 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMo: Unified Sparse Motion Modeling for Real-Time Co-Speech Avatars
May 14, 2026Speech-driven gestures and facial animations are fundamental to expressive digital avatars in games, virtual production, and interactive media. However, existing methods are either limited to a single modality for audio motion alignment, failing to fully utilize the potential of massive human motion data, or are constrained by the representation ability and throughput of multimodal models, which makes it difficult to achieve high-quality motion generation or real-time performance. We present UMo, a unified sparse motion modeling architecture for real-time co-speech avatars, which processes text, audio, and motion tokens within a unified formulation. Leveraging a spatially sparse Mixture-of-Experts framework and a temporally sparse, keyframe-centric design, UMo efficiently performs real-time dense reconstruction, enabling temporally coherent and high-fidelity animation generation for both facial expressions and gestures. Furthermore, we implement a multi-stage training strategy with targeted audio augmentation to enhance acoustic diversity and semantic consistency. Consequently, UMo preserves fine-grained speech-motion alignment even under strict latency constraints. Extensive quantitative and qualitative evaluations show that UMo achieves better output quality under low latency and real-time performance constraints, offering a practical solution for high-fidelity real-time co-speech avatars.
InfiniteDance: Scalable 3D Dance Generation Towards in-the-wild Generalization
Mar 10, 2026Although existing 3D dance generation methods perform well in controlled scenarios, they often struggle to generalize in the wild. When conditioned on unseen music, existing methods often produce unstructured or physically implausible dance, largely due to limited music-to-dance data and restricted model capacity. This work aims to push the frontier of generalizable 3D dance generation by scaling up both data and model design. (1) On the data side, we develop a fully automated pipeline that reconstructs high-fidelity 3D dance motions from monocular videos. To eliminate the physical artifacts prevalent in existing reconstruction methods, we introduce a Foot Restoration Diffusion Model (FRDM) guided by foot-contact and geometric constraints that enforce physical plausibility while preserving kinematic smoothness and expressiveness, resulting in a diverse, high-quality multimodal 3D dance dataset totaling 100.69 hours. (2) On model design, we propose Choreographic LLaMA (ChoreoLLaMA), a scalable LLaMA-based architecture. To enhance robustness under unfamiliar music conditions, we integrate a retrieval-augmented generation (RAG) module that injects reference dance as a prompt. Additionally, we design a slow/fast-cadence Mixture-of-Experts (MoE) module that enables ChoreoLLaMA to smoothly adapt motion rhythms across varying music tempos. Extensive experiments across diverse dance genres show that our approach surpasses existing methods in both qualitative and quantitative evaluations, marking a step toward scalable, real-world 3D dance generation. Code, models, and data will be released.
BrepGaussian: CAD reconstruction from Multi-View Images with Gaussian Splatting
Feb 24, 2026The boundary representation (B-rep) models a 3D solid as its explicit boundaries: trimmed corners, edges, and faces. Recovering B-rep representation from unstructured data is a challenging and valuable task of computer vision and graphics. Recent advances in deep learning have greatly improved the recovery of 3D shape geometry, but still depend on dense and clean point clouds and struggle to generalize to novel shapes. We propose B-rep Gaussian Splatting (BrepGaussian), a novel framework that learns 3D parametric representations from 2D images. We employ a Gaussian Splatting renderer with learnable features, followed by a specific fitting strategy. To disentangle geometry reconstruction and feature learning, we introduce a two-stage learning framework that first captures geometry and edges and then refines patch features to achieve clean geometry and coherent instance representations. Extensive experiments demonstrate the superior performance of our approach to state-of-the-art methods. We will release our code and datasets upon acceptance.
SPIRIT: Adapting Vision Foundation Models for Unified Single- and Multi-Frame Infrared Small Target Detection
Feb 02, 2026Infrared small target detection (IRSTD) is crucial for surveillance and early-warning, with deployments spanning both single-frame analysis and video-mode tracking. A practical solution should leverage vision foundation models (VFMs) to mitigate infrared data scarcity, while adopting a memory-attention-based temporal propagation framework that unifies single- and multi-frame inference. However, infrared small targets exhibit weak radiometric signals and limited semantic cues, which differ markedly from visible-spectrum imagery. This modality gap makes direct use of semantics-oriented VFMs and appearance-driven cross-frame association unreliable for IRSTD: hierarchical feature aggregation can submerge localized target peaks, and appearance-only memory attention becomes ambiguous, leading to spurious clutter associations. To address these challenges, we propose SPIRIT, a unified and VFM-compatible framework that adapts VFMs to IRSTD via lightweight physics-informed plug-ins. Spatially, PIFR refines features by approximating rank-sparsity decomposition to suppress structured background components and enhance sparse target-like signals. Temporally, PGMA injects history-derived soft spatial priors into memory cross-attention to constrain cross-frame association, enabling robust video detection while naturally reverting to single-frame inference when temporal context is absent. Experiments on multiple IRSTD benchmarks show consistent gains over VFM-based baselines and SOTA performance.
