 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnything2Skill: Compiling External Knowledge into Reusable Skills for Agents
Jun 09, 2026Retrieval-augmented generation (RAG) enables agents to access external knowledge at inference time, but it primarily retrieves fragmented declarative evidence, leaving agents to repeatedly infer task procedures from passages, manuals, examples, logs, or trajectories. This raises a fundamental question: can skills extracted from external knowledge bases be installed into an agent, enabling it to rapidly approximate domain expertise? In this paper, we propose Anything2Skill, a taxonomy-guided framework that compiles heterogeneous external knowledge into reusable, retrievable, and executable skills for agents. Given a corpus of knowledge records, \textsc{Anything2Skill} first decomposes each record into evidence windows and performs plan-and-expand skill extraction under a skill-tree prior. The extracted candidates are then converted into structured skill contracts that specify invocation conditions, contraindications, action moves, workflow steps, constraints, output specifications, supporting evidence, and confidence scores. To construct a deployable procedural memory, Anything2Skill manages the extracted skills in a persistent SkillBank through taxonomy-aware compilation, registry-level reconciliation, lifecycle tracking, versioned updates, and visible skill-tree projection. At inference time, agents retrieve both task-specific passages from the original knowledge base and relevant procedural skills from the SkillBank, allowing RAG to provide declarative evidence while compiled skills provide reusable procedural guidance. Experiments on qsv and GitHub-CLI show that Anything2Skill combined with RAG achieves 98.85\% and 94.10\% success rates, respectively, substantially outperforming RAG-only agents. These results suggest that compiling latent procedural knowledge into explicit skills is an effective way to extend retrieval-augmented agents from knowledge access toward capability reuse.
Learning While Acting: A Skill-Enhanced Test-Time Co-Evolution Framework for Online Lifelong Learning Agents
Jun 03, 2026Lifelong learning is essential for Large Language Model (LLM) agents operating in dynamic, interactive environments. However, existing lifelong learning agents for long-horizon tasks typically depend on discrete skill or past experiences retrieval with static parameters during inference, which prevents them from continuously internalizing test-time feedback like human learners. To bridge this gap, we propose Skill-enhanced Test-Time Co-Evolution (\texttt{LifeSkill}), a two-stage reinforcement learning framework for Online Lifelong Learning Agents. Specifically, we design Verifier-Guided Skill Learning that addresses the lack of direct supervision for skill extraction by rewarding candidate skills according to the average verifier success of multiple skill-conditioned policy rollouts, encouraging the model to generate skills that are useful for solving tasks rather than merely plausible in text. Furthermore, we introduce Online Skill Internalization, which continuously improves the policy model during test-time interaction by transforming skill-conditioned trajectories into reward signals. This enables the agent to directly internalize reasoning capabilities into its parameters, avoiding the context bloat of experience retrieval. Experiments on LifelongAgentBench show that LifeSkill improves average performance by 7 absolute points by comparing with existing lifelong agent baselines.
PsychAgent: An Experience-Driven Lifelong Learning Agent for Self-Evolving Psychological Counselor
Apr 02, 2026Existing methods for AI psychological counselors predominantly rely on supervised fine-tuning using static dialogue datasets. However, this contrasts with human experts, who continuously refine their proficiency through clinical practice and accumulated experience. To bridge this gap, we propose an Experience-Driven Lifelong Learning Agent (\texttt{PsychAgent}) for psychological counseling. First, we establish a Memory-Augmented Planning Engine tailored for longitudinal multi-session interactions, which ensures therapeutic continuity through persistent memory and strategic planning. Second, to support self-evolution, we design a Skill Evolution Engine that extracts new practice-grounded skills from historical counseling trajectories. Finally, we introduce a Reinforced Internalization Engine that integrates the evolved skills into the model via rejection fine-tuning, aiming to improve performance across diverse scenarios. Comparative analysis shows that our approach achieves higher scores than strong general LLMs (e.g., GPT-5.4, Gemini-3) and domain-specific baselines across all reported evaluation dimensions. These results suggest that lifelong learning can improve the consistency and overall quality of multi-session counseling responses.
