 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneVLA: A Unified Framework for Embodied Tasks
May 31, 2026Navigation and manipulation are fundamental capabilities of embodied intelligence, enabling robots to interpret natural language commands and interact physically with their surroundings. However, current Vision-Language-Action (VLA) models remain constrained by task-specific architectures, specializing in either navigation or manipulation, which hinders the development of general-purpose robotic agents. To bridge this gap, we introduce OneVLA, a unified architecture that integrates these distinct tasks into a single, cohesive framework. Specifically, we design a unified action head capable of generating both navigation and manipulation actions without requiring task-specific variants. Furthermore, we propose a multi stage progressive training strategy-incorporating curated data construction and Chain-of-Thought (CoT) fine-tuning that facilitates strong positive transfer and mutual reinforcement between the two domains. Extensive experiments in both simulated and real-world environments demonstrate that OneVLA achieves state-of-the-art performance, significantly outperforming both specialized single-task and existing cross-task models. By unifying these core capabilities, OneVLA paves the way for truly general-purpose robotic systems. The model and source code will be publicly released.
FlexiCup: Wireless Multimodal Suction Cup with Dual-Zone Vision-Tactile Sensing
Nov 18, 2025



Conventional suction cups lack sensing capabilities for contact-aware manipulation in unstructured environments. This paper presents FlexiCup, a fully wireless multimodal suction cup that integrates dual-zone vision-tactile sensing. The central zone dynamically switches between vision and tactile modalities via illumination control for contact detection, while the peripheral zone provides continuous spatial awareness for approach planning. FlexiCup supports both vacuum and Bernoulli suction modes through modular mechanical configurations, achieving complete wireless autonomy with onboard computation and power. We validate hardware versatility through dual control paradigms. Modular perception-driven grasping across structured surfaces with varying obstacle densities demonstrates comparable performance between vacuum (90.0% mean success) and Bernoulli (86.7% mean success) modes. Diffusion-based end-to-end learning achieves 73.3% success on inclined transport and 66.7% on orange extraction tasks. Ablation studies confirm that multi-head attention coordinating dual-zone observations provides 13% improvements for contact-aware manipulation. Hardware designs and firmware are available at https://anonymous.4open.science/api/repo/FlexiCup-DA7D/file/index.html?v=8f531b44.
SocialNav-Map: Dynamic Mapping with Human Trajectory Prediction for Zero-Shot Social Navigation
Nov 18, 2025Social navigation in densely populated dynamic environments poses a significant challenge for autonomous mobile robots, requiring advanced strategies for safe interaction. Existing reinforcement learning (RL)-based methods require over 2000+ hours of extensive training and often struggle to generalize to unfamiliar environments without additional fine-tuning, limiting their practical application in real-world scenarios. To address these limitations, we propose SocialNav-Map, a novel zero-shot social navigation framework that combines dynamic human trajectory prediction with occupancy mapping, enabling safe and efficient navigation without the need for environment-specific training. Specifically, SocialNav-Map first transforms the task goal position into the constructed map coordinate system. Subsequently, it creates a dynamic occupancy map that incorporates predicted human movements as dynamic obstacles. The framework employs two complementary methods for human trajectory prediction: history prediction and orientation prediction. By integrating these predicted trajectories into the occupancy map, the robot can proactively avoid potential collisions with humans while efficiently navigating to its destination. Extensive experiments on the Social-HM3D and Social-MP3D datasets demonstrate that SocialNav-Map significantly outperforms state-of-the-art (SOTA) RL-based methods, which require 2,396 GPU hours of training. Notably, it reduces human collision rates by over 10% without necessitating any training in novel environments. By eliminating the need for environment-specific training, SocialNav-Map achieves superior navigation performance, paving the way for the deployment of social navigation systems in real-world environments characterized by diverse human behaviors. The code is available at: https://github.com/linglingxiansen/SocialNav-Map.
Is your VLM Sky-Ready? A Comprehensive Spatial Intelligence Benchmark for UAV Navigation
Nov 17, 2025



