 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeaveRec: An LLM-Based Cross-Domain Sequential Recommendation Framework with Model Merging
Oct 30, 2025



Cross-Domain Sequential Recommendation (CDSR) seeks to improve user preference modeling by transferring knowledge from multiple domains. Despite the progress made in CDSR, most existing methods rely on overlapping users or items to establish cross-domain correlations-a requirement that rarely holds in real-world settings. The advent of large language models (LLM) and model-merging techniques appears to overcome this limitation by unifying multi-domain data without explicit overlaps. Yet, our empirical study shows that naively training an LLM on combined domains-or simply merging several domain-specific LLMs-often degrades performance relative to a model trained solely on the target domain. To address these challenges, we first experimentally investigate the cause of suboptimal performance in LLM-based cross-domain recommendation and model merging. Building on these insights, we introduce WeaveRec, which cross-trains multiple LoRA modules with source and target domain data in a weaving fashion, and fuses them via model merging. WeaveRec can be extended to multi-source domain scenarios and notably does not introduce additional inference-time cost in terms of latency or memory. Furthermore, we provide a theoretical guarantee that WeaveRec can reduce the upper bound of the expected error in the target domain. Extensive experiments on single-source, multi-source, and cross-platform cross-domain recommendation scenarios validate that WeaveRec effectively mitigates performance degradation and consistently outperforms baseline approaches in real-world recommendation tasks.
Bidirectional Mammogram View Translation with Column-Aware and Implicit 3D Conditional Diffusion
Oct 06, 2025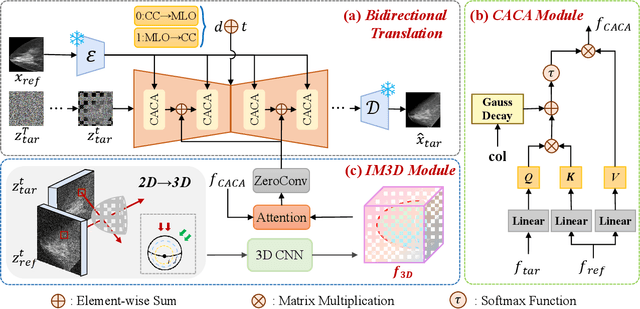
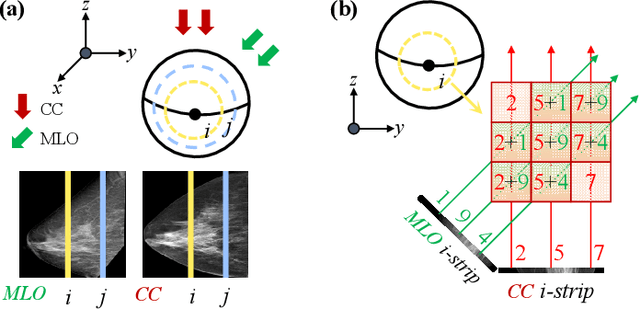
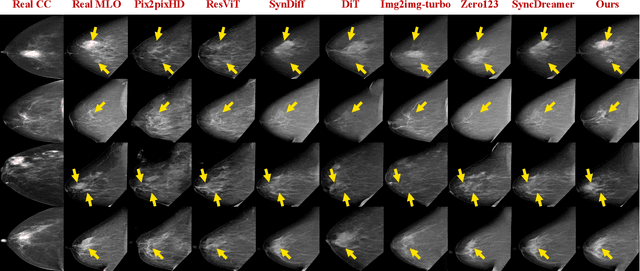
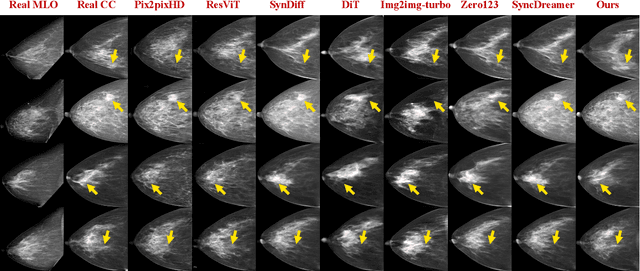
Dual-view mammography, including craniocaudal (CC) and mediolateral oblique (MLO) projections, offers complementary anatomical views crucial for breast cancer diagnosis. However, in real-world clinical workflows, one view may be missing, corrupted, or degraded due to acquisition errors or compression artifacts, limiting the effectiveness of downstream analysis. View-to-view translation can help recover missing views and improve lesion alignment. Unlike natural images, this task in mammography is highly challenging due to large non-rigid deformations and severe tissue overlap in X-ray projections, which obscure pixel-level correspondences. In this paper, we propose Column-Aware and Implicit 3D Diffusion (CA3D-Diff), a novel bidirectional mammogram view translation