 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpark-Prover-X1: Formal Theorem Proving Through Diverse Data Training
Nov 18, 2025Large Language Models (LLMs) have shown significant promise in automated theorem proving, yet progress is often constrained by the scarcity of diverse and high-quality formal language data. To address this issue, we introduce Spark-Prover-X1, a 7B parameter model trained via an three-stage framework designed to unlock the reasoning potential of more accessible and moderately-sized LLMs. The first stage infuses deep knowledge through continuous pre-training on a broad mathematical corpus, enhanced by a suite of novel data tasks. Key innovation is a "CoT-augmented state prediction" task to achieve fine-grained reasoning. The second stage employs Supervised Fine-tuning (SFT) within an expert iteration loop to specialize both the Spark-Prover-X1-7B and Spark-Formalizer-X1-7B models. Finally, a targeted round of Group Relative Policy Optimization (GRPO) is applied to sharpen the prover's capabilities on the most challenging problems. To facilitate robust evaluation, particularly on problems from real-world examinations, we also introduce ExamFormal-Bench, a new benchmark dataset of 402 formal problems. Experimental results demonstrate that Spark-Prover achieves state-of-the-art performance among similarly-sized open-source models within the "Whole-Proof Generation" paradigm. It shows exceptional performance on difficult competition benchmarks, notably solving 27 problems on PutnamBench (pass@32) and achieving 24.0\% on CombiBench (pass@32). Our work validates that this diverse training data and progressively refined training pipeline provides an effective path for enhancing the formal reasoning capabilities of lightweight LLMs. Both Spark-Prover-X1-7B and Spark-Formalizer-X1-7B, along with the ExamFormal-Bench dataset, are made publicly available at: https://www.modelscope.cn/organization/iflytek, https://gitcode.com/ifly_opensource.
CARE-Bench: A Benchmark of Diverse Client Simulations Guided by Expert Principles for Evaluating LLMs in Psychological Counseling
Nov 12, 2025The mismatch between the growing demand for psychological counseling and the limited availability of services has motivated research into the application of Large Language Models (LLMs) in this domain. Consequently, there is a need for a robust and unified benchmark to assess the counseling competence of various LLMs. Existing works, however, are limited by unprofessional client simulation, static question-and-answer evaluation formats, and unidimensional metrics. These limitations hinder their effectiveness in assessing a model's comprehensive ability to handle diverse and complex clients. To address this gap, we introduce \textbf{CARE-Bench}, a dynamic and interactive automated benchmark. It is built upon diverse client profiles derived from real-world counseling cases and simulated according to expert guidelines. CARE-Bench provides a multidimensional performance evaluation grounded in established psychological scales. Using CARE-Bench, we evaluate several general-purpose LLMs and specialized counseling models, revealing their current limitations. In collaboration with psychologists, we conduct a detailed analysis of the reasons for LLMs' failures when interacting with clients of different types, which provides directions for developing more comprehensive, universal, and effective counseling models.
WeaveRec: An LLM-Based Cross-Domain Sequential Recommendation Framework with Model Merging
Oct 30, 2025



Cross-Domain Sequential Recommendation (CDSR) seeks to improve user preference modeling by transferring knowledge from multiple domains. Despite the progress made in CDSR, most existing methods rely on overlapping users or items to establish cross-domain correlations-a requirement that rarely holds in real-world settings. The advent of large language models (LLM) and model-merging techniques appears to overcome this limitation by unifying multi-domain data without explicit overlaps. Yet, our empirical study shows that naively training an LLM on combined domains-or simply merging several domain-specific LLMs-often degrades performance relative to a model trained solely on the target domain. To address these challenges, we first experimentally investigate the cause of suboptimal performance in LLM-based cross-domain recommendation and model merging. Building on these insights, we introduce WeaveRec, which cross-trains multiple LoRA modules with source and target domain data in a weaving fashion, and fuses them via model merging. WeaveRec can be extended to multi-source domain scenarios and notably does not introduce additional inference-time cost in terms of latency or memory. Furthermore, we provide a theoretical guarantee that WeaveRec can reduce the upper bound of the expected error in the target domain. Extensive experiments on single-source, multi-source, and cross-platform cross-domain recommendation scenarios validate that WeaveRec effectively mitigates performance degradation and consistently outperforms baseline approaches in real-world recommendation tasks.
