 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotPan: A 360$^\circ$ Surround-View Robotic Vision System for Embodied Perception
Apr 15, 2026Surround-view perception is increasingly important for robotic navigation and loco-manipulation, especially in human-in-the-loop settings such as teleoperation, data collection, and emergency takeover. However, current robotic visual interfaces are often limited to narrow forward-facing views, or, when multiple on-board cameras are available, require cumbersome manual switching that interrupts the operator's workflow. Both configurations suffer from motion-induced jitter that causes simulator sickness in head-mounted displays. We introduce a surround-view robotic vision system that combines six cameras with LiDAR to provide full 360$^\circ$ visual coverage, while meeting the geometric and real-time constraints of embodied deployment. We further present \textsc{RobotPan}, a feed-forward framework that predicts \emph{metric-scaled} and \emph{compact} 3D Gaussians from calibrated sparse-view inputs for real-time rendering, reconstruction, and streaming. \textsc{RobotPan} lifts multi-view features into a unified spherical coordinate representation and decodes Gaussians using hierarchical spherical voxel priors, allocating fine resolution near the robot and coarser resolution at larger radii to reduce computational redundancy without sacrificing fidelity. To support long sequences, our online fusion updates dynamic content while preventing unbounded growth in static regions by selectively updating appearance. Finally, we release a multi-sensor dataset tailored to 360$^\circ$ novel view synthesis and metric 3D reconstruction for robotics, covering navigation, manipulation, and locomotion on real platforms. Experiments show that \textsc{RobotPan} achieves competitive quality against prior feed-forward reconstruction and view-synthesis methods while producing substantially fewer Gaussians, enabling practical real-time embodied deployment. Project website: https://robotpan.github.io/
Heracles: Bridging Precise Tracking and Generative Synthesis for General Humanoid Control
Mar 31, 2026Achieving general-purpose humanoid control requires a delicate balance between the precise execution of commanded motions and the flexible, anthropomorphic adaptability needed to recover from unpredictable environmental perturbations. Current general controllers predominantly formulate motion control as a rigid reference-tracking problem. While effective in nominal conditions, these trackers often exhibit brittle, non-anthropomorphic failure modes under severe disturbances, lacking the generative adaptability inherent to human motor control. To overcome this limitation, we propose Heracles, a novel state-conditioned diffusion middleware that bridges precise motion tracking and generative synthesis. Rather than relying on rigid tracking paradigms or complex explicit mode-switching, Heracles operates as an intermediary layer between high-level reference motions and low-level physics trackers. By conditioning on the robot's real-time state, the diffusion model implicitly adapts its behavior: it approximates an identity map when the state closely aligns with the reference, preserving zero-shot tracking fidelity. Conversely, when encountering significant state deviations, it seamlessly transitions into a generative synthesizer to produce natural, anthropomorphic recovery trajectories. Our framework demonstrates that integrating generative priors into the control loop not only significantly enhances robustness against extreme perturbations but also elevates humanoid control from a rigid tracking paradigm to an open-ended, generative general-purpose architecture.
SynLeaF: A Dual-Stage Multimodal Fusion Framework for Synthetic Lethality Prediction Across Pan- and Single-Cancer Contexts
Mar 23, 2026Accurate prediction of synthetic lethality (SL) is important for guiding the development of cancer drugs and therapies. SL prediction faces significant challenges in the effective fusion of heterogeneous multi-source data. Existing multimodal methods often suffer from "modality laziness" due to disparate convergence speeds, which hinders the exploitation of complementary information. This is also one reason why most existing SL prediction models cannot perform well on both pan-cancer and single-cancer SL pair prediction. In this study, we propose SynLeaF, a dual-stage multimodal fusion framework for SL prediction across pan- and single-cancer contexts. The framework employs a VAE-based cross-encoder with a product of experts mechanism to fuse four omics data types (gene expression, mutation, methylation, and CNV), while simultaneously utilizing a relational graph convolutional network to capture structured gene representations from biomedical knowledge graphs. To mitigate modality laziness, SynLeaF introduces a dual-stage training mechanism employing featurelevel knowledge distillation with adaptive uni-modal teacher and ensemble strategies. In extensive experiments across eight specific cancer types and a pancancer dataset, SynLeaF achieves superior performance in 17 out of 19 scenarios. Ablation studies and gradient analyses further validate the critical contributions of the proposed fusion and distillation mechanisms to model robustness and generalization. To facilitate community use, a web server is available at https://synleaf.bioinformatics-lilab.cn.