framework based on conditional diffusion model. To address cross-view structural misalignment, we first design a column-aware cross-attention mechanism that leverages the geometric property that anatomically corresponding regions tend to lie in similar column positions across views. A Gaussian-decayed bias is applied to emphasize local column-wise correlations while suppressing distant mismatches. Furthermore, we introduce an implicit 3D structure reconstruction module that back-projects noisy 2D latents into a coarse 3D feature volume based on breast-view projection geometry. The reconstructed 3D structure is refined and injected into the denoising UNet to guide cross-view generation with enhanced anatomical awareness. Extensive experiments demonstrate that CA3D-Diff achieves superior performance in bidirectional tasks, outperforming state-of-the-art methods in visual fidelity and structural consistency. Furthermore, the synthesized views effectively improve single-view malignancy classification in screening settings, demonstrating the practical value of our method in real-world diagnostics.
Wavelet Predictive Representations for Non-Stationary Reinforcement Learning
Oct 06, 2025The real world is inherently non-stationary, with ever-changing factors, such as weather conditions and traffic flows, making it challenging for agents to adapt to varying environmental dynamics. Non-Stationary Reinforcement Learning (NSRL) addresses this challenge by training agents to adapt rapidly to sequences of distinct Markov Decision Processes (MDPs). However, existing NSRL approaches often focus on tasks with regularly evolving patterns, leading to limited adaptability in highly dynamic settings. Inspired by the success of Wavelet analysis in time series modeling, specifically its ability to capture signal trends at multiple scales, we propose WISDOM to leverage wavelet-domain predictive task representations to enhance NSRL. WISDOM captures these multi-scale features in evolving MDP sequences by transforming task representation sequences into the wavelet domain, where wavelet coefficients represent both global trends and fine-grained variations of non-stationary changes. In addition to the auto-regressive modeling commonly employed in time series forecasting, we devise a wavelet temporal difference (TD) update operator to enhance tracking and prediction of MDP evolution. We theoretically prove the convergence of this operator and demonstrate policy improvement with wavelet task representations. Experiments on diverse benchmarks show that WISDOM significantly outperforms existing baselines in both sample efficiency and asymptotic performance, demonstrating its remarkable adaptability in complex environments characterized by non-stationary and stochastically evolving tasks.
