 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterp3D: Correspondence-aware Interpolation for Generative Textured 3D Morphing
Jan 20, 2026Textured 3D morphing seeks to generate smooth and plausible transitions between two 3D assets, preserving both structural coherence and fine-grained appearance. This ability is crucial not only for advancing 3D generation research but also for practical applications in animation, editing, and digital content creation. Existing approaches either operate directly on geometry, limiting them to shape-only morphing while neglecting textures, or extend 2D interpolation strategies into 3D, which often causes semantic ambiguity, structural misalignment, and texture blurring. These challenges underscore the necessity to jointly preserve geometric consistency, texture alignment, and robustness throughout the transition process. To address this, we propose Interp3D, a novel training-free framework for textured 3D morphing. It harnesses generative priors and adopts a progressive alignment principle to ensure both geometric fidelity and texture coherence. Starting from semantically aligned interpolation in condition space, Interp3D enforces structural consistency via SLAT (Structured Latent)-guided structure interpolation, and finally transfers appearance details through fine-grained texture fusion. For comprehensive evaluations, we construct a dedicated dataset, Interp3DData, with graded difficulty levels and assess generation results from fidelity, transition smoothness, and plausibility. Both quantitative metrics and human studies demonstrate the significant advantages of our proposed approach over previous methods. Source code is available at https://github.com/xiaolul2/Interp3D.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Learning Multi-Modal Mobility Dynamics for Generalized Next Location Recommendation
Dec 27, 2025The precise prediction of human mobility has produced significant socioeconomic impacts, such as location recommendations and evacuation suggestions. However, existing methods suffer from limited generalization capability: unimodal approaches are constrained by data sparsity and inherent biases, while multi-modal methods struggle to effectively capture mobility dynamics caused by the semantic gap between static multi-modal representation and spatial-temporal dynamics. Therefore, we leverage multi-modal spatial-temporal knowledge to characterize mobility dynamics for the location recommendation task, dubbed as \textbf{M}ulti-\textbf{M}odal \textbf{Mob}ility (\textbf{M}$^3$\textbf{ob}). First, we construct a unified spatial-temporal relational graph (STRG) for multi-modal representation, by leveraging the functional semantics and spatial-temporal knowledge captured by the large language models (LLMs)-enhanced spatial-temporal knowledge graph (STKG). Second, we design a gating mechanism to fuse spatial-temporal graph representations of different modalities, and propose an STKG-guided cross-modal alignment to inject spatial-temporal dynamic knowledge into the static image modality. Extensive experiments on six public datasets show that our proposed method not only achieves consistent improvements in normal scenarios but also exhibits significant generalization ability in abnormal scenarios.
Surgical Scene Segmentation using a Spike-Driven Video Transformer with Real-Time Potential
Dec 24, 2025Modern surgical systems increasingly rely on intelligent scene understanding to provide timely situational awareness for enhanced intra-operative safety. Within this pipeline, surgical scene segmentation plays a central role in accurately perceiving operative events. Although recent deep learning models, particularly large-scale foundation models, achieve remarkable segmentation accuracy, their substantial computational demands and power consumption hinder real-time deployment in resource-constrained surgical environments. To address this limitation, we explore the emerging SNN as a promising paradigm for highly efficient