 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Terrain-Aware Whole-Body Control for Perceptive Legged Loco-Manipulation
May 29, 2026Legged manipulators integrate exceptional terrain adaptability along with mobile manipulation capabilities, which make them highly promising for deployment in human-centric environments. By coordinating the control of both legs and arms, a whole-body controller can significantly expand the operational workspace of legged manipulators. However, many existing whole-body controllers primarily depend on proprioception and do not incorporate the critical exteroception required for effective terrain topology perception. This limitation can hinder their ability to adapt to varying environmental conditions and navigate complex terrains effectively. In this paper, we introduce TA-WBC, a terrain-aware whole-body control framework for legged manipulators, which features a novel RL-based unified policy tailored to whole-body loco-manipulation tasks in various terrains. Specifically, we employ a hybrid exteroception encoder to extract terrain features, providing an essential basis for the robot to proactively adapt posture and footholds. Furthermore, to facilitate stable cross-terrain loco-manipulation, we propose a novel end-effector sampling method based on the foot contact plane, decoupling manipulation target from base fluctuations. Moreover, a dual-policy distillation module is introduced to integrate expansive whole-body motion with terrain adaptability without catastrophic forgetting. The simulation and real-world experiments validate the robustness of our proposed controller, which leads to a larger reachable space, less tracking error, and reduced unexpected stumbles. This unified policy highlights the promising capabilities of legged manipulators in performing loco-manipulation tasks across complex terrains.
Traffic Sign Recognition in Autonomous Driving: Dataset, Benchmark, and Field Experiment
Mar 24, 2026Traffic Sign Recognition (TSR) is a core perception capability for autonomous driving, where robustness to cross-region variation, long-tailed categories, and semantic ambiguity is essential for reliable real-world deployment. Despite steady progress in recognition accuracy, existing traffic sign datasets and benchmarks offer limited diagnostic insight into how different modeling paradigms behave under these practical challenges. We present TS-1M, a large-scale and globally diverse traffic sign dataset comprising over one million real-world images across 454 standardized categories, together with a diagnostic benchmark designed to analyze model capability boundaries. Beyond standard train-test evaluation, we provide a suite of challenge-oriented settings, including cross-region recognition, rare-class identification, low-clarity robustness, and semantic text understanding, enabling systematic and fine-grained assessment of modern TSR models. Using TS-1M, we conduct a unified benchmark across three representative learning paradigms: classical supervised models, self-supervised pretrained models, and multimodal vision-language models (VLMs). Our analysis reveals consistent paradigm-dependent behaviors, showing that semantic alignment is a key factor for cross-region generalization and rare-category recognition, while purely visual models remain sensitive to appearance shift and data imbalance. Finally, we validate the practical relevance of TS-1M through real-scene autonomous driving experiments, where traffic sign recognition is integrated with semantic reasoning and spatial localization to support map-level decision constraints. Overall, TS-1M establishes a reference-level diagnostic benchmark for TSR and provides principled insights into robust and semantic-aware traffic sign perception. Project page: https://guoyangzhao.github.io/projects/ts1m.
FLUX: Accelerating Cross-Embodiment Generative Navigation Policies via Rectified Flow and Static-to-Dynamic Learning
Mar 13, 2026Autonomous navigation requires a broad spectrum of skills, from static goal-reaching to dynamic social traversal, yet evaluation remains fragmented across disparate protocols. We introduce DynBench, a dynamic navigation benchmark featuring physically valid crowd simulation. Combined with existing static protocols, it supports comprehensive evaluation across six fundamental navigation tasks. Within this framework, we propose FLUX, the first flow-based unified navigation policy. By linearizing probability flow, FLUX replaces iterative denoising with straight-line trajectories, improving per-step inference efficiency by 47% over prior flow-based methods and 29% over diffusion-based ones. Following a static-to-dynamic curriculum, FLUX initially establishes geometric priors and is subsequently refined through reinforcement learning in dynamic social environments. This regime not only strengthens socially-aware navigation but also enhances static task robustness by capturing recovery behaviors through stochastic action distributions. FLUX achieves state-of-the-art performance across all tasks and demonstrates zero-shot sim-to-real transfer on wheeled, quadrupedal, and humanoid platforms without any fine-tuning.
