 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowRAG: Synergizing Explicit Reasoning via Frequency-Aware Multi-Granularity Graph Flow
Jun 16, 2026Graph-based retrieval-augmented generation (GraphRAG) is effective for knowledge-intensive and multi-hop query tasks; however, many existing methods primarily seed entity-based graphs and rely on implicit semantic relevance propagation. This often (i) under-retrieves when user queries are abstract and semantically sparse at the entity level, and (ii) suffers from brittle multi-hop reasoning, where noisy activations can derail entity-to-entity transitions and corrupt the inferred relation chain, yielding unreliable conclusions. To this end, we propose \texttt{FlowRAG}, a semantic-aware retrieval framework that improves both semantic recall and explicit reasoning. Specifically, \texttt{FlowRAG} constructs a quad-level heterogeneous graph over passages, summaries, sentences, and entities, where summary nodes serve as a coarse semantic hub. At retrieval time, a dual-granularity activation module combines summary--query alignment with sentence-level matching to activate relevant entities under paraphrase and abstraction robustly. We then introduce a frequency-aware weighted flow module that routes relevance through entity--passage links weighted by within-passage term frequency, pruning noisy connections and extracting high-confidence reasoning paths as an explicit logic skeleton for generation. Extensive experiments show that \texttt{FlowRAG} obtains state-of-the-art performance on complex reasoning benchmarks.
Agents-K1: Towards Agent-native Knowledge Orchestration
Jun 11, 2026Current LLM-based research agents have advanced through agent orchestration, yet largely overlook scientific knowledge orchestration. Existing works often reduce papers to abstracts, surface mentions, and flat \texttt{cites} edges, omitting key entities, claims, evidence, mechanisms, and method lineages essential for scientific reasoning. To this end, we introduce \textbf{Agents-K1}, an end-to-end knowledge orchestration pipeline that converts raw documents into agent-native scientific knowledge graphs. Agents-K1 integrates three components under a unifying theoretical foundation: a multimodal parser whose five-module schema captures entities, multimodal evidence, citations, and typed inter-entity relations across the full paper rather than abstracts alone; a 4B information-extraction backbone trained with GRPO under a rule-based reward; and a graphanything CLI, a tri-source agent interface that unifies web search, multimodal graph retrieval, and cross-document traversal. On top of this, we process 2.46 million scientific papers across six subjects to produce \textbf{Scholar-KG}, of which we release a one-million-paper subset, and the full Scholar-KG is accessible via the SCP link below. The same pipeline can be extended to general-domain corpora and to schema-conformant data synthesis. Extensive experiments demonstrate that Agents-K1 achieves superior performance in scientific information extraction, knowledge graph construction, and multi-hop scientific reasoning.
AutoSkill: Experience-Driven Lifelong Learning via Skill Self-Evolution
Mar 05, 2026In practical LLM applications, users repeatedly express stable preferences and requirements, such as reducing hallucinations, following institutional writing conventions, or avoiding overly technical wording, yet such interaction experience is seldom consolidated into reusable knowledge. Consequently, LLM agents often fail to accumulate personalized capabilities across sessions. We present AutoSkill, an experience-driven lifelong learning framework that enables LLM agents to automatically derive, maintain, and reuse skills from dialogue and interaction traces. AutoSkill abstracts skills from user experience, supports their continual self-evolution, and dynamically injects relevant skills into future requests without retraining the underlying model. Designed as a model-agnostic plugin layer, it is compatible with existing LLMs and introduces a standardized skill representation for sharing and transfer across agents, users, and tasks. In this way, AutoSkill turns ephemeral interaction experience into explicit, reusable, and composable capabilities. This paper describes the motivation, architecture, skill lifecycle, and implementation of AutoSkill, and positions it with respect to prior work on memory, retrieval, personalization, and agentic systems. AutoSkill highlights a practical and scalable path toward lifelong personalized agents and personal digital surrogates.
Black-box Model Merging for Language-Model-as-a-Service with Massive Model Repositories
Sep 16, 2025



Model merging refers to the process of integrating multiple distinct models into a unified model that preserves and combines the strengths and capabilities of the individual models. Most existing approaches rely on task vectors to combine models, typically under the assumption that model parameters are accessible. However, for extremely large language models (LLMs) such as GPT-4, which are often provided solely as black-box services through API interfaces (Language-Model-as-a-Service), model weights are not available to end users. This presents a significant challenge, which we refer to as black-box model merging (BMM) with massive LLMs. To address this challenge, we propose a derivative-free optimization framework based on the evolutionary algorithm (Evo-Merging) that enables effective model merging using only inference-time API queries. Our method consists of two key components: (1) sparsity-based denoising, designed to identify and filter out irrelevant or redundant information across models, and (2) sign-aware scaling, which dynamically computes optimal combination weights for the relevant models based on their performance. We also provide a formal justification, along with a theoretical analysis, for our asymmetric sparsification. Extensive experimental evaluations demonstrate that our approach achieves state-of-the-art results on a range of tasks, significantly outperforming existing strong baselines.
Forget What's Sensitive, Remember What Matters: Token-Level Differential Privacy in Memory Sculpting for Continual Learning
Sep 16, 2025