AutoSkill: Experience-Driven Lifelong Learning via Skill Self-Evolution
Mar 05, 2026In practical LLM applications, users repeatedly express stable preferences and requirements, such as reducing hallucinations, following institutional writing conventions, or avoiding overly technical wording, yet such interaction experience is seldom consolidated into reusable knowledge. Consequently, LLM agents often fail to accumulate personalized capabilities across sessions. We present AutoSkill, an experience-driven lifelong learning framework that enables LLM agents to automatically derive, maintain, and reuse skills from dialogue and interaction traces. AutoSkill abstracts skills from user experience, supports their continual self-evolution, and dynamically injects relevant skills into future requests without retraining the underlying model. Designed as a model-agnostic plugin layer, it is compatible with existing LLMs and introduces a standardized skill representation for sharing and transfer across agents, users, and tasks. In this way, AutoSkill turns ephemeral interaction experience into explicit, reusable, and composable capabilities. This paper describes the motivation, architecture, skill lifecycle, and implementation of AutoSkill, and positions it with respect to prior work on memory, retrieval, personalization, and agentic systems. AutoSkill highlights a practical and scalable path toward lifelong personalized agents and personal digital surrogates.
PsychEval: A Multi-Session and Multi-Therapy Benchmark for High-Realism AI Psychological Counselor
Jan 08, 2026To develop a reliable AI for psychological assessment, we introduce \texttt{PsychEval}, a multi-session, multi-therapy, and highly realistic benchmark designed to address three key challenges: \textbf{1) Can we train a highly realistic AI counselor?} Realistic counseling is a longitudinal task requiring sustained memory and dynamic goal tracking. We propose a multi-session benchmark (spanning 6-10 sessions across three distinct stages) that demands critical capabilities such as memory continuity, adaptive reasoning, and longitudinal planning. The dataset is annotated with extensive professional skills, comprising over 677 meta-skills and 4577 atomic skills. \textbf{2) How to train a multi-therapy AI counselor?} While existing models often focus on a single therapy, complex cases frequently require flexible strategies among various therapies. We construct a diverse dataset covering five therapeutic modalities (Psychodynamic, Behaviorism, CBT, Humanistic Existentialist, and Postmodernist) alongside an integrative therapy with a unified three-stage clinical framework across six core psychological topics. \textbf{3) How to systematically evaluate an AI counselor?} We establish a holistic evaluation framework with 18 therapy-specific and therapy-shared metrics across Client-Level and Counselor-Level dimensions. To support this, we also construct over 2,000 diverse client profiles. Extensive experimental analysis fully validates the superior quality and clinical fidelity of our dataset. Crucially, \texttt{PsychEval} transcends static benchmarking to serve as a high-fidelity reinforcement learning environment that enables the self-evolutionary training of clinically responsible and adaptive AI counselors.
Black-box Model Merging for Language-Model-as-a-Service with Massive Model Repositories
Sep 16, 2025



Model merging refers to the process of integrating multiple distinct models into a unified model that preserves and combines the strengths and capabilities of the individual models. Most existing approaches rely on task vectors to combine models, typically under the assumption that model parameters are accessible. However, for extremely large language models (LLMs) such as GPT-4, which are often provided solely as black-box services through API interfaces (Language-Model-as-a-Service), model weights are not available to end users. This presents a significant challenge, which we refer to as black-box model merging (BMM) with massive LLMs. To address this challenge, we propose a derivative-free optimization framework based on the evolutionary algorithm (Evo-Merging) that enables effective model merging using only inference-time API queries. Our method consists of two key components: (1) sparsity-based denoising, designed to identify and filter out irrelevant or redundant information across models, and (2) sign-aware scaling, which dynamically computes optimal combination weights for the relevant models based on their performance. We also provide a formal justification, along with a theoretical analysis, for our asymmetric sparsification. Extensive experimental evaluations demonstrate that our approach achieves state-of-the-art results on a range of tasks, significantly outperforming existing strong baselines.