From Seeing to Predicting: A Vision-Language Framework for Trajectory Forecasting and Controlled Video Generation
Oct 01, 2025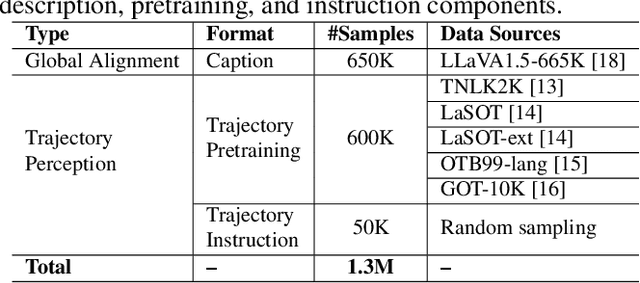
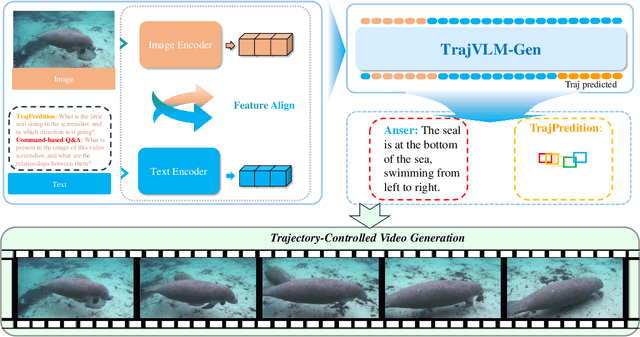


Current video generation models produce physically inconsistent motion that violates real-world dynamics. We propose TrajVLM-Gen, a two-stage framework for physics-aware image-to-video generation. First, we employ a Vision Language Model to predict coarse-grained motion trajectories that maintain consistency with real-world physics. Second, these trajectories guide video generation through attention-based mechanisms for fine-grained motion refinement. We build a trajectory prediction dataset based on video tracking data with realistic motion patterns. Experiments on UCF-101 and MSR-VTT demonstrate that TrajVLM-Gen outperforms existing methods, achieving competitive FVD scores of 545 on UCF-101 and 539 on MSR-VTT.
RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation
Sep 18, 2025This paper presents RynnVLA-001, a vision-language-action(VLA) model built upon large-scale video generative pretraining from human demonstrations. We propose a novel two-stage pretraining methodology. The first stage, Ego-Centric Video Generative Pretraining, trains an Image-to-Video model on 12M ego-centric manipulation videos to predict future frames conditioned on an initial frame and a language instruction. The second stage, Human-Centric Trajectory-Aware Modeling, extends this by jointly predicting future keypoint trajectories, thereby effectively bridging visual frame prediction with action prediction. Furthermore, to enhance action representation, we propose ActionVAE, a variational autoencoder that compresses sequences of actions into compact latent embeddings, reducing the complexity of the VLA output space. When finetuned on the same downstream robotics datasets, RynnVLA-001 achieves superior performance over state-of-the-art baselines, demonstrating that the proposed pretraining strategy provides a more effective initialization for VLA models.
SPGen: Spherical Projection as Consistent and Flexible Representation for Single Image 3D Shape Generation
Sep 16, 2025



Existing single-view 3D generative models typically adopt multiview diffusion priors to reconstruct object surfaces, yet they remain prone to inter-view inconsistencies and are unable to faithfully represent complex internal structure or nontrivial topologies. In particular, we encode geometry information by projecting it onto a bounding sphere and unwrapping it into a compact and structural multi-layer 2D Spherical Projection (SP) representation. Operating solely in the image domain, SPGen offers three key advantages simultaneously: (1) Consistency. The injective SP mapping encodes surface geometry with a single viewpoint which naturally eliminates view inconsistency and ambiguity; (2) Flexibility. Multi-layer SP maps represent nested internal structures and support direct lifting to watertight or open 3D surfaces; (3) Efficiency. The image-domain formulation allows the direct inheritance of powerful 2D diffusion priors and enables efficient finetuning with limited computational resources. Extensive experiments demonstrate that SPGen significantly outperforms existing baselines in geometric quality and computational efficiency.
