 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoshuai Hao
DOR3D-Net: Dense Ordinal Regression Network for 3D Hand Pose Estimation
Mar 20, 2024
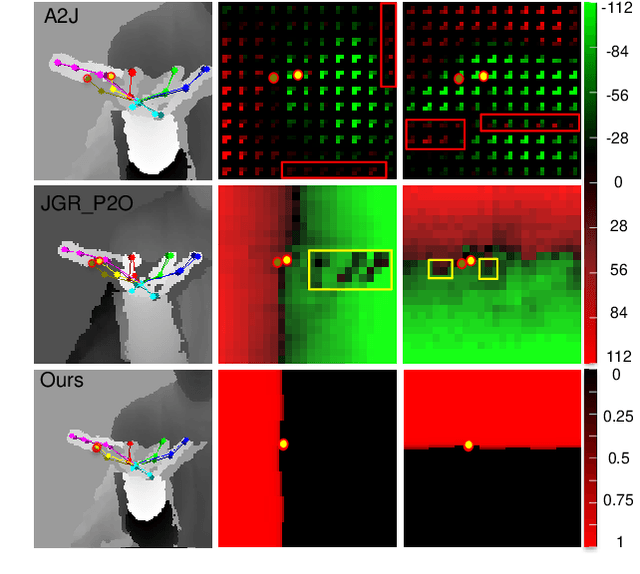
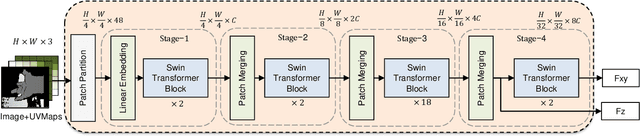
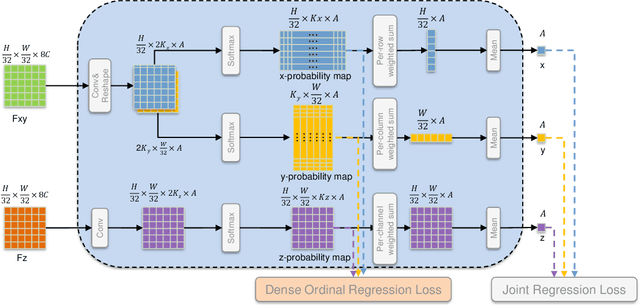
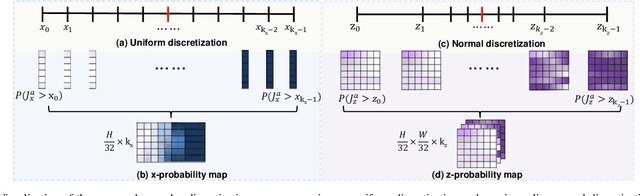
Depth-based 3D hand pose estimation is an important but challenging research task in human-machine interaction community. Recently, dense regression methods have attracted increasing attention in 3D hand pose estimation task, which provide a low computational burden and high accuracy regression way by densely regressing hand joint offset maps. However, large-scale regression offset values are often affected by noise and outliers, leading to a significant drop in accuracy. To tackle this, we re-formulate 3D hand pose estimation as a dense ordinal regression problem and propose a novel Dense Ordinal Regression 3D Pose Network (DOR3D-Net). Specifically, we first decompose offset value regression into sub-tasks of binary classifications with ordinal constraints. Then, each binary classifier can predict the probability of a binary spatial relationship relative to joint, which is easier to train and yield much lower level of noise. The estimated hand joint positions are inferred by aggregating the ordinal regression results at local positions with a weighted sum. Furthermore, both joint regression loss and ordinal regression loss are used to train our DOR3D-Net in an end-to-end manner. Extensive experiments on public datasets (ICVL, MSRA, NYU and HANDS2017) show that our design provides significant improvements over SOTA methods.
Team AcieLee: Technical Report for EPIC-SOUNDS Audio-Based Interaction Recognition Challenge 2023
Jun 15, 2023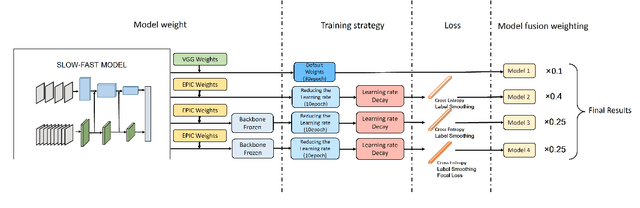

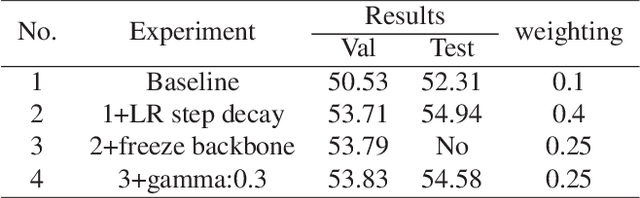
In this report, we describe the technical details of our submission to the EPIC-SOUNDS Audio-Based Interaction Recognition Challenge 2023, by Team "AcieLee" (username: Yuqi\_Li). The task is to classify the audio caused by interactions between objects, or from events of the camera wearer. We conducted exhaustive experiments and found learning rate step decay, backbone frozen, label smoothing and focal loss contribute most to the performance improvement. After training, we combined multiple models from different stages and integrated them into a single model by assigning fusion weights. This proposed method allowed us to achieve 3rd place in the CVPR 2023 workshop of EPIC-SOUNDS Audio-Based Interaction Recognition Challenge.
