 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneVLA: A Unified Framework for Embodied Tasks
May 31, 2026Navigation and manipulation are fundamental capabilities of embodied intelligence, enabling robots to interpret natural language commands and interact physically with their surroundings. However, current Vision-Language-Action (VLA) models remain constrained by task-specific architectures, specializing in either navigation or manipulation, which hinders the development of general-purpose robotic agents. To bridge this gap, we introduce OneVLA, a unified architecture that integrates these distinct tasks into a single, cohesive framework. Specifically, we design a unified action head capable of generating both navigation and manipulation actions without requiring task-specific variants. Furthermore, we propose a multi stage progressive training strategy-incorporating curated data construction and Chain-of-Thought (CoT) fine-tuning that facilitates strong positive transfer and mutual reinforcement between the two domains. Extensive experiments in both simulated and real-world environments demonstrate that OneVLA achieves state-of-the-art performance, significantly outperforming both specialized single-task and existing cross-task models. By unifying these core capabilities, OneVLA paves the way for truly general-purpose robotic systems. The model and source code will be publicly released.
OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Apr 20, 2026Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. At inference, the auxiliary decoders are discarded and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering state-of-the-art accuracy at answer-only latency, and providing direct evidence that tighter compression, when guided in both language and world-model supervision, produces more generalizable representations than verbose token-by-token reasoning. Project Page: https://xiaomi-embodied-intelligence.github.io/OneVL
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Is your VLM Sky-Ready? A Comprehensive Spatial Intelligence Benchmark for UAV Navigation
Nov 17, 2025



Vision-Language Models (VLMs), leveraging their powerful visual perception and reasoning capabilities, have been widely applied in Unmanned Aerial Vehicle (UAV) tasks. However, the spatial intelligence capabilities of existing VLMs in UAV scenarios remain largely unexplored, raising concerns about their effectiveness in navigating and interpreting dynamic environments. To bridge this gap, we introduce SpatialSky-Bench, a comprehensive benchmark specifically designed to evaluate the spatial intelligence capabilities of VLMs in UAV navigation. Our benchmark comprises two categories-Environmental Perception and Scene Understanding-divided into 13 subcategories, including bounding boxes, color, distance, height, and landing safety analysis, among others. Extensive evaluations of various mainstream open-source and closed-source VLMs reveal unsatisfactory performance in complex UAV navigation scenarios, highlighting significant gaps in their spatial capabilities. To address this challenge, we developed the SpatialSky-Dataset, a comprehensive dataset containing 1M samples with diverse annotations across various scenarios. Leveraging this dataset, we introduce Sky-VLM, a specialized VLM designed for UAV spatial reasoning across multiple granularities and contexts. Extensive experimental results demonstrate that Sky-VLM achieves state-of-the-art performance across all benchmark tasks, paving the way for the development of VLMs suitable for UAV scenarios. The source code is available at https://github.com/linglingxiansen/SpatialSKy.
RoboAfford++: A Generative AI-Enhanced Dataset for Multimodal Affordance Learning in Robotic Manipulation and Navigation
Nov 16, 2025Robotic manipulation and navigation are fundamental capabilities of embodied intelligence, enabling effective robot interactions with the physical world. Achieving these capabilities requires a cohesive understanding of the environment, including object recognition to localize target objects, object affordances to identify potential interaction areas and spatial affordances to discern optimal areas for both object placement and robot movement. While Vision-Language Models (VLMs) excel at high-level task planning and scene understanding, they often struggle to infer actionable positions for physical interaction, such as functional grasping points and permissible placement regions. This limitation stems from the lack of fine-grained annotations for object and spatial affordances in their training datasets. To tackle this challenge, we introduce RoboAfford++, a generative AI-enhanced dataset for multimodal affordance learning for both robotic manipulation and navigation. Our dataset comprises 869,987 images paired with 2.0 million question answering (QA) annotations, covering three critical tasks: object affordance recognition to identify target objects based on attributes and spatial relationships, object affordance prediction to pinpoint functional parts for manipulation, and spatial affordance localization to identify free space for object placement and robot navigation. Complementing this dataset, we propose RoboAfford-Eval, a comprehensive benchmark for assessing affordance-aware prediction in real-world scenarios, featuring 338 meticulously annotated samples across the same three tasks. Extensive experimental results reveal the deficiencies of existing VLMs in affordance learning, while fine-tuning on the RoboAfford++ dataset significantly enhances their ability to reason about object and spatial affordances, validating the dataset's effectiveness.
Team Xiaomi EV-AD VLA: Learning to Navigate Socially Through Proactive Risk Perception - Technical Report for IROS 2025 RoboSense Challenge Social Navigation Track
Oct 09, 2025In this report, we describe the technical details of our submission to the IROS 2025 RoboSense Challenge Social Navigation Track. This track focuses on developing RGBD-based perception and navigation systems that enable autonomous agents to navigate safely, efficiently, and socially compliantly in dynamic human-populated indoor environments. The challenge requires agents to operate from an egocentric perspective using only onboard sensors including RGB-D observations and odometry, without access to global maps or privileged information, while maintaining social norm compliance such as safe distances and collision avoidance. Building upon the Falcon model, we introduce a Proactive Risk Perception Module to enhance social navigation performance. Our approach augments Falcon with collision risk understanding that learns to predict distance-based collision risk scores for surrounding humans, which enables the agent to develop more robust spatial awareness and proactive collision avoidance behaviors. The evaluation on the Social-HM3D benchmark demonstrates that our method improves the agent's ability to maintain personal space compliance while navigating toward goals in crowded indoor scenes with dynamic human agents, achieving 2nd place among 16 participating teams in the challenge.
