 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDV-SFT: Direct Vision Supervision for Fine-Grained Visual Understanding
May 26, 2026Multimodal large language models are typically trained end-to-end to predict ground-truth answers, yet supervision signals are applied exclusively to text tokens. Visual tokens, the core carriers of visual information, are optimized only implicitly as part of the context, leading to coarse-grained visual understanding. Prior works attempt to supervise visual inputs but inevitably rely on auxiliary components such as additional decoders or forward passes, because visual tokens lack readily interpretable labels. This limits their practical applicability. In this work, we propose \textbf{D}irect \textbf{V}ision \textbf{S}upervised \textbf{F}ine-\textbf{T}uning (DV-SFT), which constructs explicit, token-level supervision for visual tokens and trains them through the same next-token prediction objective used for text. Specifically, we exploit the direct vision--text correspondence in OCR-related scenarios and automatically label each visual token with the word in its corresponding image patch. DV-SFT treats the MLLM as a black box, requiring no architectural modifications or additional forward passes. Extensive experiments demonstrate the superiority of direct vision supervision. DV-SFT consistently outperforms standard SFT across three in-domain and four out-of-domain benchmarks. Further analyses show that vision supervision effectively enhances fine-grained visual understanding and achieves higher multimodal alignment efficiency.
Pardon? Evaluating Conversational Repair in Large Audio-Language Models
Jan 19, 2026Large Audio-Language Models (LALMs) have demonstrated strong performance in spoken question answering (QA), with existing evaluations primarily focusing on answer accuracy and robustness to acoustic perturbations. However, such evaluations implicitly assume that spoken inputs remain semantically answerable, an assumption that often fails in real-world interaction when essential information is missing. In this work, we introduce a repair-aware evaluation setting that explicitly distinguishes between answerable and unanswerable audio inputs. We define answerability as a property of the input itself and construct paired evaluation conditions using a semantic-acoustic masking protocol. Based on this setting, we propose the Evaluability Awareness and Repair (EAR) score, a non-compensatory metric that jointly evaluates task competence under answerable conditions and repair behavior under unanswerable conditions. Experiments on two spoken QA benchmarks across diverse LALMs reveal a consistent gap between answer accuracy and conversational reliability: while many models perform well when inputs are answerable, most fail to recognize semantic unanswerability and initiate appropriate conversational repair. These findings expose a limitation of prevailing accuracy-centric evaluation practices and motivate reliability assessments that treat unanswerable inputs as cues for repair and continued interaction.
Equipping Retrieval-Augmented Large Language Models with Document Structure Awareness
Oct 05, 2025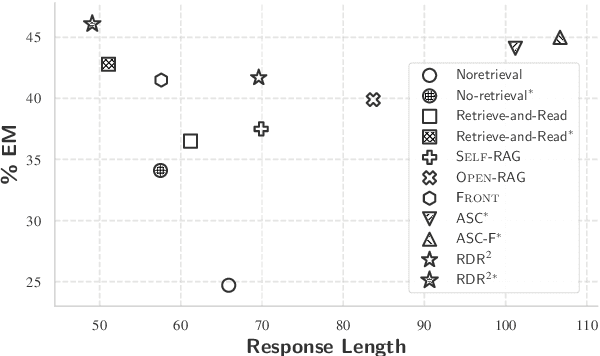
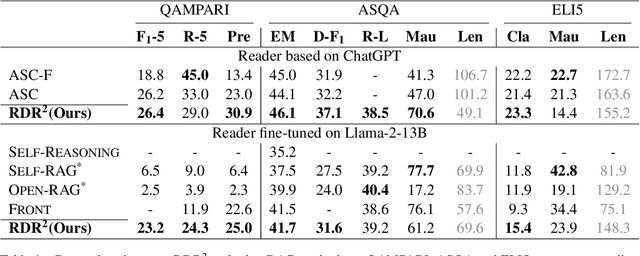
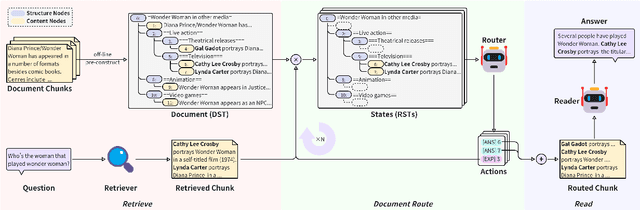
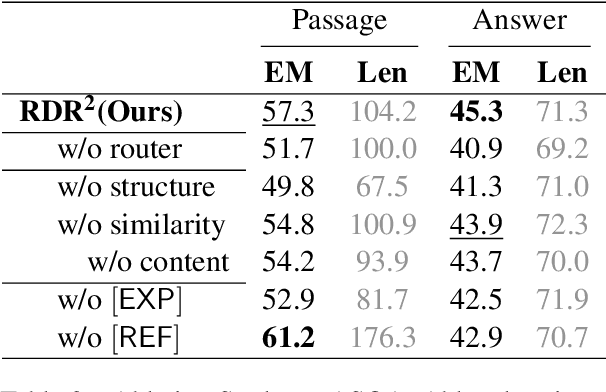
While large language models (LLMs) demonstrate impressive capabilities, their reliance on parametric knowledge often leads to factual inaccuracies. Retrieval-Augmented Generation (RAG) mitigates this by leveraging external documents, yet existing approaches treat retrieved passages as isolated chunks, ignoring valuable structure that is crucial for document organization. Motivated by this gap, we propose Retrieve-DocumentRoute-Read (RDR2), a novel framework that explicitly incorporates structural information throughout the RAG process. RDR2 employs an LLM-based router to dynamically navigate document structure trees, jointly evaluating content relevance and hierarchical relationships to assemble optimal evidence. Our key innovation lies in formulating document routing as a trainable task, with automatic action curation and structure-aware passage selection inspired by human reading strategies. Through comprehensive evaluation on five challenging datasets, RDR2 achieves state-of-the-art performance, demonstrating that explicit structural awareness significantly enhances RAG systems' ability to acquire and utilize knowledge, particularly in complex scenarios requiring multi-document synthesis.
