 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box Model Merging for Language-Model-as-a-Service with Massive Model Repositories
Sep 16, 2025



Model merging refers to the process of integrating multiple distinct models into a unified model that preserves and combines the strengths and capabilities of the individual models. Most existing approaches rely on task vectors to combine models, typically under the assumption that model parameters are accessible. However, for extremely large language models (LLMs) such as GPT-4, which are often provided solely as black-box services through API interfaces (Language-Model-as-a-Service), model weights are not available to end users. This presents a significant challenge, which we refer to as black-box model merging (BMM) with massive LLMs. To address this challenge, we propose a derivative-free optimization framework based on the evolutionary algorithm (Evo-Merging) that enables effective model merging using only inference-time API queries. Our method consists of two key components: (1) sparsity-based denoising, designed to identify and filter out irrelevant or redundant information across models, and (2) sign-aware scaling, which dynamically computes optimal combination weights for the relevant models based on their performance. We also provide a formal justification, along with a theoretical analysis, for our asymmetric sparsification. Extensive experimental evaluations demonstrate that our approach achieves state-of-the-art results on a range of tasks, significantly outperforming existing strong baselines.
TIPCB: A Simple but Effective Part-based Convolutional Baseline for Text-based Person Search
May 25, 2021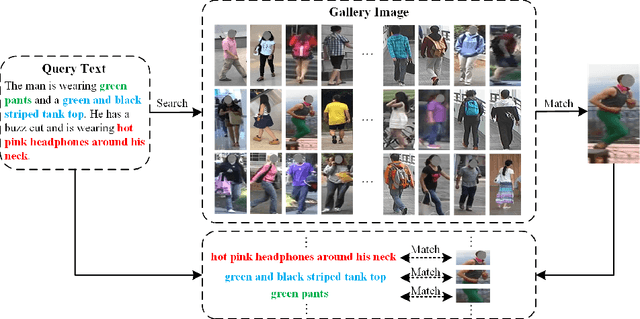
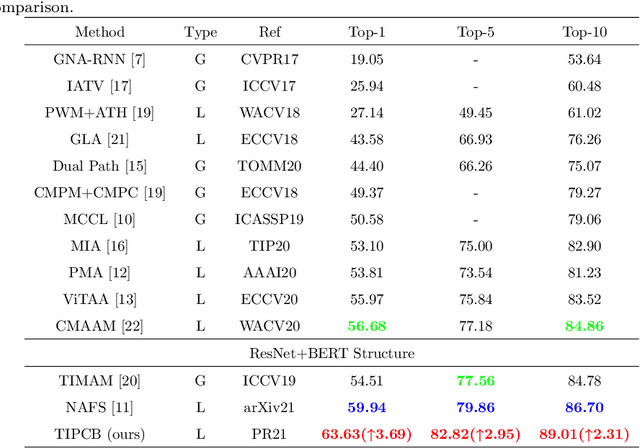
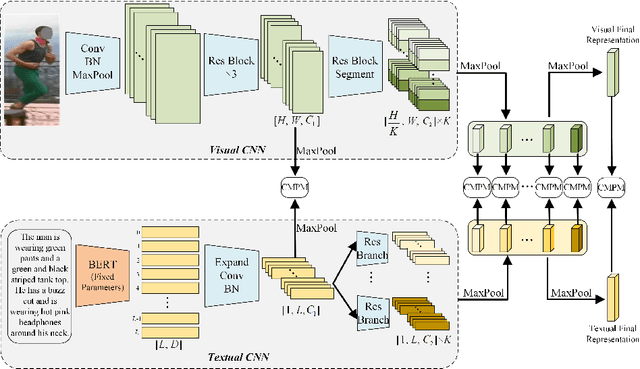
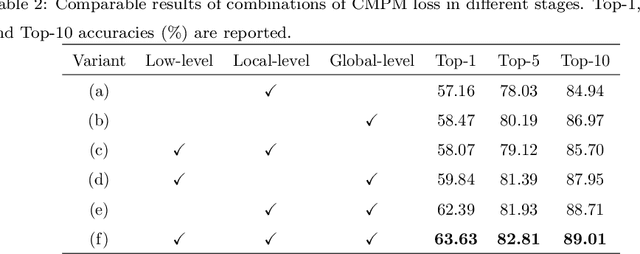
Text-based person search is a sub-task in the field of image retrieval, which aims to retrieve target person images according to a given textual description. The significant feature gap between two modalities makes this task very challenging. Many existing methods attempt to utilize local alignment to address this problem in the fine-grained level. However, most relevant methods introduce additional models or complicated training and evaluation strategies, which are hard to use in realistic scenarios. In order to facilitate the practical application, we propose a simple but effective end-to-end learning framework for text-based person search named TIPCB (i.e., Text-Image Part-based Convolutional Baseline). Firstly, a novel dual-path local alignment network structure is proposed to extract visual and textual local representations, in which images are segmented horizontally and texts are aligned adaptively. Then, we propose a multi-stage cross-modal matching strategy, which eliminates the modality gap from three feature levels, including low level, local level and global level. Extensive experiments are conducted on the widely-used benchmark dataset (CUHK-PEDES) and verify that our method outperforms the state-of-the-art methods by 3.69%, 2.95% and 2.31% in terms of Top-1, Top-5 and Top-10. Our code has been released in https://github.com/OrangeYHChen/TIPCB.