 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPATIALGEN: Layout-guided 3D Indoor Scene Generation
Sep 18, 2025
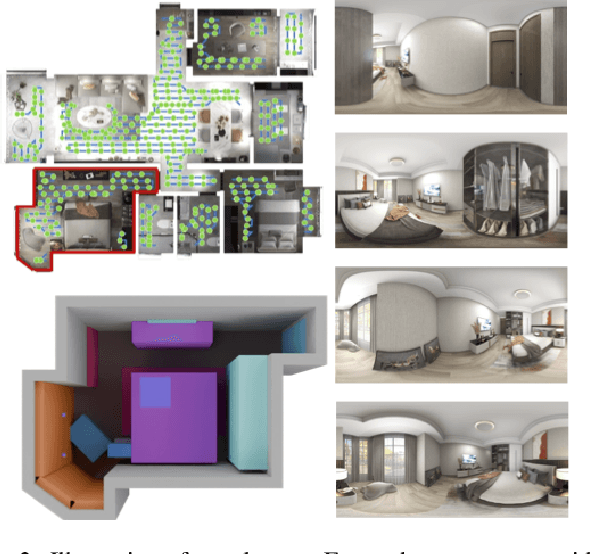
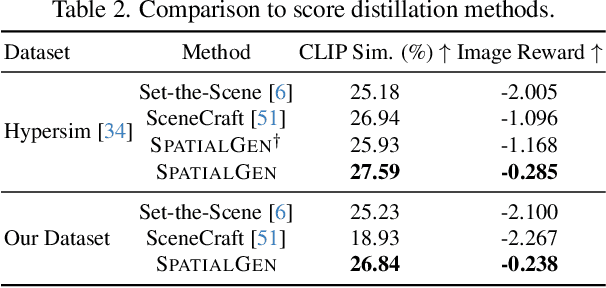
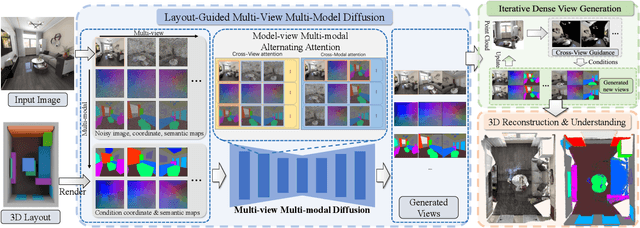
Creating high-fidelity 3D models of indoor environments is essential for applications in design, virtual reality, and robotics. However, manual 3D modeling remains time-consuming and labor-intensive. While recent advances in generative AI have enabled automated scene synthesis, existing methods often face challenges in balancing visual quality, diversity, semantic consistency, and user control. A major bottleneck is the lack of a large-scale, high-quality dataset tailored to this task. To address this gap, we introduce a comprehensive synthetic dataset, featuring 12,328 structured annotated scenes with 57,440 rooms, and 4.7M photorealistic 2D renderings. Leveraging this dataset, we present SpatialGen, a novel multi-view multi-modal diffusion model that generates realistic and semantically consistent 3D indoor scenes. Given a 3D layout and a reference image (derived from a text prompt), our model synthesizes appearance (color image), geometry (scene coordinate map), and semantic (semantic segmentation map) from arbitrary viewpoints, while preserving spatial consistency across modalities. SpatialGen consistently generates superior results to previous methods in our experiments. We are open-sourcing our data and models to empower the community and advance the field of indoor scene understanding and generation.
UniTEX: Universal High Fidelity Generative Texturing for 3D Shapes
May 29, 2025We present UniTEX, a novel two-stage 3D texture generation framework to create high-quality, consistent textures for 3D assets. Existing approaches predominantly rely on UV-based inpainting to refine textures after reprojecting the generated multi-view images onto the 3D shapes, which introduces challenges related to topological ambiguity. To address this, we propose to bypass the limitations of UV mapping by operating directly in a unified 3D functional space. Specifically, we first propose that lifts texture generation into 3D space via Texture Functions (TFs)--a continuous, volumetric representation that maps any 3D point to a texture value based solely on surface proximity, independent of mesh topology. Then, we propose to predict these TFs directly from images and geometry inputs using a transformer-based Large Texturing Model (LTM). To further enhance texture quality and leverage powerful 2D priors, we develop an advanced LoRA-based strategy for efficiently adapting large-scale Diffusion Transformers (DiTs) for high-quality multi-view texture synthesis as our first stage. Extensive experiments demonstrate that UniTEX achieves superior visual quality and texture integrity compared to existing approaches, offering a generalizable and scalable solution for automated 3D texture generation. Code will available in: https://github.com/YixunLiang/UniTEX.
X-LRM: X-ray Large Reconstruction Model for Extremely Sparse-View Computed Tomography Recovery in One Second
Mar 09, 2025Sparse-view 3D CT reconstruction aims to recover volumetric structures from a limited number of 2D X-ray projections. Existing feedforward methods are constrained by the limited capacity of CNN-based architectures and the scarcity of large-scale training datasets. In this paper, we propose an X-ray Large Reconstruction Model (X-LRM) for extremely sparse-view (<10 views) CT reconstruction. X-LRM consists of two key components: X-former and X-triplane. Our X-former can handle an arbitrary number of input views using an MLP-based image tokenizer and a Transformer-based encoder. The output tokens are then upsampled into our X-triplane representation, which models the 3D radiodensity as an implicit neural field. To support the training of X-LRM, we introduce Torso-16K, a large-scale dataset comprising over 16K volume-projection pairs of various torso organs. Extensive experiments demonstrate that X-LRM outperforms the state-of-the-art method by 1.5 dB and achieves 27x faster speed and better flexibility. Furthermore, the downstream evaluation of lung segmentation tasks also suggests the practical value of our approach. Our code, pre-trained models, and dataset will be released at https://github.com/caiyuanhao1998/X-LRM
Dora: Sampling and Benchmarking for 3D Shape Variational Auto-Encoders
Dec 24, 2024