Real-to-Sim for Highly Cluttered Environments via Physics-Consistent Inter-Object Reasoning
Feb 13, 2026Reconstructing physically valid 3D scenes from single-view observations is a prerequisite for bridging the gap between visual perception and robotic control. However, in scenarios requiring precise contact reasoning, such as robotic manipulation in highly cluttered environments, geometric fidelity alone is insufficient. Standard perception pipelines often neglect physical constraints, resulting in invalid states, e.g., floating objects or severe inter-penetration, rendering downstream simulation unreliable. To address these limitations, we propose a novel physics-constrained Real-to-Sim pipeline that reconstructs physically consistent 3D scenes from single-view RGB-D data. Central to our approach is a differentiable optimization pipeline that explicitly models spatial dependencies via a contact graph, jointly refining object poses and physical properties through differentiable rigid-body simulation. Extensive evaluations in both simulation and real-world settings demonstrate that our reconstructed scenes achieve high physical fidelity and faithfully replicate real-world contact dynamics, enabling stable and reliable contact-rich manipulation.
ALORE: Autonomous Large-Object Rearrangement with a Legged Manipulator
Feb 04, 2026Endowing robots with the ability to rearrange various large and heavy objects, such as furniture, can substantially alleviate human workload. However, this task is extremely challenging due to the need to interact with diverse objects and efficiently rearrange multiple objects in complex environments while ensuring collision-free loco-manipulation. In this work, we present ALORE, an autonomous large-object rearrangement system for a legged manipulator that can rearrange various large objects across diverse scenarios. The proposed system is characterized by three main features: (i) a hierarchical reinforcement learning training pipeline for multi-object environment learning, where a high-level object velocity controller is trained on top of a low-level whole-body controller to achieve efficient and stable joint learning across multiple objects; (ii) two key modules, a unified interaction configuration representation and an object velocity estimator, that allow a single policy to regulate planar velocity of diverse objects accurately; and (iii) a task-and-motion planning framework that jointly optimizes object visitation order and object-to-target assignment, improving task efficiency while enabling online replanning. Comparisons against strong baselines show consistent superiority in policy generalization, object-velocity tracking accuracy, and multi-object rearrangement efficiency. Key modules are systematically evaluated, and extensive simulations and real-world experiments are conducted to validate the robustness and effectiveness of the entire system, which successfully completes 8 continuous loops to rearrange 32 chairs over nearly 40 minutes without a single failure, and executes long-distance autonomous rearrangement over an approximately 40 m route. The open-source packages are available at https://zhihaibi.github.io/Alore/.
Vision-Language-Action Models for Autonomous Driving: Past, Present, and Future
Dec 18, 2025Autonomous driving has long relied on modular "Perception-Decision-Action" pipelines, where hand-crafted interfaces and rule-based components often break down in complex or long-tailed scenarios. Their cascaded design further propagates perception errors, degrading downstream planning and control. Vision-Action (VA) models address some limitations by learning direct mappings from visual inputs to actions, but they remain opaque, sensitive to distribution shifts, and lack structured reasoning or instruction-following capabilities. Recent progress in Large Language Models (LLMs) and multimodal learning has motivated the emergence of Vision-Language-Action (VLA) frameworks, which integrate perception with language-grounded decision making. By unifying visual understanding, linguistic reasoning, and actionable outputs, VLAs offer a pathway toward more interpretable, generalizable, and human-aligned driving policies. This work provides a structured characterization of the emerging VLA landscape for autonomous driving. We trace the evolution from early VA approaches to modern VLA frameworks and organize existing methods into two principal paradigms: End-to-End VLA, which integrates perception, reasoning, and planning within a single model, and Dual-System VLA, which separates slow deliberation (via VLMs) from fast, safety-critical execution (via planners). Within these paradigms, we further distinguish subclasses such as textual vs. numerical action generators and explicit vs. implicit guidance mechanisms. We also summarize representative datasets and benchmarks for evaluating VLA-based driving systems and highlight key challenges and open directions, including robustness, interpretability, and instruction fidelity. Overall, this work aims to establish a coherent foundation for advancing human-compatible autonomous driving systems.