surgical intelligence. However, their performance is still constrained by the scarcity of labeled surgical data and the inherently sparse nature of surgical video representations. To this end, we propose \textit{SpikeSurgSeg}, the first spike-driven video Transformer framework tailored for surgical scene segmentation with real-time potential on non-GPU platforms. To address the limited availability of surgical annotations, we introduce a surgical-scene masked autoencoding pretraining strategy for SNNs that enables robust spatiotemporal representation learning via layer-wise tube masking. Building on this pretrained backbone, we further adopt a lightweight spike-driven segmentation head that produces temporally consistent predictions while preserving the low-latency characteristics of SNNs. Extensive experiments on EndoVis18 and our in-house SurgBleed dataset demonstrate that SpikeSurgSeg achieves mIoU comparable to SOTA ANN-based models while reducing inference latency by at least $8\times$. Notably, it delivers over $20\times$ acceleration relative to most foundation-model baselines, underscoring its potential for time-critical surgical scene segmentation.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
MVU-Eval: Towards Multi-Video Understanding Evaluation for Multimodal LLMs
Nov 13, 2025



The advent of Multimodal Large Language Models (MLLMs) has expanded AI capabilities to visual modalities, yet existing evaluation benchmarks remain limited to single-video understanding, overlooking the critical need for multi-video understanding in real-world scenarios (e.g., sports analytics and autonomous driving). To address this significant gap, we introduce MVU-Eval, the first comprehensive benchmark for evaluating Multi-Video Understanding for MLLMs. Specifically, our MVU-Eval mainly assesses eight core competencies through 1,824 meticulously curated question-answer pairs spanning 4,959 videos from diverse domains, addressing both fundamental perception tasks and high-order reasoning tasks. These capabilities are rigorously aligned with real-world applications such as multi-sensor synthesis in autonomous systems and cross-angle sports analytics. Through extensive evaluation of state-of-the-art open-source and closed-source models, we reveal significant performance discrepancies and limitations in current MLLMs' ability to perform understanding across multiple videos. The benchmark will be made publicly available to foster future research.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
What Limits Virtual Agent Application? OmniBench: A Scalable Multi-Dimensional Benchmark for Essential Virtual Agent Capabilities
Jun 10, 2025
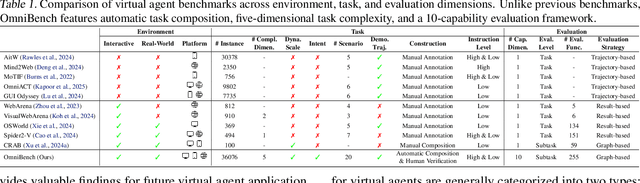
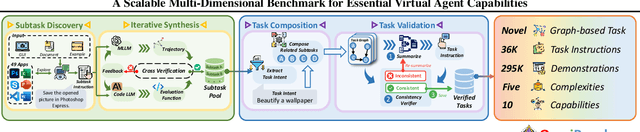

As multimodal large language models (MLLMs) advance, MLLM-based virtual agents have demonstrated remarkable performance. However, existing benchmarks face significant limitations, including uncontrollable task complexity, extensive manual annotation with limited scenarios, and a lack of multidimensional evaluation. In response to these challenges, we introduce OmniBench, a self-generating, cross-platform, graph-based benchmark with an automated pipeline for synthesizing tasks of controllable complexity through subtask composition. To evaluate the diverse capabilities of virtual agents on the graph, we further present OmniEval, a multidimensional evaluation framework that includes subtask-level evaluation, graph-based metrics, and comprehensive tests across 10 capabilities. Our synthesized dataset contains 36k graph-structured tasks across 20 scenarios, achieving a 91\% human acceptance rate. Training on our graph-structured data shows that it can more efficiently guide agents compared to manually annotated data. We conduct multidimensional evaluations for various open-source and closed-source models, revealing their performance across various capabilities and paving the way for future advancements. Our project is available at https://omni-bench.github.io/.