Vision-Language Models (VLMs), leveraging their powerful visual perception and reasoning capabilities, have been widely applied in Unmanned Aerial Vehicle (UAV) tasks. However, the spatial intelligence capabilities of existing VLMs in UAV scenarios remain largely unexplored, raising concerns about their effectiveness in navigating and interpreting dynamic environments. To bridge this gap, we introduce SpatialSky-Bench, a comprehensive benchmark specifically designed to evaluate the spatial intelligence capabilities of VLMs in UAV navigation. Our benchmark comprises two categories-Environmental Perception and Scene Understanding-divided into 13 subcategories, including bounding boxes, color, distance, height, and landing safety analysis, among others. Extensive evaluations of various mainstream open-source and closed-source VLMs reveal unsatisfactory performance in complex UAV navigation scenarios, highlighting significant gaps in their spatial capabilities. To address this challenge, we developed the SpatialSky-Dataset, a comprehensive dataset containing 1M samples with diverse annotations across various scenarios. Leveraging this dataset, we introduce Sky-VLM, a specialized VLM designed for UAV spatial reasoning across multiple granularities and contexts. Extensive experimental results demonstrate that Sky-VLM achieves state-of-the-art performance across all benchmark tasks, paving the way for the development of VLMs suitable for UAV scenarios. The source code is available at https://github.com/linglingxiansen/SpatialSKy.
Sample-efficient diffusion-based control of complex nonlinear systems
Feb 25, 2025Complex nonlinear system control faces challenges in achieving sample-efficient, reliable performance. While diffusion-based methods have demonstrated advantages over classical and reinforcement learning approaches in long-term control performance, they are limited by sample efficiency. This paper presents SEDC (Sample-Efficient Diffusion-based Control), a novel diffusion-based control framework addressing three core challenges: high-dimensional state-action spaces, nonlinear system dynamics, and the gap between non-optimal training data and near-optimal control solutions. Through three innovations - Decoupled State Diffusion, Dual-Mode Decomposition, and Guided Self-finetuning - SEDC achieves 39.5\%-49.4\% better control accuracy than baselines while using only 10\% of the training samples, as validated across three complex nonlinear dynamic systems. Our approach represents a significant advancement in sample-efficient control of complex nonlinear systems. The implementation of the code can be found at https://anonymous.4open.science/r/DIFOCON-C019.
Structure-prior Informed Diffusion Model for Graph Source Localization with Limited Data
Feb 25, 2025The source localization problem in graph information propagation is crucial for managing various network disruptions, from misinformation spread to infrastructure failures. While recent deep generative approaches have shown promise in this domain, their effectiveness is limited by the scarcity of real-world propagation data. This paper introduces SIDSL (\textbf{S}tructure-prior \textbf{I}nformed \textbf{D}iffusion model for \textbf{S}ource \textbf{L}ocalization), a novel framework that addresses three key challenges in limited-data scenarios: unknown propagation patterns, complex topology-propagation relationships, and class imbalance between source and non-source nodes. SIDSL incorporates topology-aware priors through graph label propagation and employs a propagation-enhanced conditional denoiser with a GNN-parameterized label propagation module (GNN-LP). Additionally, we propose a structure-prior biased denoising scheme that initializes from structure-based source estimations rather than random noise, effectively countering class imbalance issues. Experimental results across four real-world datasets demonstrate SIDSL's superior performance, achieving 7.5-13.3% improvements in F1 scores compared to state-of-the-art methods. Notably, when pretrained with simulation data of synthetic patterns, SIDSL maintains robust performance with only 10% of training data, surpassing baselines by more than 18.8%. These results highlight SIDSL's effectiveness in real-world applications where labeled data is scarce.
Spatial-temporal associations representation and application for process monitoring using graph convolution neural network
May 11, 2022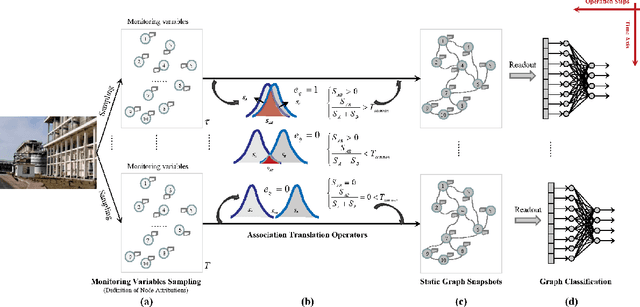
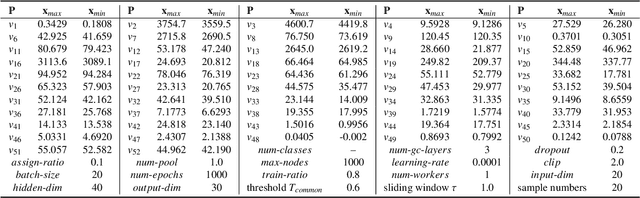
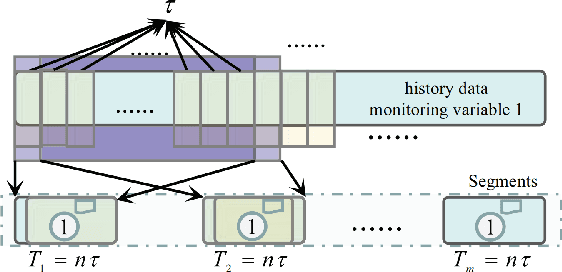

Industrial process data reflects the dynamic changes of operation conditions, which mainly refer to the irregular changes in the dynamic associations between different variables in different time. And this related associations knowledge for process monitoring is often implicit in these dynamic monitoring data which always have richer operation condition information and have not been paid enough attention in current research. To this end, a new process monitoring method based on spatial-based graph convolution neural network (SGCN) is proposed to describe the characteristics of the dynamic associations which can be used to represent the operation status over time. Spatia-temporal graphs are firstly defined, which can be used to represent the characteristics of node attributes (dynamic edge features) dynamically changing with time. Then, the associations between monitoring variables at a certain time can be considered as the node attributes to define a snapshot of the static graph network at the certain time. Finally, the snapshot containing graph structure and node attributes is used as model inputs which are processed to implement graph classification by spatial-based convolution graph neural network with aggregate and readout steps. The feasibility and applicability of this proposed method are demonstrated by our experimental results of benchmark and practical case application.