Forget What's Sensitive, Remember What Matters: Token-Level Differential Privacy in Memory Sculpting for Continual Learning
Sep 16, 2025



Continual Learning (CL) models, while adept at sequential knowledge acquisition, face significant and often overlooked privacy challenges due to accumulating diverse information. Traditional privacy methods, like a uniform Differential Privacy (DP) budget, indiscriminately protect all data, leading to substantial model utility degradation and hindering CL deployment in privacy-sensitive areas. To overcome this, we propose a privacy-enhanced continual learning (PeCL) framework that forgets what's sensitive and remembers what matters. Our approach first introduces a token-level dynamic Differential Privacy strategy that adaptively allocates privacy budgets based on the semantic sensitivity of individual tokens. This ensures robust protection for private entities while minimizing noise injection for non-sensitive, general knowledge. Second, we integrate a privacy-guided memory sculpting module. This module leverages the sensitivity analysis from our dynamic DP mechanism to intelligently forget sensitive information from the model's memory and parameters, while explicitly preserving the task-invariant historical knowledge crucial for mitigating catastrophic forgetting. Extensive experiments show that PeCL achieves a superior balance between privacy preserving and model utility, outperforming baseline models by maintaining high accuracy on previous tasks while ensuring robust privacy.
Building Self-Evolving Agents via Experience-Driven Lifelong Learning: A Framework and Benchmark
Aug 26, 2025As AI advances toward general intelligence, the focus is shifting from systems optimized for static tasks to creating open-ended agents that learn continuously. In this paper, we introduce Experience-driven Lifelong Learning (ELL), a framework for building self-evolving agents capable of continuous growth through real-world interaction. The framework is built on four core principles: (1) Experience Exploration: Agents learn through continuous, self-motivated interaction with dynamic environments, navigating interdependent tasks and generating rich experiential trajectories. (2) Long-term Memory: Agents preserve and structure historical knowledge, including personal experiences, domain expertise, and commonsense reasoning, into a persistent memory system. (3) Skill Learning: Agents autonomously improve by abstracting recurring patterns from experience into reusable skills, which are actively refined and validated for application in new tasks. (4) Knowledge Internalization: Agents internalize explicit and discrete experiences into implicit and intuitive capabilities as "second nature". We also introduce StuLife, a benchmark dataset for ELL that simulates a student's holistic college journey, from enrollment to academic and personal development, across three core phases and ten detailed sub-scenarios. StuLife is designed around three key paradigm shifts: From Passive to Proactive, From Context to Memory, and From Imitation to Learning. In this dynamic environment, agents must acquire and distill practical skills and maintain persistent memory to make decisions based on evolving state variables. StuLife provides a comprehensive platform for evaluating lifelong learning capabilities, including memory retention, skill transfer, and self-motivated behavior. Beyond evaluating SOTA LLMs on the StuLife benchmark, we also explore the role of context engineering in advancing AGI.