MoRE: A Mixture of Low-Rank Experts for Adaptive Multi-Task Learning
May 28, 2025



With the rapid development of Large Language Models (LLMs), Parameter-Efficient Fine-Tuning (PEFT) methods have gained significant attention, which aims to achieve efficient fine-tuning of LLMs with fewer parameters. As a representative PEFT method, Low-Rank Adaptation (LoRA) introduces low-rank matrices to approximate the incremental tuning parameters and achieves impressive performance over multiple scenarios. After that, plenty of improvements have been proposed for further improvement. However, these methods either focus on single-task scenarios or separately train multiple LoRA modules for multi-task scenarios, limiting the efficiency and effectiveness of LoRA in multi-task scenarios. To better adapt to multi-task fine-tuning, in this paper, we propose a novel Mixture of Low-Rank Experts (MoRE) for multi-task PEFT. Specifically, instead of using an individual LoRA for each task, we align different ranks of LoRA module with different tasks, which we named low-rank experts. Moreover, we design a novel adaptive rank selector to select the appropriate expert for each task. By jointly training low-rank experts, MoRE can enhance the adaptability and efficiency of LoRA in multi-task scenarios. Finally, we conduct extensive experiments over multiple multi-task benchmarks along with different LLMs to verify model performance. Experimental results demonstrate that compared to traditional LoRA and its variants, MoRE significantly improves the performance of LLMs in multi-task scenarios and incurs no additional inference cost. We also release the model and code to facilitate the community.
How Does Sequence Modeling Architecture Influence Base Capabilities of Pre-trained Language Models? Exploring Key Architecture Design Principles to Avoid Base Capabilities Degradation
May 24, 2025Pre-trained language models represented by the Transformer have been proven to possess strong base capabilities, and the representative self-attention mechanism in the Transformer has become a classic in sequence modeling architectures. Different from the work of proposing sequence modeling architecture to improve the efficiency of attention mechanism, this work focuses on the impact of sequence modeling architectures on base capabilities. Specifically, our concern is: How exactly do sequence modeling architectures affect the base capabilities of pre-trained language models? In this work, we first point out that the mixed domain pre-training setting commonly adopted in existing architecture design works fails to adequately reveal the differences in base capabilities among various architectures. To address this, we propose a limited domain pre-training setting with out-of-distribution testing, which successfully uncovers significant differences in base capabilities among architectures at an early stage. Next, we analyze the base capabilities of stateful sequence modeling architectures, and find that they exhibit significant degradation in base capabilities compared to the Transformer. Then, through a series of architecture component analysis, we summarize a key architecture design principle: A sequence modeling architecture need possess full-sequence arbitrary selection capability to avoid degradation in base capabilities. Finally, we empirically validate this principle using an extremely simple Top-1 element selection architecture and further generalize it to a more practical Top-1 chunk selection architecture. Experimental results demonstrate our proposed sequence modeling architecture design principle and suggest that our work can serve as a valuable reference for future architecture improvements and novel designs.
