 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOP-GRPO: Efficient Off-Policy GRPO for Flow-Matching Models
Apr 05, 2026Post training via GRPO has demonstrated remarkable effectiveness in improving the generation quality of flow-matching models. However, GRPO suffers from inherently low sample efficiency due to its on-policy training paradigm. To address this limitation, we present OP-GRPO, the first Off-Policy GRPO framework tailored for flow-matching models. First, we actively select high-quality trajectories and adaptively incorporate them into a replay buffer for reuse in subsequent training iterations. Second, to mitigate the distribution shift introduced by off-policy samples, we propose a sequence-level importance sampling correction that preserves the integrity of GRPO's clipping mechanism while ensuring stable policy updates. Third, we theoretically and empirically show that late denoising steps yield ill-conditioned off-policy ratios, and mitigate this by truncating trajectories at late steps. Across image and video generation benchmarks, OP-GRPO achieves comparable or superior performance to Flow-GRPO with only 34.2% of the training steps on average, yielding substantial gains in training efficiency while maintaining generation quality.
RynnBrain: Open Embodied Foundation Models
Feb 13, 2026Despite rapid progress in multimodal foundation models, embodied intelligence community still lacks a unified, physically grounded foundation model that integrates perception, reasoning, and planning within real-world spatial-temporal dynamics. We introduce RynnBrain, an open-source spatiotemporal foundation model for embodied intelligence. RynnBrain strengthens four core capabilities in a unified framework: comprehensive egocentric understanding, diverse spatiotemporal localization, physically grounded reasoning, and physics-aware planning. The RynnBrain family comprises three foundation model scales (2B, 8B, and 30B-A3B MoE) and four post-trained variants tailored for downstream embodied tasks (i.e., RynnBrain-Nav, RynnBrain-Plan, and RynnBrain-VLA) or complex spatial reasoning tasks (i.e., RynnBrain-CoP). In terms of extensive evaluations on 20 embodied benchmarks and 8 general vision understanding benchmarks, our RynnBrain foundation models largely outperform existing embodied foundation models by a significant margin. The post-trained model suite further substantiates two key potentials of the RynnBrain foundation model: (i) enabling physically grounded reasoning and planning, and (ii) serving as a strong pretrained backbone that can be efficiently adapted to diverse embodied tasks.
Generating Risky Samples with Conformity Constraints via Diffusion Models
Dec 21, 2025Although neural networks achieve promising performance in many tasks, they may still fail when encountering some examples and bring about risks to applications. To discover risky samples, previous literature attempts to search for patterns of risky samples within existing datasets or inject perturbation into them. Yet in this way the diversity of risky samples is limited by the coverage of existing datasets. To overcome this limitation, recent works adopt diffusion models to produce new risky samples beyond the coverage of existing datasets. However, these methods struggle in the conformity between generated samples and expected categories, which could introduce label noise and severely limit their effectiveness in applications. To address this issue, we propose RiskyDiff that incorporates the embeddings of both texts and images as implicit constraints of category conformity. We also design a conformity score to further explicitly strengthen the category conformity, as well as introduce the mechanisms of embedding screening and risky gradient guidance to boost the risk of generated samples. Extensive experiments reveal that RiskyDiff greatly outperforms existing methods in terms of the degree of risk, generation quality, and conformity with conditioned categories. We also empirically show the generalization ability of the models can be enhanced by augmenting training data with generated samples of high conformity.
DynaIP: Dynamic Image Prompt Adapter for Scalable Zero-shot Personalized Text-to-Image Generation
Dec 10, 2025



Personalized Text-to-Image (PT2I) generation aims to produce customized images based on reference images. A prominent interest pertains to the integration of an image prompt adapter to facilitate zero-shot PT2I without test-time fine-tuning. However, current methods grapple with three fundamental challenges: 1. the elusive equilibrium between Concept Preservation (CP) and Prompt Following (PF), 2. the difficulty in retaining fine-grained concept details in reference images, and 3. the restricted scalability to extend to multi-subject personalization. To tackle these challenges, we present Dynamic Image Prompt Adapter (DynaIP), a cutting-edge plugin to enhance the fine-grained concept fidelity, CP-PF balance, and subject scalability of SOTA T2I multimodal diffusion transformers (MM-DiT) for PT2I generation. Our key finding is that MM-DiT inherently exhibit decoupling learning behavior when injecting reference image features into its dual branches via cross attentions. Based on this, we design an innovative Dynamic Decoupling Strategy that removes the interference of concept-agnostic information during inference, significantly enhancing the CP-PF balance and further bolstering the scalability of multi-subject compositions. Moreover, we identify the visual encoder as a key factor affecting fine-grained CP and reveal that the hierarchical features of commonly used CLIP can capture visual information at diverse granularity levels. Therefore, we introduce a novel Hierarchical Mixture-of-Experts Feature Fusion Module to fully leverage the hierarchical features of CLIP, remarkably elevating the fine-grained concept fidelity while also providing flexible control of visual granularity. Extensive experiments across single- and multi-subject PT2I tasks verify that our DynaIP outperforms existing approaches, marking a notable advancement in the field of PT2l generation.