Reinforced Interactive Continual Learning via Real-time Noisy Human Feedback
May 15, 2025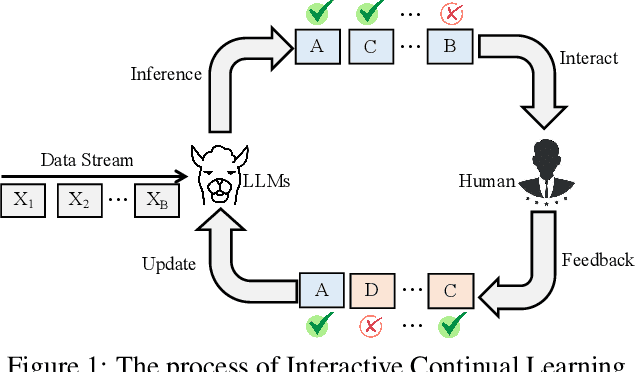
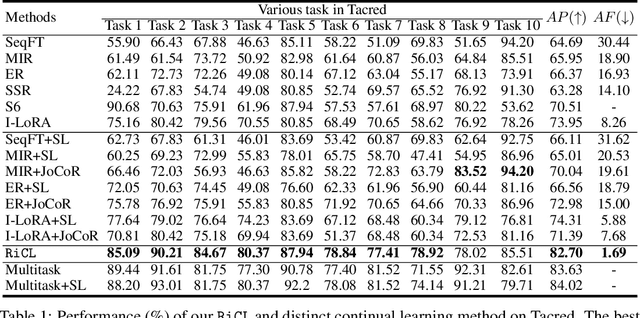
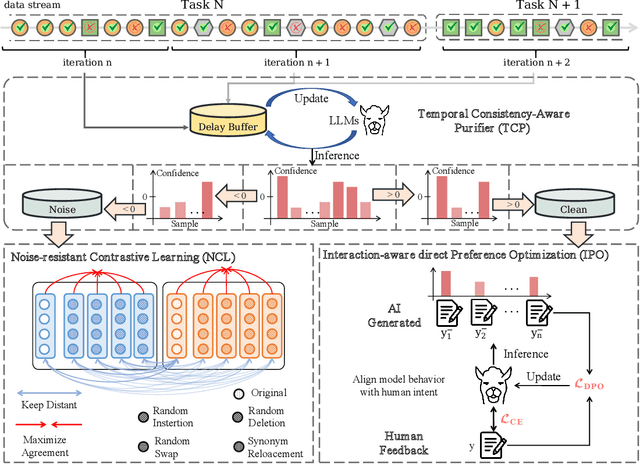

This paper introduces an interactive continual learning paradigm where AI models dynamically learn new skills from real-time human feedback while retaining prior knowledge. This paradigm distinctively addresses two major limitations of traditional continual learning: (1) dynamic model updates using streaming, real-time human-annotated data, rather than static datasets with fixed labels, and (2) the assumption of clean labels, by explicitly handling the noisy feedback common in real-world interactions. To tackle these problems, we propose RiCL, a Reinforced interactive Continual Learning framework leveraging Large Language Models (LLMs) to learn new skills effectively from dynamic feedback. RiCL incorporates three key components: a temporal consistency-aware purifier to automatically discern clean from noisy samples in data streams; an interaction-aware direct preference optimization strategy to align model behavior with human intent by reconciling AI-generated and human-provided feedback; and a noise-resistant contrastive learning module that captures robust representations by exploiting inherent data relationships, thus avoiding reliance on potentially unreliable labels. Extensive experiments on two benchmark datasets (FewRel and TACRED), contaminated with realistic noise patterns, demonstrate that our RiCL approach substantially outperforms existing combinations of state-of-the-art online continual learning and noisy-label learning methods.
Recent Advances of Foundation Language Models-based Continual Learning: A Survey
May 28, 2024Recently, foundation language models (LMs) have marked significant achievements in the domains of natural language processing (NLP) and computer vision (CV). Unlike traditional neural network models, foundation LMs obtain a great ability for transfer learning by acquiring rich commonsense knowledge through pre-training on extensive unsupervised datasets with a vast number of parameters. However, they still can not emulate human-like continuous learning due to catastrophic forgetting. Consequently, various continual learning (CL)-based methodologies have been developed to refine LMs, enabling them to adapt to new tasks without forgetting previous knowledge. However, a systematic taxonomy of existing approaches and a comparison of their performance are still lacking, which is the gap that our survey aims to fill. We delve into a comprehensive review, summarization, and classification of the existing literature on CL-based approaches applied to foundation language models, such as pre-trained language models (PLMs), large language models (LLMs) and vision-language models (VLMs). We divide these studies into offline CL and online CL, which consist of traditional methods, parameter-efficient-based methods, instruction tuning-based methods and continual pre-training methods. Offline CL encompasses domain-incremental learning, task-incremental learning, and class-incremental learning, while online CL is subdivided into hard task boundary and blurry task boundary settings. Additionally, we outline the typical datasets and metrics employed in CL research and provide a detailed analysis of the challenges and future work for LMs-based continual learning.