MixGen: A New Multi-Modal Data Augmentation
Jun 16, 2022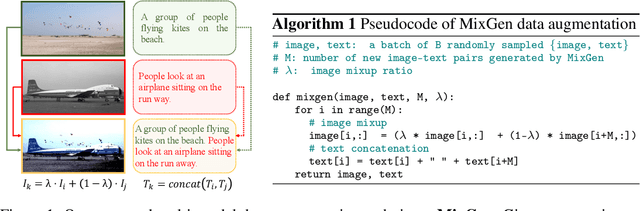

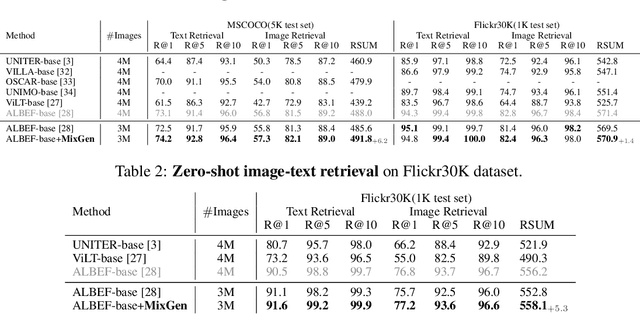
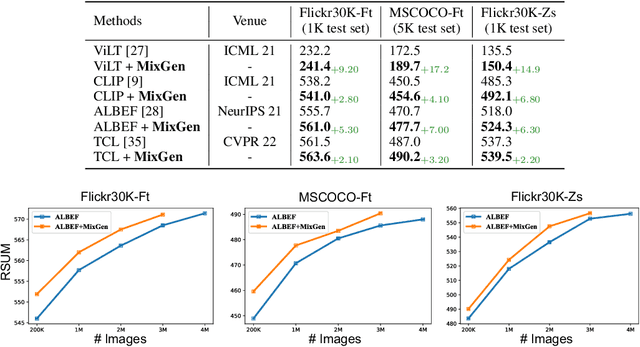
Data augmentation is a necessity to enhance data efficiency in deep learning. For vision-language pre-training, data is only augmented either for images or for text in previous works. In this paper, we present MixGen: a joint data augmentation for vision-language representation learning to further improve data efficiency. It generates new image-text pairs with semantic relationships preserved by interpolating images and concatenating text. It's simple, and can be plug-and-played into existing pipelines. We evaluate MixGen on four architectures, including CLIP, ViLT, ALBEF and TCL, across five downstream vision-language tasks to show its versatility and effectiveness. For example, adding MixGen in ALBEF pre-training leads to absolute performance improvements on downstream tasks: image-text retrieval (+6.2% on COCO fine-tuned and +5.3% on Flicker30K zero-shot), visual grounding (+0.9% on RefCOCO+), visual reasoning (+0.9% on NLVR$^{2}$), visual question answering (+0.3% on VQA2.0), and visual entailment (+0.4% on SNLI-VE).
The End-of-End-to-End: A Video Understanding Pentathlon Challenge (2020)
Aug 03, 2020
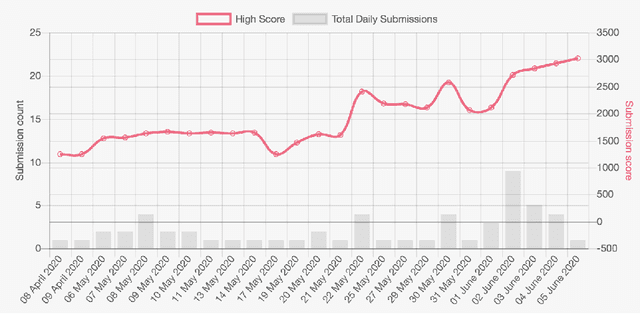
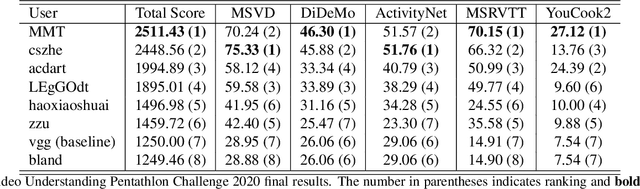
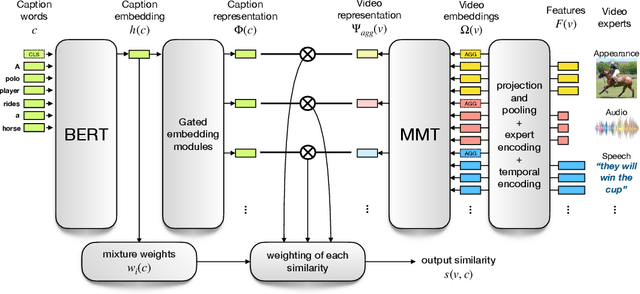
We present a new video understanding pentathlon challenge, an open competition held in conjunction with the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020. The objective of the challenge was to explore and evaluate new methods for text-to-video retrieval-the task of searching for content within a corpus of videos using natural language queries. This report summarizes the results of the first edition of the challenge together with the findings of the participants.