Cross-Layer Vision Smoothing: Enhancing Visual Understanding via Sustained Focus on Key Objects in Large Vision-Language Models
Sep 16, 2025Large Vision-Language Models (LVLMs) can accurately locate key objects in images, yet their attention to these objects tends to be very brief. Motivated by the hypothesis that sustained focus on key objects can improve LVLMs' visual capabilities, we propose Cross-Layer Vision Smoothing (CLVS). The core idea of CLVS is to incorporate a vision memory that smooths the attention distribution across layers. Specifically, we initialize this vision memory with position-unbiased visual attention in the first layer. In subsequent layers, the model's visual attention jointly considers the vision memory from previous layers, while the memory is updated iteratively, thereby maintaining smooth attention on key objects. Given that visual understanding primarily occurs in the early and middle layers of the model, we use uncertainty as an indicator of completed visual understanding and terminate the smoothing process accordingly. Experiments on four benchmarks across three LVLMs confirm the effectiveness and generalizability of our method. CLVS achieves state-of-the-art performance on a variety of visual understanding tasks, with particularly significant improvements in relation and attribute understanding.
PRIM: Towards Practical In-Image Multilingual Machine Translation
Sep 05, 2025



In-Image Machine Translation (IIMT) aims to translate images containing texts from one language to another. Current research of end-to-end IIMT mainly conducts on synthetic data, with simple background, single font, fixed text position, and bilingual translation, which can not fully reflect real world, causing a significant gap between the research and practical conditions. To facilitate research of IIMT in real-world scenarios, we explore Practical In-Image Multilingual Machine Translation (IIMMT). In order to convince the lack of publicly available data, we annotate the PRIM dataset, which contains real-world captured one-line text images with complex background, various fonts, diverse text positions, and supports multilingual translation directions. We propose an end-to-end model VisTrans to handle the challenge of practical conditions in PRIM, which processes visual text and background information in the image separately, ensuring the capability of multilingual translation while improving the visual quality. Experimental results indicate the VisTrans achieves a better translation quality and visual effect compared to other models. The code and dataset are available at: https://github.com/BITHLP/PRIM.
DocMEdit: Towards Document-Level Model Editing
May 26, 2025Model editing aims to correct errors and outdated knowledge in the Large language models (LLMs) with minimal cost. Prior research has proposed a variety of datasets to assess the effectiveness of these model editing methods. However, most existing datasets only require models to output short phrases or sentences, overlooks the widespread existence of document-level tasks in the real world, raising doubts about their practical usability. Aimed at addressing this limitation and promoting the application of model editing in real-world scenarios, we propose the task of document-level model editing. To tackle such challenges and enhance model capabilities in practical settings, we introduce \benchmarkname, a dataset focused on document-level model editing, characterized by document-level inputs and outputs, extrapolative, and multiple facts within a single edit. We propose a series of evaluation metrics and experiments. The results show that the difficulties in document-level model editing pose challenges for existing model editing methods.