Black-box Model Merging for Language-Model-as-a-Service with Massive Model Repositories
Sep 16, 2025



Model merging refers to the process of integrating multiple distinct models into a unified model that preserves and combines the strengths and capabilities of the individual models. Most existing approaches rely on task vectors to combine models, typically under the assumption that model parameters are accessible. However, for extremely large language models (LLMs) such as GPT-4, which are often provided solely as black-box services through API interfaces (Language-Model-as-a-Service), model weights are not available to end users. This presents a significant challenge, which we refer to as black-box model merging (BMM) with massive LLMs. To address this challenge, we propose a derivative-free optimization framework based on the evolutionary algorithm (Evo-Merging) that enables effective model merging using only inference-time API queries. Our method consists of two key components: (1) sparsity-based denoising, designed to identify and filter out irrelevant or redundant information across models, and (2) sign-aware scaling, which dynamically computes optimal combination weights for the relevant models based on their performance. We also provide a formal justification, along with a theoretical analysis, for our asymmetric sparsification. Extensive experimental evaluations demonstrate that our approach achieves state-of-the-art results on a range of tasks, significantly outperforming existing strong baselines.
Forget What's Sensitive, Remember What Matters: Token-Level Differential Privacy in Memory Sculpting for Continual Learning
Sep 16, 2025



Continual Learning (CL) models, while adept at sequential knowledge acquisition, face significant and often overlooked privacy challenges due to accumulating diverse information. Traditional privacy methods, like a uniform Differential Privacy (DP) budget, indiscriminately protect all data, leading to substantial model utility degradation and hindering CL deployment in privacy-sensitive areas. To overcome this, we propose a privacy-enhanced continual learning (PeCL) framework that forgets what's sensitive and remembers what matters. Our approach first introduces a token-level dynamic Differential Privacy strategy that adaptively allocates privacy budgets based on the semantic sensitivity of individual tokens. This ensures robust protection for private entities while minimizing noise injection for non-sensitive, general knowledge. Second, we integrate a privacy-guided memory sculpting module. This module leverages the sensitivity analysis from our dynamic DP mechanism to intelligently forget sensitive information from the model's memory and parameters, while explicitly preserving the task-invariant historical knowledge crucial for mitigating catastrophic forgetting. Extensive experiments show that PeCL achieves a superior balance between privacy preserving and model utility, outperforming baseline models by maintaining high accuracy on previous tasks while ensuring robust privacy.
When Inverse Data Outperforms: Exploring the Pitfalls of Mixed Data in Multi-Stage Fine-Tuning
Sep 16, 2025Existing work has shown that o1-level performance can be achieved with limited data distillation, but most existing methods focus on unidirectional supervised fine-tuning (SFT), overlooking the intricate interplay between diverse reasoning patterns. In this paper, we construct r1k, a high-quality reverse reasoning dataset derived by inverting 1,000 forward examples from s1k, and examine how SFT and Direct Preference Optimization (DPO) affect alignment under bidirectional reasoning objectives. SFT on r1k yields a 1.6%--6.8% accuracy improvement over s1k across evaluated benchmarks. However, naively mixing forward and reverse data during SFT weakens the directional distinction. Although DPO can partially recover this distinction, it also suppresses less preferred reasoning paths by shifting the probability mass toward irrelevant outputs. These findings suggest that mixed reasoning data introduce conflicting supervision signals, underscoring the need for robust and direction-aware alignment strategies.
PRIM: Towards Practical In-Image Multilingual Machine Translation
Sep 05, 2025



In-Image Machine Translation (IIMT) aims to translate images containing texts from one language to another. Current research of end-to-end IIMT mainly conducts on synthetic data, with simple background, single font, fixed text position, and bilingual translation, which can not fully reflect real world, causing a significant gap between the research and practical conditions. To facilitate research of IIMT in real-world scenarios, we explore Practical In-Image Multilingual Machine Translation (IIMMT). In order to convince the lack of publicly available data, we annotate the PRIM dataset, which contains real-world captured one-line text images with complex background, various fonts, diverse text positions, and supports multilingual translation directions. We propose an end-to-end model VisTrans to handle the challenge of practical conditions in PRIM, which processes visual text and background information in the image separately, ensuring the capability of multilingual translation while improving the visual quality. Experimental results indicate the VisTrans achieves a better translation quality and visual effect compared to other models. The code and dataset are available at: https://github.com/BITHLP/PRIM.