GP3: A 3D Geometry-Aware Policy with Multi-View Images for Robotic Manipulation
Sep 19, 2025



Effective robotic manipulation relies on a precise understanding of 3D scene geometry, and one of the most straightforward ways to acquire such geometry is through multi-view observations. Motivated by this, we present GP3 -- a 3D geometry-aware robotic manipulation policy that leverages multi-view input. GP3 employs a spatial encoder to infer dense spatial features from RGB observations, which enable the estimation of depth and camera parameters, leading to a compact yet expressive 3D scene representation tailored for manipulation. This representation is fused with language instructions and translated into continuous actions via a lightweight policy head. Comprehensive experiments demonstrate that GP3 consistently outperforms state-of-the-art methods on simulated benchmarks. Furthermore, GP3 transfers effectively to real-world robots without depth sensors or pre-mapped environments, requiring only minimal fine-tuning. These results highlight GP3 as a practical, sensor-agnostic solution for geometry-aware robotic manipulation.
Motion-Coupled Mapping Algorithm for Hybrid Rice Canopy
Feb 22, 2025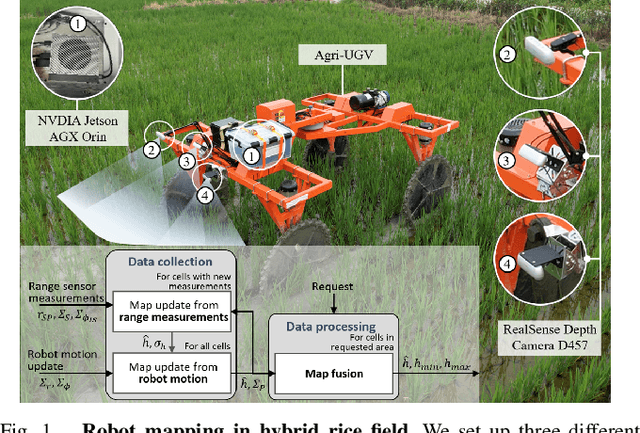
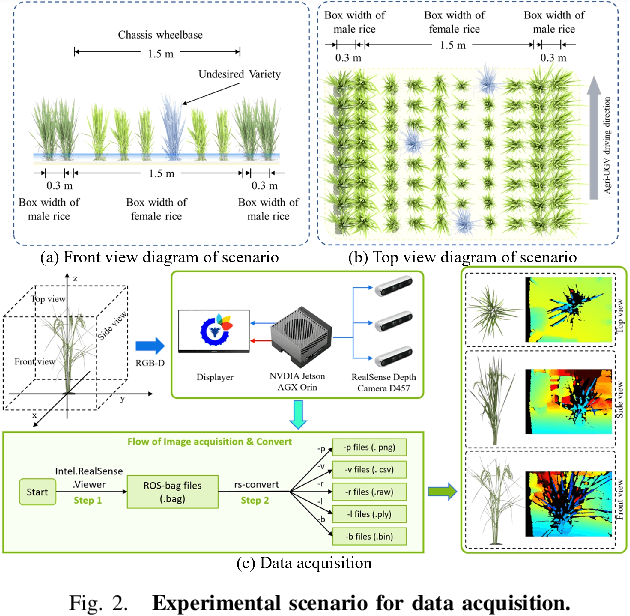
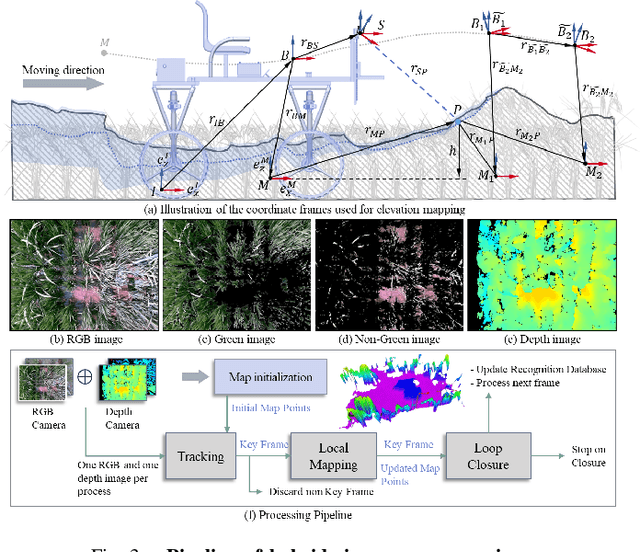
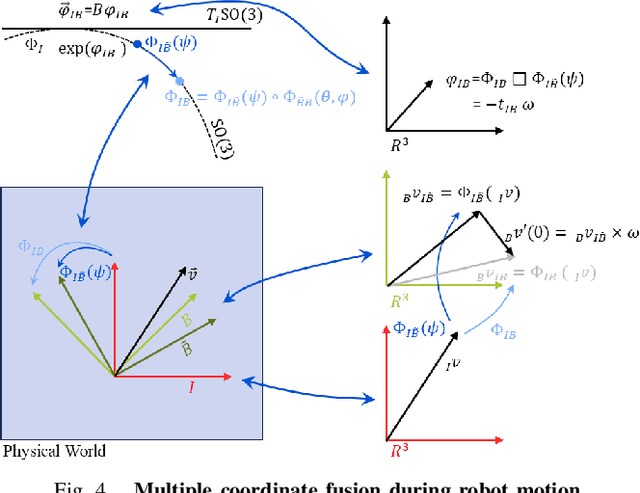
This paper presents a motion-coupled mapping algorithm for contour mapping of hybrid rice canopies, specifically designed for Agricultural Unmanned Ground Vehicles (Agri-UGV) navigating complex and unknown rice fields. Precise canopy mapping is essential for Agri-UGVs to plan efficient routes and avoid protected zones. The motion control of Agri-UGVs, tasked with impurity removal and other operations, depends heavily on accurate estimation of rice canopy height and structure. To achieve this, the proposed algorithm integrates real-time RGB-D sensor data with kinematic and inertial measurements, enabling efficient mapping and proprioceptive localization. The algorithm produces grid-based elevation maps that reflect the probabilistic distribution of canopy contours, accounting for motion-induced uncertainties. It is implemented on a high-clearance Agri-UGV platform and tested in various environments, including both controlled and dynamic rice field settings. This approach significantly enhances the mapping accuracy and operational reliability of Agri-UGVs, contributing to more efficient autonomous agricultural operations.
* Best Paper Award First Place - IROS 2024 Workshop on AI and Robotics For Future Farming
Task-Oriented Pre-Training for Drivable Area Detection
Sep 30, 2024