SemEval-2021 Task 4: Reading Comprehension of Abstract Meaning
Jun 01, 2021

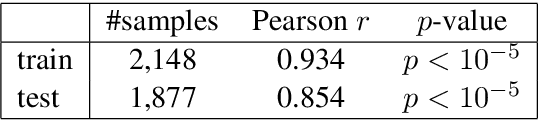
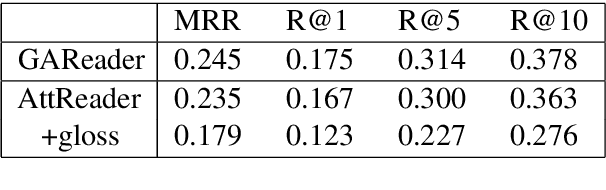
This paper introduces the SemEval-2021 shared task 4: Reading Comprehension of Abstract Meaning (ReCAM). This shared task is designed to help evaluate the ability of machines in representing and understanding abstract concepts. Given a passage and the corresponding question, a participating system is expected to choose the correct answer from five candidates of abstract concepts in a cloze-style machine reading comprehension setup. Based on two typical definitions of abstractness, i.e., the imperceptibility and nonspecificity, our task provides three subtasks to evaluate the participating models. Specifically, Subtask 1 aims to evaluate how well a system can model concepts that cannot be directly perceived in the physical world. Subtask 2 focuses on models' ability in comprehending nonspecific concepts located high in a hypernym hierarchy given the context of a passage. Subtask 3 aims to provide some insights into models' generalizability over the two types of abstractness. During the SemEval-2021 official evaluation period, we received 23 submissions to Subtask 1 and 28 to Subtask 2. The participating teams additionally made 29 submissions to Subtask 3. The leaderboard and competition website can be found at https://competitions.codalab.org/competitions/26153. The data and baseline code are available at https://github.com/boyuanzheng010/SemEval2021-Reading-Comprehension-of-Abstract-Meaning.
Filtering before Iteratively Referring for Knowledge-Grounded Response Selection in Retrieval-Based Chatbots
Apr 30, 2020
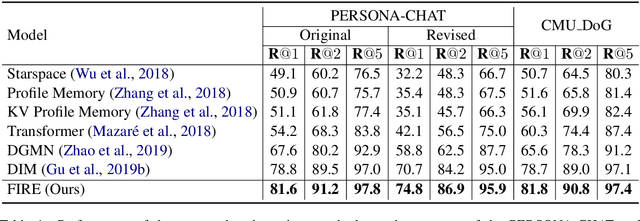
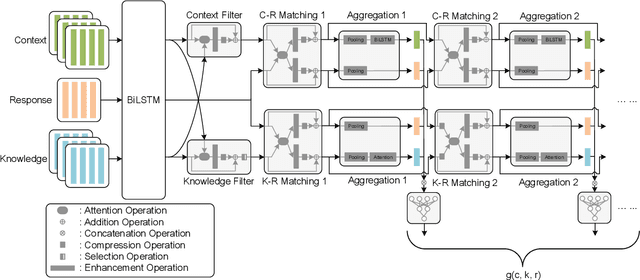
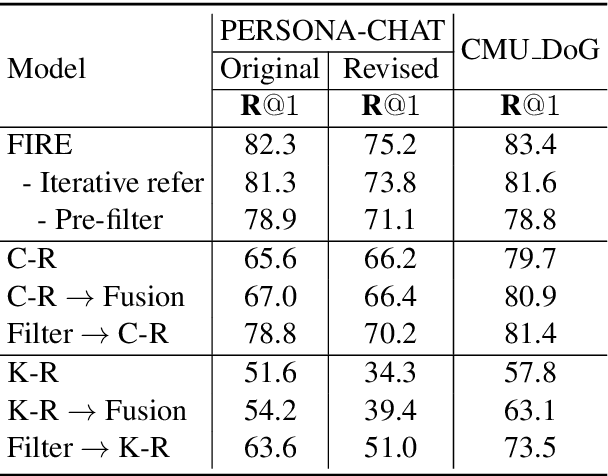
The challenges of building knowledge-grounded retrieval-based chatbots lie in how to ground a conversation on the background knowledge and how to perform their matching with the response. This paper proposes a method named Filtering before Iteratively REferring (FIRE) for presenting the background knowledge of dialogue agents in retrieval-based chatbots. We first propose a pre-filter, which is composed of a context filter and a knowledge filter. This pre-filter grounds the conversation on the knowledge and comprehends the knowledge according to the conversation by collecting the matching information between them bidirectionally, and then recognizing the important information in them accordingly. After that, iteratively referring is performed between the context and the response, as well as between the knowledge and the response, in order to collect the deep and wide matching information. Experimental results show that the FIRE model outperforms previous methods by margins larger than 2.8% on original personas and 4.1% on revised personas on the PERSONA-CHAT dataset, as well as 3.1% on the CMU_DoG dataset in terms of top-1 accuracy.
