backpropagation on the side network, the model's efficiency requirements can be met. In addition, EffOWT enhances the side network by proposing a hybrid structure of Transformer and CNN to improve the model's performance in the OWT field. Finally, we implement sparse interactions on the MLP, thus reducing parameter updates and memory costs significantly. Thanks to the proposed methods, EffOWT achieves an absolute gain of 5.5% on the tracking metric OWTA for unknown categories, while only updating 1.3% of the parameters compared to full fine-tuning, with a 36.4% memory saving. Other metrics also demonstrate obvious improvement.
ArtCrafter: Text-Image Aligning Style Transfer via Embedding Reframing
Jan 03, 2025



Recent years have witnessed significant advancements in text-guided style transfer, primarily attributed to innovations in diffusion models. These models excel in conditional guidance, utilizing text or images to direct the sampling process. However, despite their capabilities, direct conditional guidance approaches often face challenges in balancing the expressiveness of textual semantics with the diversity of output results while capturing stylistic features. To address these challenges, we introduce ArtCrafter, a novel framework for text-to-image style transfer. Specifically, we introduce an attention-based style extraction module, meticulously engineered to capture the subtle stylistic elements within an image. This module features a multi-layer architecture that leverages the capabilities of perceiver attention mechanisms to integrate fine-grained information. Additionally, we present a novel text-image aligning augmentation component that adeptly balances control over both modalities, enabling the model to efficiently map image and text embeddings into a shared feature space. We achieve this through attention operations that enable smooth information flow between modalities. Lastly, we incorporate an explicit modulation that seamlessly blends multimodal enhanced embeddings with original embeddings through an embedding reframing design, empowering the model to generate diverse outputs. Extensive experiments demonstrate that ArtCrafter yields impressive results in visual stylization, exhibiting exceptional levels of stylistic intensity, controllability, and diversity.
Learning Interaction-aware 3D Gaussian Splatting for One-shot Hand Avatars
Oct 11, 2024



In this paper, we propose to create animatable avatars for interacting hands with 3D Gaussian Splatting (GS) and single-image inputs. Existing GS-based methods designed for single subjects often yield unsatisfactory results due to limited input views, various hand poses, and occlusions. To address these challenges, we introduce a novel two-stage interaction-aware GS framework that exploits cross-subject hand priors and refines 3D Gaussians in interacting areas. Particularly, to handle hand variations, we disentangle the 3D presentation of hands into optimization-based identity maps and learning-based latent geometric features and neural texture maps. Learning-based features are captured by trained networks to provide reliable priors for poses, shapes, and textures, while optimization-based identity maps enable efficient one-shot fitting of out-of-distribution hands. Furthermore, we devise an interaction-aware attention module and a self-adaptive Gaussian refinement module. These modules enhance image rendering quality in areas with intra- and inter-hand interactions, overcoming the limitations of existing GS-based methods. Our proposed method is validated via extensive experiments on the large-scale InterHand2.6M dataset, and it significantly improves the state-of-the-art performance in image quality. Project Page: \url{https://github.com/XuanHuang0/GuassianHand}.
GarmentAligner: Text-to-Garment Generation via Retrieval-augmented Multi-level Corrections
Aug 23, 2024



General text-to-image models bring revolutionary innovation to the fields of arts, design, and media. However, when applied to garment generation, even the state-of-the-art text-to-image models suffer from fine-grained semantic misalignment, particularly concerning the quantity, position, and interrelations of garment components. Addressing this, we propose GarmentAligner, a text-to-garment diffusion model trained with retrieval-augmented multi-level corrections. To achieve semantic alignment at the component level, we introduce an automatic component extraction pipeline to obtain spatial and quantitative information of garment components from corresponding images and captions. Subsequently, to exploit component relationships within the garment images, we construct retrieval subsets for each garment by retrieval augmentation based on component-level similarity ranking and conduct contrastive learning to enhance the model perception of components from positive and negative samples. To further enhance the alignment of components across semantic, spatial, and quantitative granularities, we propose the utilization of multi-level correction losses that leverage detailed component information. The experimental findings demonstrate that GarmentAligner achieves superior fidelity and fine-grained semantic alignment when compared to existing competitors.
AutoStudio: Crafting Consistent Subjects in Multi-turn Interactive Image Generation
Jun 03, 2024As cutting-edge Text-to-Image (T2I) generation models already excel at producing remarkable single images, an even more challenging task, i.e., multi-turn interactive image generation begins to attract the attention of related research communities. This task requires models to interact with users over multiple turns to generate a coherent sequence of images. However, since users may switch subjects frequently, current efforts struggle to maintain subject consistency while generating diverse images. To address this issue, we introduce a training-free multi-agent framework called AutoStudio. AutoStudio employs three agents based on large language models (LLMs) to handle interactions, along with a stable diffusion (SD) based agent for generating high-quality images. Specifically, AutoStudio consists of (i) a subject manager to interpret interaction dialogues and manage the context of each subject, (ii) a layout generator to generate fine-grained bounding boxes to control subject locations, (iii) a supervisor to provide suggestions for layout refinements, and (iv) a drawer to complete image generation. Furthermore, we introduce a Parallel-UNet to replace the original UNet in the drawer, which employs two parallel cross-attention modules for exploiting subject-aware features. We also introduce a subject-initialized generation method to better preserve small subjects. Our AutoStudio hereby can generate a sequence of multi-subject images interactively and consistently. Extensive experiments on the public CMIGBench benchmark and human evaluations show that AutoStudio maintains multi-subject consistency across multiple turns well, and it also raises the state-of-the-art performance by 13.65% in average Frechet Inception Distance and 2.83% in average character-character similarity.