 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEF-MAP: Subspace-Decomposed Expert Fusion for Robust Multimodal HD Map Prediction
Feb 25, 2026High-definition (HD) maps are essential for autonomous driving, yet multi-modal fusion often suffers from inconsistency between camera and LiDAR modalities, leading to performance degradation under low-light conditions, occlusions, or sparse point clouds. To address this, we propose SEFMAP, a Subspace-Expert Fusion framework for robust multimodal HD map prediction. The key idea is to explicitly disentangle BEV features into four semantic subspaces: LiDAR-private, Image-private, Shared, and Interaction. Each subspace is assigned a dedicated expert, thereby preserving modality-specific cues while capturing cross-modal consensus. To adaptively combine expert outputs, we introduce an uncertainty-aware gating mechanism at the BEV-cell level, where unreliable experts are down-weighted based on predictive variance, complemented by a usage balance regularizer to prevent expert collapse. To enhance robustness in degraded conditions and promote role specialization, we further propose distribution-aware masking: during training, modality-drop scenarios are simulated using EMA-statistical surrogate features, and a specialization loss enforces distinct behaviors of private, shared, and interaction experts across complete and masked inputs. Experiments on nuScenes and Argoverse2 benchmarks demonstrate that SEFMAP achieves state-of-the-art performance, surpassing prior methods by +4.2% and +4.8% in mAP, respectively. SEF-MAPprovides a robust and effective solution for multi-modal HD map prediction under diverse and degraded conditions.
Improving Monocular Visual Odometry Using Learned Depth
Apr 04, 2022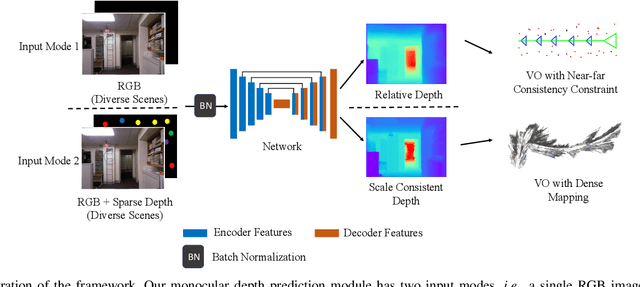
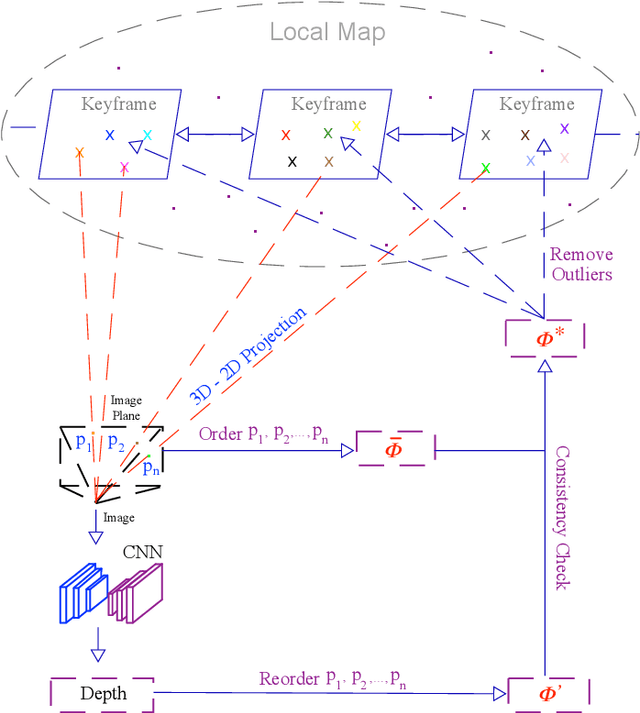
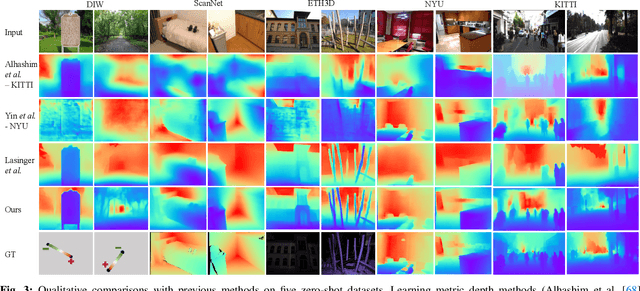
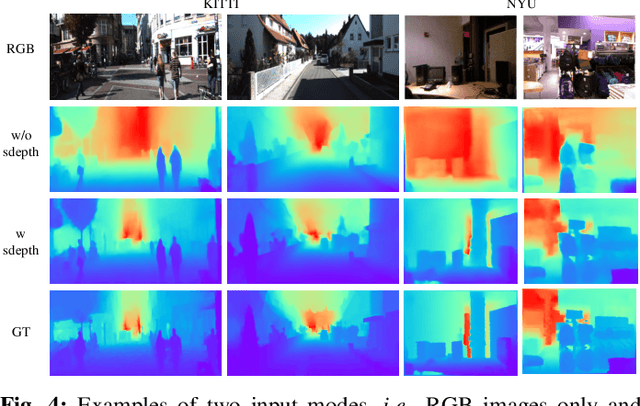
Monocular visual odometry (VO) is an important task in robotics and computer vision. Thus far, how to build accurate and robust monocular VO systems that can work well in diverse scenarios remains largely unsolved. In this paper, we propose a framework to exploit monocular depth estimation for improving VO. The core of our framework is a monocular depth estimation module with a strong generalization capability for diverse scenes. It consists of two separate working modes to assist the localization and mapping. With a single monocular image input, the depth estimation module predicts a relative depth to help the localization module on improving the accuracy. With a sparse depth map and an RGB image input, the depth estimation module can generate accurate scale-consistent depth for dense mapping. Compared with current learning-based VO methods, our method demonstrates a stronger generalization ability to diverse scenes. More significantly, our framework is able to boost the performances of existing geometry-based VO methods by a large margin.