DialBERT: A Hierarchical Pre-Trained Model for Conversation Disentanglement
Apr 08, 2020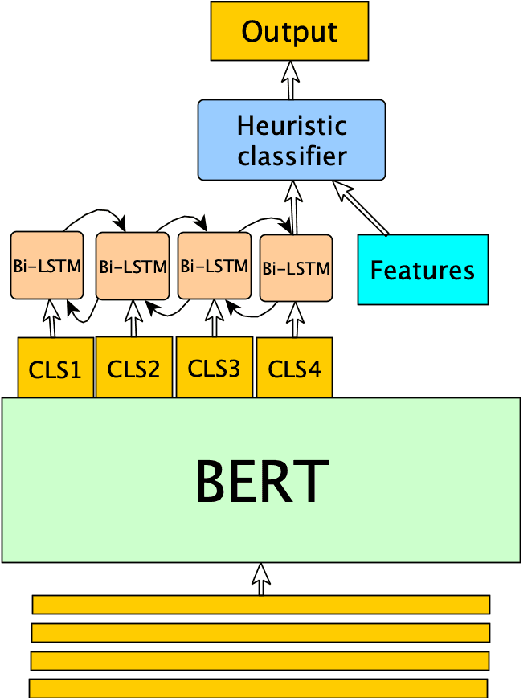
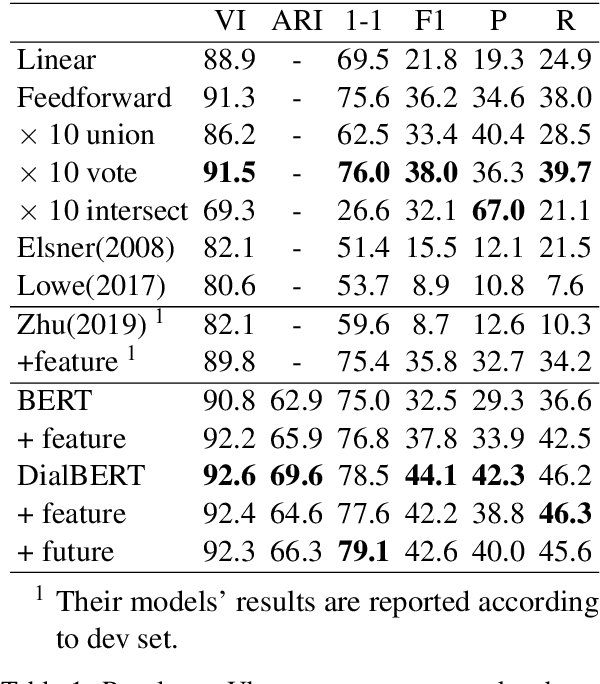
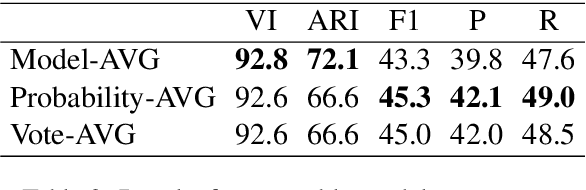
Disentanglement is a problem in which multiple conversations occur in the same channel simultaneously, and the listener should decide which utterance is part of the conversation he will respond to. We propose a new model, named Dialogue BERT (DialBERT), which integrates local and global semantics in a single stream of messages to disentangle the conversations that mixed together. We employ BERT to capture the matching information in each utterance pair at the utterance-level, and use a BiLSTM to aggregate and incorporate the context-level information. With only a 3% increase in parameters, a 12% improvement has been attained in comparison to BERT, based on the F1-Score. The model achieves a state-of-the-art result on the a new dataset proposed by IBM and surpasses previous work by a substantial margin.