Continual Learning (CL) models, while adept at sequential knowledge acquisition, face significant and often overlooked privacy challenges due to accumulating diverse information. Traditional privacy methods, like a uniform Differential Privacy (DP) budget, indiscriminately protect all data, leading to substantial model utility degradation and hindering CL deployment in privacy-sensitive areas. To overcome this, we propose a privacy-enhanced continual learning (PeCL) framework that forgets what's sensitive and remembers what matters. Our approach first introduces a token-level dynamic Differential Privacy strategy that adaptively allocates privacy budgets based on the semantic sensitivity of individual tokens. This ensures robust protection for private entities while minimizing noise injection for non-sensitive, general knowledge. Second, we integrate a privacy-guided memory sculpting module. This module leverages the sensitivity analysis from our dynamic DP mechanism to intelligently forget sensitive information from the model's memory and parameters, while explicitly preserving the task-invariant historical knowledge crucial for mitigating catastrophic forgetting. Extensive experiments show that PeCL achieves a superior balance between privacy preserving and model utility, outperforming baseline models by maintaining high accuracy on previous tasks while ensuring robust privacy.
Reinforced Interactive Continual Learning via Real-time Noisy Human Feedback
May 15, 2025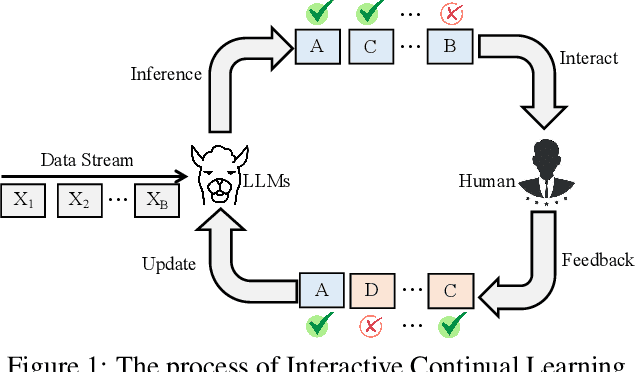
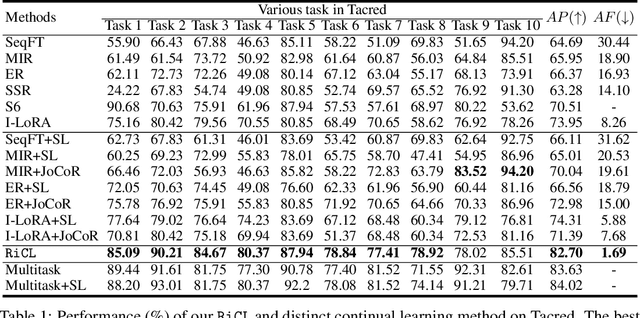
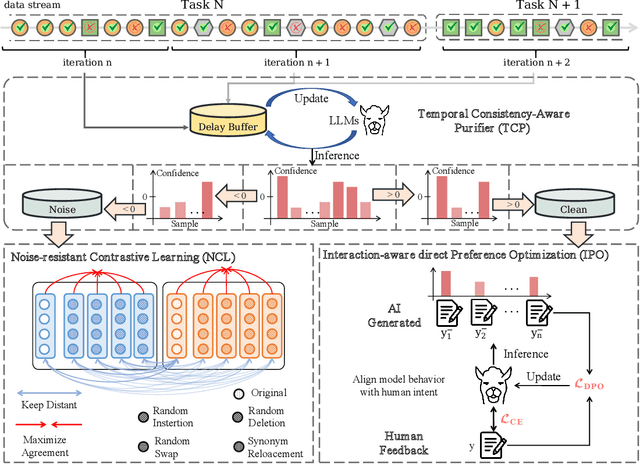

This paper introduces an interactive continual learning paradigm where AI models dynamically learn new skills from real-time human feedback while retaining prior knowledge. This paradigm distinctively addresses two major limitations of traditional continual learning: (1) dynamic model updates using streaming, real-time human-annotated data, rather than static datasets with fixed labels, and (2) the assumption of clean labels, by explicitly handling the noisy feedback common in real-world interactions. To tackle these problems, we propose RiCL, a Reinforced interactive Continual Learning framework leveraging Large Language Models (LLMs) to learn new skills effectively from dynamic feedback. RiCL incorporates three key components: a temporal consistency-aware purifier to automatically discern clean from noisy samples in data streams; an interaction-aware direct preference optimization strategy to align model behavior with human intent by reconciling AI-generated and human-provided feedback; and a noise-resistant contrastive learning module that captures robust representations by exploiting inherent data relationships, thus avoiding reliance on potentially unreliable labels. Extensive experiments on two benchmark datasets (FewRel and TACRED), contaminated with realistic noise patterns, demonstrate that our RiCL approach substantially outperforms existing combinations of state-of-the-art online continual learning and noisy-label learning methods.