SpikeVideoFormer: An Efficient Spike-Driven Video Transformer with Hamming Attention and $\mathcal{O}(T)$ Complexity
May 15, 2025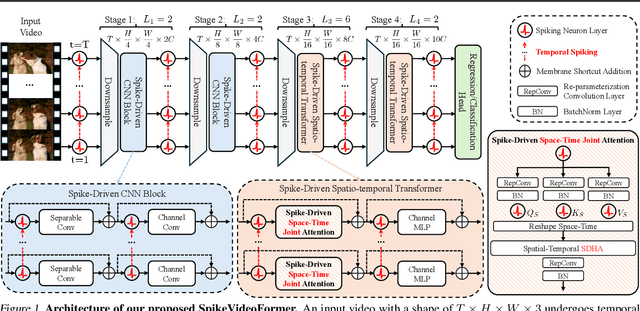
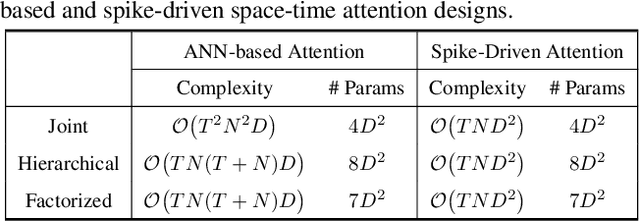

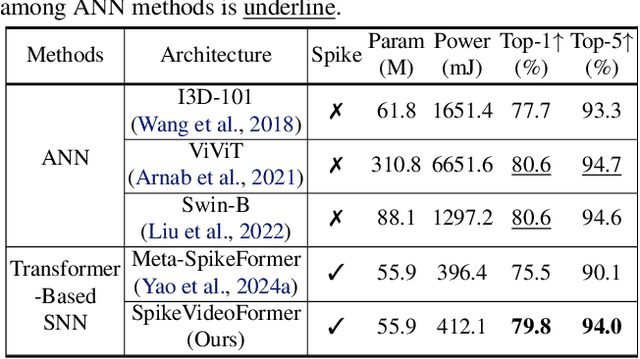
Spiking Neural Networks (SNNs) have shown competitive performance to Artificial Neural Networks (ANNs) in various vision tasks, while offering superior energy efficiency. However, existing SNN-based Transformers primarily focus on single-image tasks, emphasizing spatial features while not effectively leveraging SNNs' efficiency in video-based vision tasks. In this paper, we introduce SpikeVideoFormer, an efficient spike-driven video Transformer, featuring linear temporal complexity $\mathcal{O}(T)$. Specifically, we design a spike-driven Hamming attention (SDHA) which provides a theoretically guided adaptation from traditional real-valued attention to spike-driven attention. Building on SDHA, we further analyze various spike-driven space-time attention designs and identify an optimal scheme that delivers appealing performance for video tasks, while maintaining only linear temporal complexity. The generalization ability and efficiency of our model are demonstrated across diverse downstream video tasks, including classification, human pose tracking, and semantic segmentation. Empirical results show our method achieves state-of-the-art (SOTA) performance compared to existing SNN approaches, with over 15\% improvement on the latter two tasks. Additionally, it matches the performance of recent ANN-based methods while offering significant efficiency gains, achieving $\times 16$, $\times 10$ and $\times 5$ improvements on the three tasks. https://github.com/JimmyZou/SpikeVideoFormer
Learning Fine-grained Domain Generalization via Hyperbolic State Space Hallucination
Apr 10, 2025Fine-grained domain generalization (FGDG) aims to learn a fine-grained representation that can be well generalized to unseen target domains when only trained on the source domain data. Compared with generic domain generalization, FGDG is particularly challenging in that the fine-grained category can be only discerned by some subtle and tiny patterns. Such patterns are particularly fragile under the cross-domain style shifts caused by illumination, color and etc. To push this frontier, this paper presents a novel Hyperbolic State Space Hallucination (HSSH) method. It consists of two key components, namely, state space hallucination (SSH) and hyperbolic manifold consistency (HMC). SSH enriches the style diversity for the state embeddings by firstly extrapolating and then hallucinating the source images. Then, the pre- and post- style hallucinate state embeddings are projected into the hyperbolic manifold. The hyperbolic state space models the high-order statistics, and allows a better discernment of the fine-grained patterns. Finally, the hyperbolic distance is minimized, so that the impact of style variation on fine-grained patterns can be eliminated. Experiments on three FGDG benchmarks demonstrate its state-of-the-art performance.