ODP-Bench: Benchmarking Out-of-Distribution Performance Prediction
Oct 31, 2025Recently, there has been gradually more attention paid to Out-of-Distribution (OOD) performance prediction, whose goal is to predict the performance of trained models on unlabeled OOD test datasets, so that we could better leverage and deploy off-the-shelf trained models in risk-sensitive scenarios. Although progress has been made in this area, evaluation protocols in previous literature are inconsistent, and most works cover only a limited number of real-world OOD datasets and types of distribution shifts. To provide convenient and fair comparisons for various algorithms, we propose Out-of-Distribution Performance Prediction Benchmark (ODP-Bench), a comprehensive benchmark that includes most commonly used OOD datasets and existing practical performance prediction algorithms. We provide our trained models as a testbench for future researchers, thus guaranteeing the consistency of comparison and avoiding the burden of repeating the model training process. Furthermore, we also conduct in-depth experimental analyses to better understand their capability boundary.
RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation
Sep 18, 2025This paper presents RynnVLA-001, a vision-language-action(VLA) model built upon large-scale video generative pretraining from human demonstrations. We propose a novel two-stage pretraining methodology. The first stage, Ego-Centric Video Generative Pretraining, trains an Image-to-Video model on 12M ego-centric manipulation videos to predict future frames conditioned on an initial frame and a language instruction. The second stage, Human-Centric Trajectory-Aware Modeling, extends this by jointly predicting future keypoint trajectories, thereby effectively bridging visual frame prediction with action prediction. Furthermore, to enhance action representation, we propose ActionVAE, a variational autoencoder that compresses sequences of actions into compact latent embeddings, reducing the complexity of the VLA output space. When finetuned on the same downstream robotics datasets, RynnVLA-001 achieves superior performance over state-of-the-art baselines, demonstrating that the proposed pretraining strategy provides a more effective initialization for VLA models.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025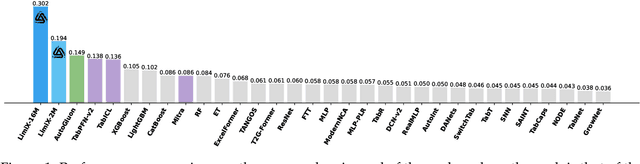
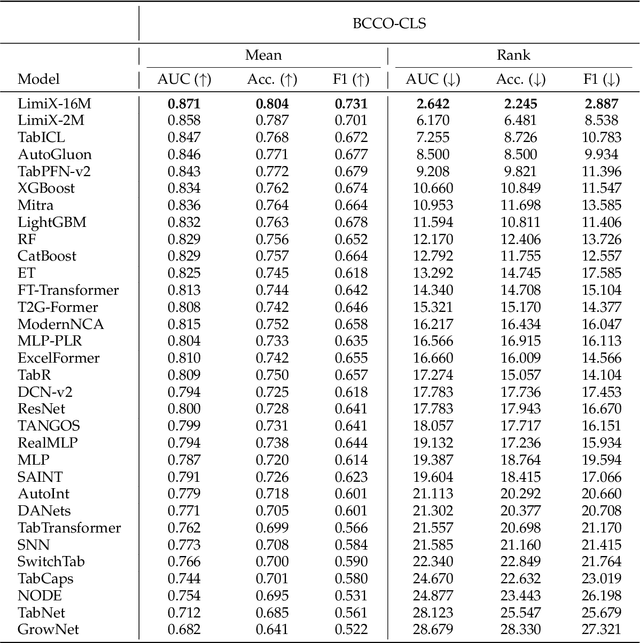
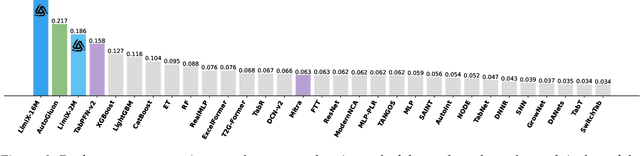
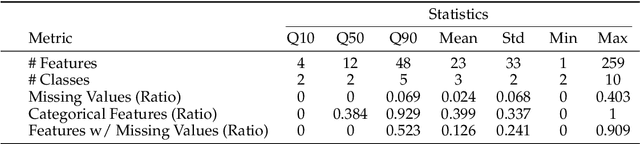
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
RynnEC: Bringing MLLMs into Embodied World
Aug 19, 2025We introduce RynnEC, a video multimodal large language model designed for embodied cognition. Built upon a general-purpose vision-language foundation model, RynnEC incorporates a region encoder and a mask decoder, enabling flexible region-level video interaction. Despite its compact architecture, RynnEC achieves state-of-the-art performance in object property understanding, object segmentation, and spatial reasoning. Conceptually, it offers a region-centric video paradigm for the brain of embodied agents, providing fine-grained perception of the physical world and enabling more precise interactions. To mitigate the scarcity of annotated 3D datasets, we propose an egocentric video based pipeline for generating embodied cognition data. Furthermore, we introduce RynnEC-Bench, a region-centered benchmark for evaluating embodied cognitive capabilities. We anticipate that RynnEC will advance the development of general-purpose cognitive cores for embodied agents and facilitate generalization across diverse embodied tasks. The code, model checkpoints, and benchmark are available at: https://github.com/alibaba-damo-academy/RynnEC