Speaker-Aware BERT for Multi-Turn Response Selection in Retrieval-Based Chatbots
Apr 07, 2020
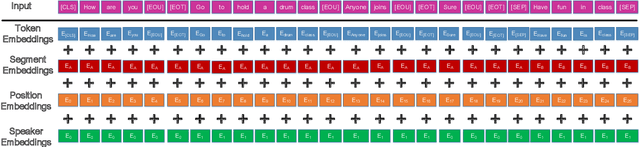

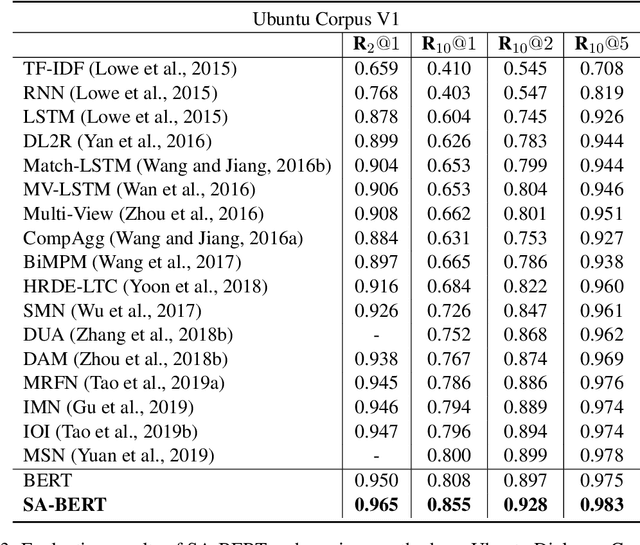
In this paper, we study the problem of employing pre-trained language models for multi-turn response selection in retrieval-based chatbots. A new model, named Speaker-Aware BERT (SA-BERT), is proposed in order to make the model aware of the speaker change information, which is an important and intrinsic property of multi-turn dialogues. Furthermore, a speaker-aware disentanglement strategy is proposed to tackle the entangled dialogues. This strategy selects a small number of most important utterances as the filtered context according to the speakers' information in them. Finally, domain adaptation is performed in order to incorporate the in-domain knowledge into pre-trained language models. Experiments on five public datasets show that our proposed model outperforms the present models on all metrics by large margins and achieves new state-of-the-art performances for multi-turn response selection.
Several Experiments on Investigating Pretraining and Knowledge-Enhanced Models for Natural Language Inference
Apr 27, 2019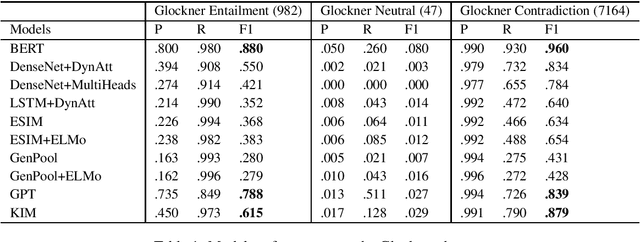
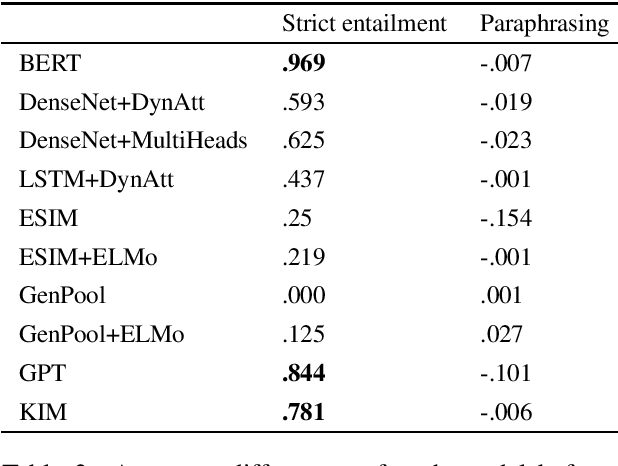


Natural language inference (NLI) is among the most challenging tasks in natural language understanding. Recent work on unsupervised pretraining that leverages unsupervised signals such as language-model and sentence prediction objectives has shown to be very effective on a wide range of NLP problems. It would still be desirable to further understand how it helps NLI; e.g., if it learns artifacts in data annotation or instead learn true inference knowledge. In addition, external knowledge that does not exist in the limited amount of NLI training data may be added to NLI models in two typical ways, e.g., from human-created resources or an unsupervised pretraining paradigm. We runs several experiments here to investigate whether they help NLI in the same way, and if not,how?