MeshMimic: Geometry-Aware Humanoid Motion Learning through 3D Scene Reconstruction
Feb 17, 2026Humanoid motion control has witnessed significant breakthroughs in recent years, with deep reinforcement learning (RL) emerging as a primary catalyst for achieving complex, human-like behaviors. However, the high dimensionality and intricate dynamics of humanoid robots make manual motion design impractical, leading to a heavy reliance on expensive motion capture (MoCap) data. These datasets are not only costly to acquire but also frequently lack the necessary geometric context of the surrounding physical environment. Consequently, existing motion synthesis frameworks often suffer from a decoupling of motion and scene, resulting in physical inconsistencies such as contact slippage or mesh penetration during terrain-aware tasks. In this work, we present MeshMimic, an innovative framework that bridges 3D scene reconstruction and embodied intelligence to enable humanoid robots to learn coupled "motion-terrain" interactions directly from video. By leveraging state-of-the-art 3D vision models, our framework precisely segments and reconstructs both human trajectories and the underlying 3D geometry of terrains and objects. We introduce an optimization algorithm based on kinematic consistency to extract high-quality motion data from noisy visual reconstructions, alongside a contact-invariant retargeting method that transfers human-environment interaction features to the humanoid agent. Experimental results demonstrate that MeshMimic achieves robust, highly dynamic performance across diverse and challenging terrains. Our approach proves that a low-cost pipeline utilizing only consumer-grade monocular sensors can facilitate the training of complex physical interactions, offering a scalable path toward the autonomous evolution of humanoid robots in unstructured environments.
Humanoid Occupancy: Enabling A Generalized Multimodal Occupancy Perception System on Humanoid Robots
Jul 27, 2025Humanoid robot technology is advancing rapidly, with manufacturers introducing diverse heterogeneous visual perception modules tailored to specific scenarios. Among various perception paradigms, occupancy-based representation has become widely recognized as particularly suitable for humanoid robots, as it provides both rich semantic and 3D geometric information essential for comprehensive environmental understanding. In this work, we present Humanoid Occupancy, a generalized multimodal occupancy perception system that integrates hardware and software components, data acquisition devices, and a dedicated annotation pipeline. Our framework employs advanced multi-modal fusion techniques to generate grid-based occupancy outputs encoding both occupancy status and semantic labels, thereby enabling holistic environmental understanding for downstream tasks such as task planning and navigation. To address the unique challenges of humanoid robots, we overcome issues such as kinematic interference and occlusion, and establish an effective sensor layout strategy. Furthermore, we have developed the first panoramic occupancy dataset specifically for humanoid robots, offering a valuable benchmark and resource for future research and development in this domain. The network architecture incorporates multi-modal feature fusion and temporal information integration to ensure robust perception. Overall, Humanoid Occupancy delivers effective environmental perception for humanoid robots and establishes a technical foundation for standardizing universal visual modules, paving the way for the widespread deployment of humanoid robots in complex real-world scenarios.
SOAF: Scene Occlusion-aware Neural Acoustic Field
Jul 02, 2024



This paper tackles the problem of novel view audio-visual synthesis along an arbitrary trajectory in an indoor scene, given the audio-video recordings from other known trajectories of the scene. Existing methods often overlook the effect of room geometry, particularly wall occlusion to sound propagation, making them less accurate in multi-room environments. In this work, we propose a new approach called Scene Occlusion-aware Acoustic Field (SOAF) for accurate sound generation. Our approach derives a prior for sound energy field using distance-aware parametric sound-propagation modelling and then transforms it based on scene transmittance learned from the input video. We extract features from the local acoustic field centred around the receiver using a Fibonacci Sphere to generate binaural audio for novel views with a direction-aware attention mechanism. Extensive experiments on the real dataset~\emph{RWAVS} and the synthetic dataset~\emph{SoundSpaces} demonstrate that our method outperforms previous state-of-the-art techniques in audio generation. Project page: https://github.com/huiyu-gao/SOAF/.
HashPoint: Accelerated Point Searching and Sampling for Neural Rendering
Apr 22, 2024



In this paper, we address the problem of efficient point searching and sampling for volume neural rendering. Within this realm, two typical approaches are employed: rasterization and ray tracing. The rasterization-based methods enable real-time rendering at the cost of increased memory and lower fidelity. In contrast, the ray-tracing-based methods yield superior quality but demand longer rendering time. We solve this problem by our HashPoint method combining these two strategies, leveraging rasterization for efficient point searching and sampling, and ray marching for rendering. Our method optimizes point searching by rasterizing points within the camera's view, organizing them in a hash table, and facilitating rapid searches. Notably, we accelerate the rendering process by adaptive sampling on the primary surface encountered by the ray. Our approach yields substantial speed-up for a range of state-of-the-art ray-tracing-based methods, maintaining equivalent or superior accuracy across synthetic and real test datasets. The code will be available at https://jiahao-ma.github.io/hashpoint/.