Aligning Attention Distribution to Information Flow for Hallucination Mitigation in Large Vision-Language Models
May 20, 2025



Due to the unidirectional masking mechanism, Decoder-Only models propagate information from left to right. LVLMs (Large Vision-Language Models) follow the same architecture, with visual information gradually integrated into semantic representations during forward propagation. Through systematic analysis, we observe that over 80\% of the visual information is absorbed into the semantic representations. However, the model's attention still predominantly focuses on the visual representations. This misalignment between the attention distribution and the actual information flow undermines the model's visual understanding ability and contributes to hallucinations. To address this issue, we enhance the model's visual understanding by leveraging the core information embedded in semantic representations. Specifically, we identify attention heads that focus on core semantic representations based on their attention distributions. Then, through a two-stage optimization paradigm, we propagate the advantages of these attention heads across the entire model, aligning the attention distribution with the actual information flow. We evaluate our method on three image captioning benchmarks using five different LVLMs, demonstrating its effectiveness in significantly reducing hallucinations. Further experiments reveal a trade-off between reduced hallucinations and richer details. Notably, our method allows for manual adjustment of the model's conservativeness, enabling flexible control to meet diverse real-world requirements. Code will be released once accepted.
Mitigate Language Priors in Large Vision-Language Models by Cross-Images Contrastive Decoding
May 19, 2025Language priors are a major cause of hallucinations in Large Vision-Language Models (LVLMs), often leading to text that is linguistically plausible but visually inconsistent. Recent work explores contrastive decoding as a training-free solution, but these methods typically construct negative visual contexts from the original image, resulting in visual information loss and distorted distribution. Motivated by the observation that language priors stem from the LLM backbone and remain consistent across images, we propose Cross-Images Contrastive Decoding (CICD), a simple yet effective training-free method that uses different images to construct negative visual contexts. We further analyze the cross-image behavior of language priors and introduce a distinction between essential priors (supporting fluency) and detrimental priors (causing hallucinations), enabling selective suppression. By selectively preserving essential priors and suppressing detrimental ones, our method reduces hallucinations while maintaining coherent and fluent language generation. Experiments on four benchmarks and six LVLMs across three model families confirm the effectiveness and generalizability of CICD, especially in image captioning, where language priors are particularly pronounced. Code will be released upon acceptance.
PSPO*: An Effective Process-supervised Policy Optimization for Reasoning Alignment
Nov 18, 2024



Process supervision enhances the performance of large language models in reasoning tasks by providing feedback at each step of chain-of-thought reasoning. However, due to the lack of effective process supervision methods, even advanced large language models are prone to logical errors and redundant reasoning. We claim that the effectiveness of process supervision significantly depends on both the accuracy and the length of reasoning chains. Moreover, we identify that these factors exhibit a nonlinear relationship with the overall reward score of the reasoning process. Inspired by these insights, we propose a novel process supervision paradigm, PSPO*, which systematically outlines the workflow from reward model training to policy optimization, and highlights the importance of nonlinear rewards in process supervision. Based on PSPO*, we develop the PSPO-WRS, which considers the number of reasoning steps in determining reward scores and utilizes an adjusted Weibull distribution for nonlinear reward shaping. Experimental results on six mathematical reasoning datasets demonstrate that PSPO-WRS consistently outperforms current mainstream models.
METEOR: Evolutionary Journey of Large Language Models from Guidance to Self-Growth
Nov 18, 2024Model evolution enables learning from feedback to refine experiences and update skills, transforming models from having no domain knowledge to becoming domain experts. However, there is currently no unified and effective method for guiding this evolutionary process. To address this gap, we propose the Meteor method, which includes three training phases: weak-to-strong data distillation, iterative training, and self-evolution strategies. Each phase maximizes the model's inherent domain capabilities, allowing it to autonomously refine its domain knowledge and enhance performance. Experiments demonstrate that our approach significantly improves accuracy, completeness, relevance, coherence, and reliability across domain-specific tasks.