FEAT: A Multi-Agent Forensic AI System with Domain-Adapted Large Language Model for Automated Cause-of-Death Analysis
Aug 11, 2025Forensic cause-of-death determination faces systemic challenges, including workforce shortages and diagnostic variability, particularly in high-volume systems like China's medicolegal infrastructure. We introduce FEAT (ForEnsic AgenT), a multi-agent AI framework that automates and standardizes death investigations through a domain-adapted large language model. FEAT's application-oriented architecture integrates: (i) a central Planner for task decomposition, (ii) specialized Local Solvers for evidence analysis, (iii) a Memory & Reflection module for iterative refinement, and (iv) a Global Solver for conclusion synthesis. The system employs tool-augmented reasoning, hierarchical retrieval-augmented generation, forensic-tuned LLMs, and human-in-the-loop feedback to ensure legal and medical validity. In evaluations across diverse Chinese case cohorts, FEAT outperformed state-of-the-art AI systems in both long-form autopsy analyses and concise cause-of-death conclusions. It demonstrated robust generalization across six geographic regions and achieved high expert concordance in blinded validations. Senior pathologists validated FEAT's outputs as comparable to those of human experts, with improved detection of subtle evidentiary nuances. To our knowledge, FEAT is the first LLM-based AI agent system dedicated to forensic medicine, offering scalable, consistent death certification while maintaining expert-level rigor. By integrating AI efficiency with human oversight, this work could advance equitable access to reliable medicolegal services while addressing critical capacity constraints in forensic systems.
A Scalable Pipeline for Enabling Non-Verbal Speech Generation and Understanding
Aug 07, 2025Human spoken communication involves not only lexical content but also non-verbal vocalizations (NVs) such as laughter, sighs, and coughs, which convey emotions, intentions, and social signals. However, most existing speech systems focus solely on verbal content and lack the ability to understand and generate such non-verbal cues, reducing the emotional intelligence and communicative richness of spoken interfaces. In this work, we introduce $\textbf{NonVerbalSpeech-38K}$, a large and diverse dataset for non-verbal speech generation and understanding, collected from real-world media and annotated using an automatic pipeline. The dataset contains 38,718 samples (about 131 hours) with 10 categories of non-verbal cues, such as laughter, sniff, and throat clearing. We further validate the dataset by fine-tuning state-of-the-art models, including F5-TTS and Qwen2-Audio, demonstrating its effectiveness in non-verbal speech generation and understanding tasks. Our contributions are threefold: (1) We propose a practical pipeline for building natural and diverse non-verbal speech datasets; (2) We release a large-scale dataset to advance research on non-verbal speech generation and understanding; (3) We validate the dataset's effectiveness by demonstrating improvements in both non-verbal speech synthesis and captioning, thereby facilitating richer human-computer interaction.