Combinatorial Bandit Bayesian Optimization for Tensor Outputs
Jan 31, 2026Bayesian optimization (BO) has been widely used to optimize expensive and black-box functions across various domains. Existing BO methods have not addressed tensor-output functions. To fill this gap, we propose a novel tensor-output BO method. Specifically, we first introduce a tensor-output Gaussian process (TOGP) with two classes of tensor-output kernels as a surrogate model of the tensor-output function, which can effectively capture the structural dependencies within the tensor. Based on it, we develop an upper confidence bound (UCB) acquisition function to select the queried points. Furthermore, we introduce a more complex and practical problem setting, named combinatorial bandit Bayesian optimization (CBBO), where only a subset of the outputs can be selected to contribute to the objective function. To tackle this, we propose a tensor-output CBBO method, which extends TOGP to handle partially observed outputs, and accordingly design a novel combinatorial multi-arm bandit-UCB2 (CMAB-UCB2) criterion to sequentially select both the queried points and the optimal output subset. Theoretical regret bounds for the two methods are established, ensuring their sublinear performance. Extensive synthetic and real-world experiments demonstrate their superiority.
GeoDiff3D: Self-Supervised 3D Scene Generation with Geometry-Constrained 2D Diffusion Guidance
Jan 28, 20263D scene generation is a core technology for gaming, film/VFX, and VR/AR. Growing demand for rapid iteration, high-fidelity detail, and accessible content creation has further increased interest in this area. Existing methods broadly follow two paradigms - indirect 2D-to-3D reconstruction and direct 3D generation - but both are limited by weak structural modeling and heavy reliance on large-scale ground-truth supervision, often producing structural artifacts, geometric inconsistencies, and degraded high-frequency details in complex scenes. We propose GeoDiff3D, an efficient self-supervised framework that uses coarse geometry as a structural anchor and a geometry-constrained 2D diffusion model to provide texture-rich reference images. Importantly, GeoDiff3D does not require strict multi-view consistency of the diffusion-generated references and remains robust to the resulting noisy, inconsistent guidance. We further introduce voxel-aligned 3D feature aggregation and dual self-supervision to maintain scene coherence and fine details while substantially reducing dependence on labeled data. GeoDiff3D also trains with low computational cost and enables fast, high-quality 3D scene generation. Extensive experiments on challenging scenes show improved generalization and generation quality over existing baselines, offering a practical solution for accessible and efficient 3D scene construction.
Flatten The Complex: Joint B-Rep Generation via Compositional $k$-Cell Particles
Jan 25, 2026Boundary Representation (B-Rep) is the widely adopted standard in Computer-Aided Design (CAD) and manufacturing. However, generative modeling of B-Reps remains a formidable challenge due to their inherent heterogeneity as geometric cell complexes, which entangles topology with geometry across cells of varying orders (i.e., $k$-cells such as vertices, edges, faces). Previous methods typically rely on cascaded sequences to handle this hierarchy, which fails to fully exploit the geometric relationships between cells, such as adjacency and sharing, limiting context awareness and error recovery. To fill this gap, we introduce a novel paradigm that reformulates B-Reps into sets of compositional $k$-cell particles. Our approach encodes each topological entity as a composition of particles, where adjacent cells share identical latents at their interfaces, thereby promoting geometric coupling along shared boundaries. By decoupling the rigid hierarchy, our representation unifies vertices, edges, and faces, enabling the joint generation of topology and geometry with global context awareness. We synthesize these particle sets using a multi-modal flow matching framework to handle unconditional generation as well as precise conditional tasks, such as 3D reconstruction from single-view or point cloud. Furthermore, the explicit and localized nature of our representation naturally extends to downstream tasks like local in-painting and enables the direct synthesis of non-manifold structures (e.g., wireframes). Extensive experiments demonstrate that our method produces high-fidelity CAD models with superior validity and editability compared to state-of-the-art methods.