Recent 3D content generation pipelines commonly employ Variational Autoencoders (VAEs) to encode shapes into compact latent representations for diffusion-based generation. However, the widely adopted uniform point sampling strategy in Shape VAE training often leads to a significant loss of geometric details, limiting the quality of shape reconstruction and downstream generation tasks. We present Dora-VAE, a novel approach that enhances VAE reconstruction through our proposed sharp edge sampling strategy and a dual cross-attention mechanism. By identifying and prioritizing regions with high geometric complexity during training, our method significantly improves the preservation of fine-grained shape features. Such sampling strategy and the dual attention mechanism enable the VAE to focus on crucial geometric details that are typically missed by uniform sampling approaches. To systematically evaluate VAE reconstruction quality, we additionally propose Dora-bench, a benchmark that quantifies shape complexity through the density of sharp edges, introducing a new metric focused on reconstruction accuracy at these salient geometric features. Extensive experiments on the Dora-bench demonstrate that Dora-VAE achieves comparable reconstruction quality to the state-of-the-art dense XCube-VAE while requiring a latent space at least 8$\times$ smaller (1,280 vs. > 10,000 codes). We will release our code and benchmark dataset to facilitate future research in 3D shape modeling.
Baking Gaussian Splatting into Diffusion Denoiser for Fast and Scalable Single-stage Image-to-3D Generation
Nov 21, 2024



Existing feed-forward image-to-3D methods mainly rely on 2D multi-view diffusion models that cannot guarantee 3D consistency. These methods easily collapse when changing the prompt view direction and mainly handle object-centric prompt images. In this paper, we propose a novel single-stage 3D diffusion model, DiffusionGS, for object and scene generation from a single view. DiffusionGS directly outputs 3D Gaussian point clouds at each timestep to enforce view consistency and allow the model to generate robustly given prompt views of any directions, beyond object-centric inputs. Plus, to improve the capability and generalization ability of DiffusionGS, we scale up 3D training data by developing a scene-object mixed training strategy. Experiments show that our method enjoys better generation quality (2.20 dB higher in PSNR and 23.25 lower in FID) and over 5x faster speed (~6s on an A100 GPU) than SOTA methods. The user study and text-to-3D applications also reveals the practical values of our method. Our Project page at https://caiyuanhao1998.github.io/project/DiffusionGS/ shows the video and interactive generation results.
LucidFusion: Generating 3D Gaussians with Arbitrary Unposed Images
Oct 21, 2024



Recent large reconstruction models have made notable progress in generating high-quality 3D objects from single images. However, these methods often struggle with controllability, as they lack information from multiple views, leading to incomplete or inconsistent 3D reconstructions. To address this limitation, we introduce LucidFusion, a flexible end-to-end feed-forward framework that leverages the Relative Coordinate Map (RCM). Unlike traditional methods linking images to 3D world thorough pose, LucidFusion utilizes RCM to align geometric features coherently across different views, making it highly adaptable for 3D generation from arbitrary, unposed images. Furthermore, LucidFusion seamlessly integrates with the original single-image-to-3D pipeline, producing detailed 3D Gaussians at a resolution of $512 \times 512$, making it well-suited for a wide range of applications.
Lotus: Diffusion-based Visual Foundation Model for High-quality Dense Prediction
Sep 26, 2024