* CVPR2024 Highlight
Simulation and application of COVID-19 compartment model using physic-informed neural network
Aug 04, 2022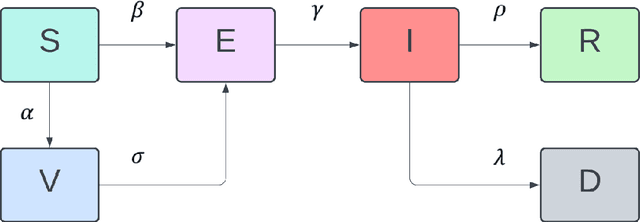
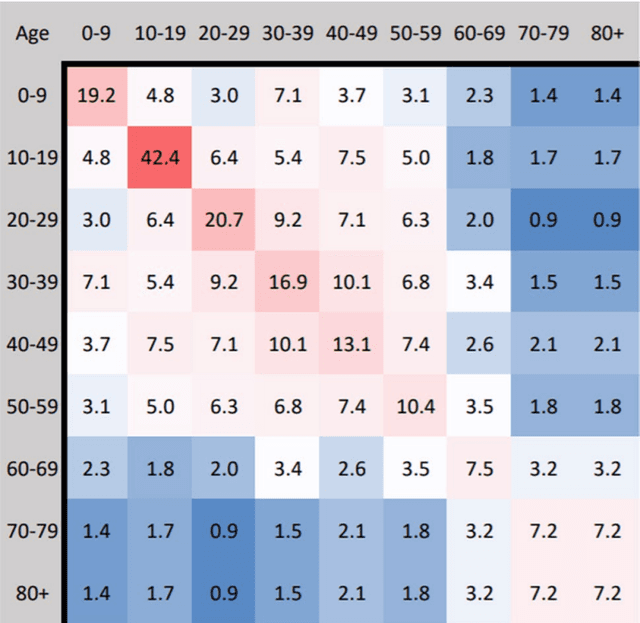
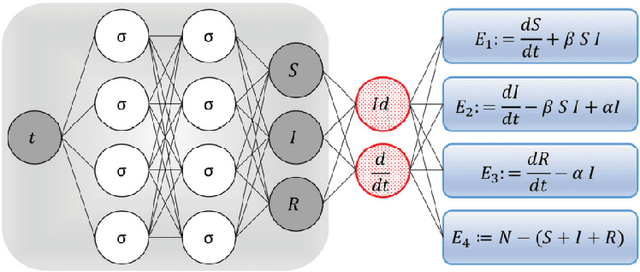
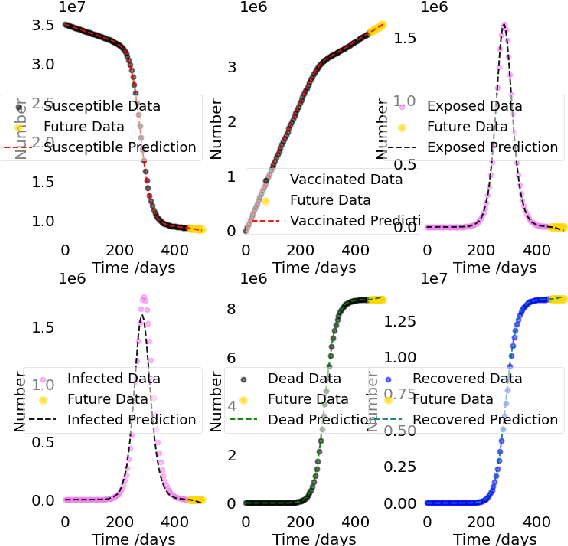
In this work, SVEIDR model and its variants (Aged, Vaccination-structured models) are introduced to encode the effect of social contact for different age groups and vaccination status. Then we implement the Physic-Informed Neural Network on both simulation and real-world data. Results including the spread and forecasting analysis of COVID-19 learned from the neural network are shown in the paper.