IGDMRec: Behavior Conditioned Item Graph Diffusion for Multimodal Recommendation
Dec 23, 2025



Multimodal recommender systems (MRSs) are critical for various online platforms, offering users more accurate personalized recommendations by incorporating multimodal information of items. Structure-based MRSs have achieved state-of-the-art performance by constructing semantic item graphs, which explicitly model relationships between items based on modality feature similarity. However, such semantic item graphs are often noisy due to 1) inherent noise in multimodal information and 2) misalignment between item semantics and user-item co-occurrence relationships, which introduces false links and leads to suboptimal recommendations. To address this challenge, we propose Item Graph Diffusion for Multimodal Recommendation (IGDMRec), a novel method that leverages a diffusion model with classifier-free guidance to denoise the semantic item graph by integrating user behavioral information. Specifically, IGDMRec introduces a Behavior-conditioned Graph Diffusion (BGD) module, incorporating interaction data as conditioning information to guide the denoising of the semantic item graph. Additionally, a Conditional Denoising Network (CD-Net) is designed to implement the denoising process with manageable complexity. Finally, we propose a contrastive representation augmentation scheme that leverages both the denoised item graph and the original item graph to enhance item representations. \LL{Extensive experiments on four real-world datasets demonstrate the superiority of IGDMRec over competitive baselines, with robustness analysis validating its denoising capability and ablation studies verifying the effectiveness of its key components.
LoG3D: Ultra-High-Resolution 3D Shape Modeling via Local-to-Global Partitioning
Nov 18, 2025



Generating high-fidelity 3D contents remains a fundamental challenge due to the complexity of representing arbitrary topologies-such as open surfaces and intricate internal structures-while preserving geometric details. Prevailing methods based on signed distance fields (SDFs) are hampered by costly watertight preprocessing and struggle with non-manifold geometries, while point-cloud representations often suffer from sampling artifacts and surface discontinuities. To overcome these limitations, we propose a novel 3D variational autoencoder (VAE) framework built upon unsigned distance fields (UDFs)-a more robust and computationally efficient representation that naturally handles complex and incomplete shapes. Our core innovation is a local-to-global (LoG) architecture that processes the UDF by partitioning it into uniform subvolumes, termed UBlocks. This architecture couples 3D convolutions for capturing local detail with sparse transformers for enforcing global coherence. A Pad-Average strategy further ensures smooth transitions at subvolume boundaries during reconstruction. This modular design enables seamless scaling to ultra-high resolutions up to $2048^3$-a regime previously unattainable for 3D VAEs. Experiments demonstrate state-of-the-art performance in both reconstruction accuracy and generative quality, yielding superior surface smoothness and geometric flexibility.
StableIntrinsic: Detail-preserving One-step Diffusion Model for Multi-view Material Estimation
Aug 27, 2025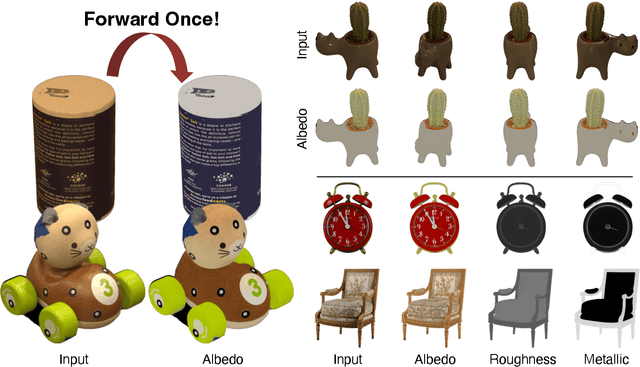



Recovering material information from images has been extensively studied in computer graphics and vision. Recent works in material estimation leverage diffusion model showing promising results. However, these diffusion-based methods adopt a multi-step denoising strategy, which is time-consuming for each estimation. Such stochastic inference also conflicts with the deterministic material estimation task, leading to a high variance estimated results. In this paper, we introduce StableIntrinsic, a one-step diffusion model for multi-view material estimation that can produce high-quality material parameters with low variance. To address the overly-smoothing problem in one-step diffusion, StableIntrinsic applies losses in pixel space, with each loss designed based on the properties of the material. Additionally, StableIntrinsic introduces a Detail Injection Network (DIN) to eliminate the detail loss caused by VAE encoding, while further enhancing the sharpness of material prediction results. The experimental results indicate that our method surpasses the current state-of-the-art techniques by achieving a $9.9\%$ improvement in the Peak Signal-to-Noise Ratio (PSNR) of albedo, and by reducing the Mean Square Error (MSE) for metallic and roughness by $44.4\%$ and $60.0\%$, respectively.