Leveraging the visual priors of pre-trained text-to-image diffusion models offers a promising solution to enhance zero-shot generalization in dense prediction tasks. However, existing methods often uncritically use the original diffusion formulation, which may not be optimal due to the fundamental differences between dense prediction and image generation. In this paper, we provide a systemic analysis of the diffusion formulation for the dense prediction, focusing on both quality and efficiency. And we find that the original parameterization type for image generation, which learns to predict noise, is harmful for dense prediction; the multi-step noising/denoising diffusion process is also unnecessary and challenging to optimize. Based on these insights, we introduce Lotus, a diffusion-based visual foundation model with a simple yet effective adaptation protocol for dense prediction. Specifically, Lotus is trained to directly predict annotations instead of noise, thereby avoiding harmful variance. We also reformulate the diffusion process into a single-step procedure, simplifying optimization and significantly boosting inference speed. Additionally, we introduce a novel tuning strategy called detail preserver, which achieves more accurate and fine-grained predictions. Without scaling up the training data or model capacity, Lotus achieves SoTA performance in zero-shot depth and normal estimation across various datasets. It also significantly enhances efficiency, being hundreds of times faster than most existing diffusion-based methods.
DreamMapping: High-Fidelity Text-to-3D Generation via Variational Distribution Mapping
Sep 11, 2024



Score Distillation Sampling (SDS) has emerged as a prevalent technique for text-to-3D generation, enabling 3D content creation by distilling view-dependent information from text-to-2D guidance. However, they frequently exhibit shortcomings such as over-saturated color and excess smoothness. In this paper, we conduct a thorough analysis of SDS and refine its formulation, finding that the core design is to model the distribution of rendered images. Following this insight, we introduce a novel strategy called Variational Distribution Mapping (VDM), which expedites the distribution modeling process by regarding the rendered images as instances of degradation from diffusion-based generation. This special design enables the efficient training of variational distribution by skipping the calculations of the Jacobians in the diffusion U-Net. We also introduce timestep-dependent Distribution Coefficient Annealing (DCA) to further improve distilling precision. Leveraging VDM and DCA, we use Gaussian Splatting as the 3D representation and build a text-to-3D generation framework. Extensive experiments and evaluations demonstrate the capability of VDM and DCA to generate high-fidelity and realistic assets with optimization efficiency.
M-LRM: Multi-view Large Reconstruction Model
Jun 11, 2024



Despite recent advancements in the Large Reconstruction Model (LRM) demonstrating impressive results, when extending its input from single image to multiple images, it exhibits inefficiencies, subpar geometric and texture quality, as well as slower convergence speed than expected. It is attributed to that, LRM formulates 3D reconstruction as a naive images-to-3D translation problem, ignoring the strong 3D coherence among the input images. In this paper, we propose a Multi-view Large Reconstruction Model (M-LRM) designed to efficiently reconstruct high-quality 3D shapes from multi-views in a 3D-aware manner. Specifically, we introduce a multi-view consistent cross-attention scheme to enable M-LRM to accurately query information from the input images. Moreover, we employ the 3D priors of the input multi-view images to initialize the tri-plane tokens. Compared to LRM, the proposed M-LRM can produce a tri-plane NeRF with $128 \times 128$ resolution and generate 3D shapes of high fidelity. Experimental studies demonstrate that our model achieves a significant performance gain and faster training convergence than LRM. Project page: https://murphylmf.github.io/M-LRM/
RaDe-GS: Rasterizing Depth in Gaussian Splatting
Jun 03, 2024



Gaussian Splatting (GS) has proven to be highly effective in novel view synthesis, achieving high-quality and real-time rendering. However, its potential for reconstructing detailed 3D shapes has not been fully explored. Existing methods often suffer from limited shape accuracy due to the discrete and unstructured nature of Gaussian splats, which complicates the shape extraction. While recent techniques like 2D GS have attempted to improve shape reconstruction, they often reformulate the Gaussian primitives in ways that reduce both rendering quality and computational efficiency. To address these problems, our work introduces a rasterized approach to render the depth maps and surface normal maps of general 3D Gaussian splats. Our method not only significantly enhances shape reconstruction accuracy but also maintains the computational efficiency intrinsic to Gaussian Splatting. Our approach achieves a Chamfer distance error comparable to NeuraLangelo on the DTU dataset and similar training and rendering time as traditional Gaussian Splatting on the Tanks & Temples dataset. Our method is a significant advancement in Gaussian Splatting and can be directly integrated into existing Gaussian Splatting-based methods.