Pre-training techniques play a crucial role in deep learning, enhancing models' performance across a variety of tasks. By initially training on large datasets and subsequently fine-tuning on task-specific data, pre-training provides a solid foundation for models, improving generalization abilities and accelerating convergence rates. This approach has seen significant success in the fields of natural language processing and computer vision. However, traditional pre-training methods necessitate large datasets and substantial computational resources, and they can only learn shared features through prolonged training and struggle to capture deeper, task-specific features. In this paper, we propose a task-oriented pre-training method that begins with generating redundant segmentation proposals using the Segment Anything (SAM) model. We then introduce a Specific Category Enhancement Fine-tuning (SCEF) strategy for fine-tuning the Contrastive Language-Image Pre-training (CLIP) model to select proposals most closely related to the drivable area from those generated by SAM. This approach can generate a lot of coarse training data for pre-training models, which are further fine-tuned using manually annotated data, thereby improving model's performance. Comprehensive experiments conducted on the KITTI road dataset demonstrate that our task-oriented pre-training method achieves an all-around performance improvement compared to models without pre-training. Moreover, our pre-training method not only surpasses traditional pre-training approach but also achieves the best performance compared to state-of-the-art self-training methods.
Erase, then Redraw: A Novel Data Augmentation Approach for Free Space Detection Using Diffusion Model
Sep 30, 2024



Data augmentation is one of the most common tools in deep learning, underpinning many recent advances including tasks such as classification, detection, and semantic segmentation. The standard approach to data augmentation involves simple transformations like rotation and flipping to generate new images. However, these new images often lack diversity along the main semantic dimensions within the data. Traditional data augmentation methods cannot alter high-level semantic attributes such as the presence of vehicles, trees, and buildings in a scene to enhance data diversity. In recent years, the rapid development of generative models has injected new vitality into the field of data augmentation. In this paper, we address the lack of diversity in data augmentation for road detection task by using a pre-trained text-to-image diffusion model to parameterize image-to-image transformations. Our method involves editing images using these diffusion models to change their semantics. In essence, we achieve this goal by erasing instances of real objects from the original dataset and generating new instances with similar semantics in the erased regions using the diffusion model, thereby expanding the original dataset. We evaluate our approach on the KITTI road dataset and achieve the best results compared to other data augmentation methods, which demonstrates the effectiveness of our proposed development.