Multiview Detection with Cardboard Human Modeling
Jul 10, 2022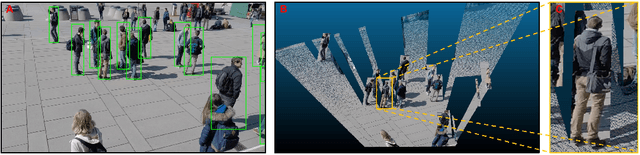
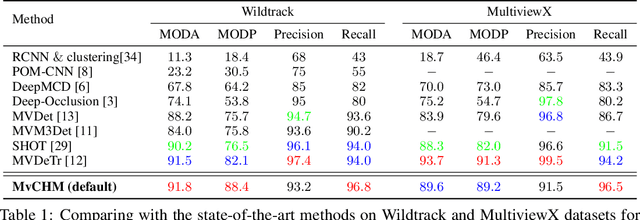
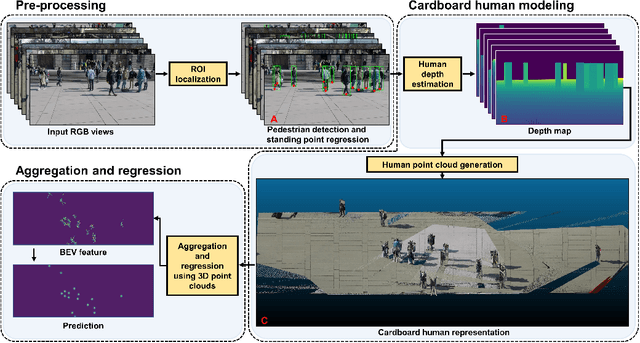

Multiview detection uses multiple calibrated cameras with overlapping fields of views to locate occluded pedestrians. In this field, existing methods typically adopt a "human modeling - aggregation" strategy. To find robust pedestrian representations, some intuitively use locations of detected 2D bounding boxes, while others use entire frame features projected to the ground plane. However, the former does not consider human appearance and leads to many ambiguities, and the latter suffers from projection errors due to the lack of accurate height of the human torso and head. In this paper, we propose a new pedestrian representation scheme based on human point clouds modeling. Specifically, using ray tracing for holistic human depth estimation, we model pedestrians as upright, thin cardboard point clouds on the ground. Then, we aggregate the point clouds of the pedestrian cardboard across multiple views for a final decision. Compared with existing representations, the proposed method explicitly leverages human appearance and reduces projection errors significantly by relatively accurate height estimation. On two standard evaluation benchmarks, the proposed method achieves very competitive results.
Voxelized 3D Feature Aggregation for Multiview Detection
Dec 07, 2021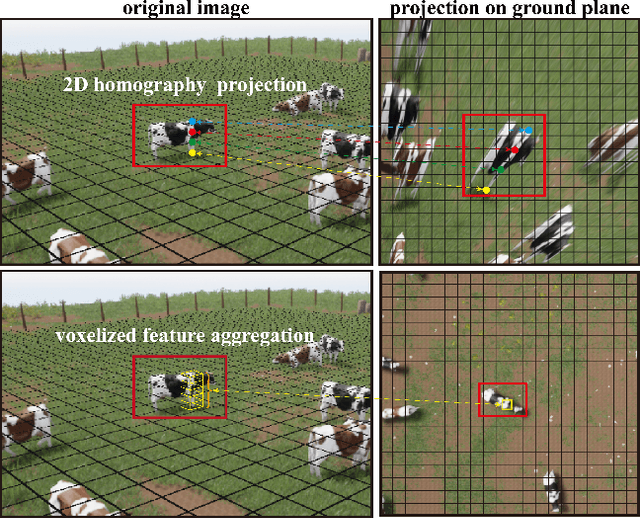
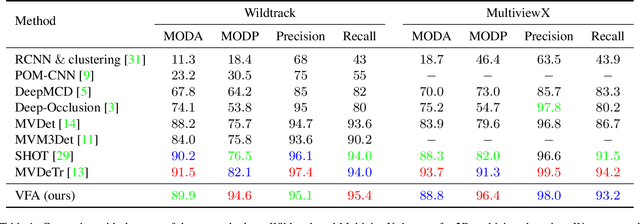
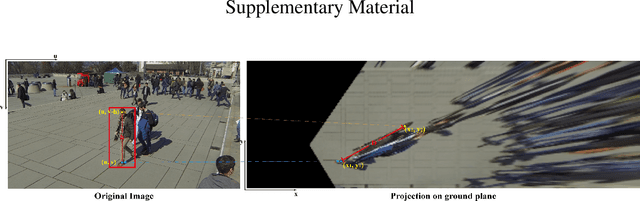

Multi-view detection incorporates multiple camera views to alleviate occlusion in crowded scenes, where the state-of-the-art approaches adopt homography transformations to project multi-view features to the ground plane. However, we find that these 2D transformations do not take into account the object's height, and with this neglection features along the vertical direction of same object are likely not projected onto the same ground plane point, leading to impure ground-plane features. To solve this problem, we propose VFA, voxelized 3D feature aggregation, for feature transformation and aggregation in multi-view detection. Specifically, we voxelize the 3D space, project the voxels onto each camera view, and associate 2D features with these projected voxels. This allows us to identify and then aggregate 2D features along the same vertical line, alleviating projection distortions to a large extent. Additionally, because different kinds of objects (human vs. cattle) have different shapes on the ground plane, we introduce the oriented Gaussian encoding to match such shapes, leading to increased accuracy and efficiency. We perform experiments on multiview 2D detection and multiview 3D detection problems. Results on four datasets (including a newly introduced MultiviewC dataset) show that our system is very competitive compared with the state-of-the-art approaches. %Our code and data will be open-sourced.Code and MultiviewC are released at https://github.com/Robert-Mar/VFA.