$NavA^3$: Understanding Any Instruction, Navigating Anywhere, Finding Anything
Aug 06, 2025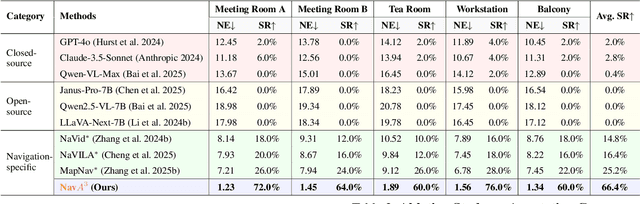
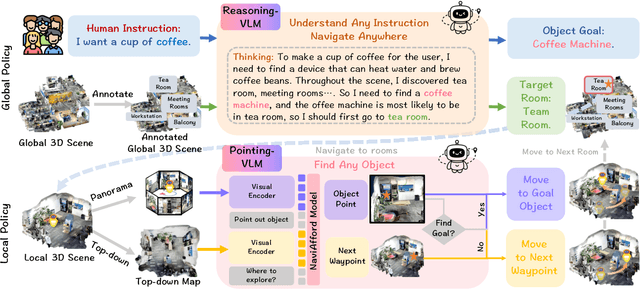
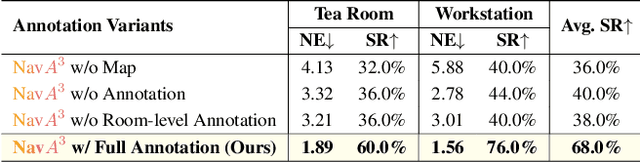
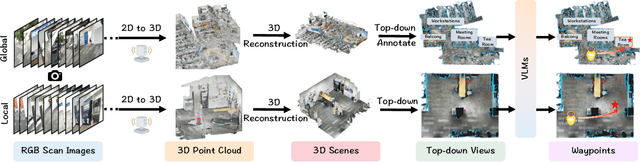
Embodied navigation is a fundamental capability of embodied intelligence, enabling robots to move and interact within physical environments. However, existing navigation tasks primarily focus on predefined object navigation or instruction following, which significantly differs from human needs in real-world scenarios involving complex, open-ended scenes. To bridge this gap, we introduce a challenging long-horizon navigation task that requires understanding high-level human instructions and performing spatial-aware object navigation in real-world environments. Existing embodied navigation methods struggle with such tasks due to their limitations in comprehending high-level human instructions and localizing objects with an open vocabulary. In this paper, we propose $NavA^3$, a hierarchical framework divided into two stages: global and local policies. In the global policy, we leverage the reasoning capabilities of Reasoning-VLM to parse high-level human instructions and integrate them with global 3D scene views. This allows us to reason and navigate to regions most likely to contain the goal object. In the local policy, we have collected a dataset of 1.0 million samples of spatial-aware object affordances to train the NaviAfford model (PointingVLM), which provides robust open-vocabulary object localization and spatial awareness for precise goal identification and navigation in complex environments. Extensive experiments demonstrate that $NavA^3$ achieves SOTA results in navigation performance and can successfully complete longhorizon navigation tasks across different robot embodiments in real-world settings, paving the way for universal embodied navigation. The dataset and code will be made available. Project website: https://NavigationA3.github.io/.
RoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.
Video-CoT: A Comprehensive Dataset for Spatiotemporal Understanding of Videos Based on Chain-of-Thought
Jun 12, 2025



Video content comprehension is essential for various applications, ranging from video analysis to interactive systems. Despite advancements in large-scale vision-language models (VLMs), these models often struggle to capture the nuanced, spatiotemporal details essential for thorough video analysis. To address this gap, we introduce Video-CoT, a groundbreaking dataset designed to enhance spatiotemporal understanding using Chain-of-Thought (CoT) methodologies. Video-CoT contains 192,000 fine-grained spa-tiotemporal question-answer pairs and 23,000 high-quality CoT-annotated samples, providing a solid foundation for evaluating spatiotemporal understanding in video comprehension. Additionally, we provide a comprehensive benchmark for assessing these tasks, with each task featuring 750 images and tailored evaluation metrics. Our extensive experiments reveal that current VLMs face significant challenges in achieving satisfactory performance, high-lighting the difficulties of effective spatiotemporal understanding. Overall, the Video-CoT dataset and benchmark open new avenues for research in multimedia understanding and support future innovations in intelligent systems requiring advanced video analysis capabilities. By making these resources publicly available, we aim to encourage further exploration in this critical area. Project website:https://video-cot.github.io/ .