 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Evolving Symbolic World for Planning in Open-Ended Environments
Jun 21, 2026Recent works have explored integrating Vision-Language Models (VLMs) with classical planners that rely on symbolic representations of planning problems to generate long-horizon plans for complex embodied tasks. However, in open-ended environments, these symbolic representations obtained from perception are often incomplete, leading to suboptimal performance. To address this, we introduce SCOPE, a self-adaptive symbolic planning framework that supports refining action plans and evolving the symbolic world, i.e., the symbolic representations of open-ended environments. SCOPE comprises two synergistic modules: a Symbolic Execution Simulator (SESim) that conducts symbolic validation and real execution of action plans, leveraging the feedback to refine the plans and evolve the symbolic world; and a Self-Adaptive Symbolic Memory (SASMem) that further distills feedback into evolving symbolic knowledge to enhance long-horizon planning and modeling of the symbolic world. Experiments in open-ended environments show that SCOPE significantly improves the completeness of the symbolic world, the success rate of plans under environment perturbations, and cross-task grounding and adaptability across diverse embodied scenarios.
Learning to Adapt: Self-Improving Web Agent via Cognitive-Aware Exploration
May 29, 2026Recent advances in Multimodal Large Language Models (MLLMs) have led to promising progress in web agents. However, existing web agents often rely on handcrafted execution pipelines or expensive expert trajectories, limiting their adaptability to complex, dynamic environments. To address these challenges, we propose SCALE (Self-Cognitive-Aware Learning and Exploration), which leverages three adversarial roles, Selector, Predictor, and Judger to autonomously discover the agent's limitations and expand its cognitive boundaries through environmental exploration. Moreover, we propose SCALE-Hop, a graph exploration strategy that facilitates global planning and helps agents avoid local exploration traps. To further support learning, we construct SCALE-20k, a large-scale dataset collected from 19 real-world websites, containing diverse task types and structured demonstrations generated from SCALE's exploration traces. Experimental results show that our approach significantly improves the performance and generalization of multiple MLLMs in various web environments. Our framework offers a scalable and generalizable solution for building truly autonomous and adaptive web agents.
CORE: Code-based Inverse Self-Training Framework with Graph Expansion for Virtual Agents
Jan 05, 2026The development of Multimodal Virtual Agents has made significant progress through the integration of Multimodal Large Language Models. However, mainstream training paradigms face key challenges: Behavior Cloning is simple and effective through imitation but suffers from low behavioral diversity, while Reinforcement Learning is capable of discovering novel strategies through exploration but heavily relies on manually designed reward functions. To address the conflict between these two methods, we present CORE, a Code-based Inverse Self-Training Framework with Graph Expansion that bridges imitation and exploration, offering a novel training framework that promotes behavioral diversity while eliminating the reliance on manually reward design. Specifically, we introduce Semantic Code Abstraction to automatically infers reward functions from expert demonstrations without manual design. The inferred reward function, referred to as the Label Function, is executable code that verifies one key step within a task. Building on this, we propose Strategy Graph Expansion to enhance in-domain behavioral diversity, which constructs a multi-path graph called Strategy Graph that captures diverse valid solutions beyond expert demonstrations. Furthermore, we introduce Trajectory-Guided Extrapolation, which enriches out-of-domain behavioral diversity by utilizing both successful and failed trajectories to expand the task space. Experiments on Web and Android platforms demonstrate that CORE significantly improves both overall performance and generalization, highlighting its potential as a robust and generalizable training paradigm for building powerful virtual agents.
OmniMoGen: Unifying Human Motion Generation via Learning from Interleaved Text-Motion Instructions
Dec 22, 2025Large language models (LLMs) have unified diverse linguistic tasks within a single framework, yet such unification remains unexplored in human motion generation. Existing methods are confined to isolated tasks, limiting flexibility for free-form and omni-objective generation. To address this, we propose OmniMoGen, a unified framework that enables versatile motion generation through interleaved text-motion instructions. Built upon a concise RVQ-VAE and transformer architecture, OmniMoGen supports end-to-end instruction-driven motion generation. We construct X2Mo, a large-scale dataset of over 137K interleaved text-motion instructions, and introduce AnyContext, a benchmark for evaluating interleaved motion generation. Experiments show that OmniMoGen achieves state-of-the-art performance on text-to-motion, motion editing, and AnyContext, exhibiting emerging capabilities such as compositional editing, self-reflective generation, and knowledge-informed generation. These results mark a step toward the next intelligent motion generation. Project Page: https://OmniMoGen.github.io/.
What Limits Virtual Agent Application? OmniBench: A Scalable Multi-Dimensional Benchmark for Essential Virtual Agent Capabilities
Jun 10, 2025
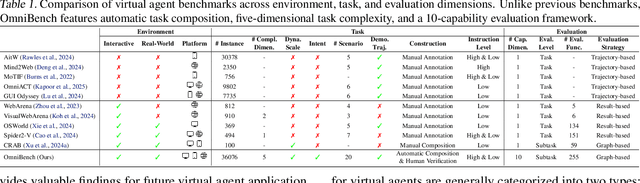
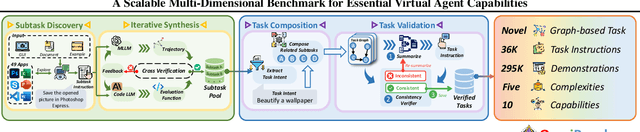

As multimodal large language models (MLLMs) advance, MLLM-based virtual agents have demonstrated remarkable performance. However, existing benchmarks face significant limitations, including uncontrollable task complexity, extensive manual annotation with limited scenarios, and a lack of multidimensional evaluation. In response to these challenges, we introduce OmniBench, a self-generating, cross-platform, graph-based benchmark with an automated pipeline for synthesizing tasks of controllable complexity through subtask composition. To evaluate the diverse capabilities of virtual agents on the graph, we further present OmniEval, a multidimensional evaluation framework that includes subtask-level evaluation, graph-based metrics, and comprehensive tests across 10 capabilities. Our synthesized dataset contains 36k graph-structured tasks across 20 scenarios, achieving a 91\% human acceptance rate. Training on our graph-structured data shows that it can more efficiently guide agents compared to manually annotated data. We conduct multidimensional evaluations for various open-source and closed-source models, revealing their performance across various capabilities and paving the way for future advancements. Our project is available at https://omni-bench.github.io/.
FocusDiff: Advancing Fine-Grained Text-Image Alignment for Autoregressive Visual Generation through RL
Jun 05, 2025Recent studies extend the autoregression paradigm to text-to-image generation, achieving performance comparable to diffusion models. However, our new PairComp benchmark -- featuring test cases of paired prompts with similar syntax but different fine-grained semantics -- reveals that existing models struggle with fine-grained text-image alignment thus failing to realize precise control over visual tokens. To address this, we propose FocusDiff, which enhances fine-grained text-image semantic alignment by focusing on subtle differences between similar text-image pairs. We construct a new dataset of paired texts and images with similar overall expressions but distinct local semantics, further introducing a novel reinforcement learning algorithm to emphasize such fine-grained semantic differences for desired image generation. Our approach achieves state-of-the-art performance on existing text-to-image benchmarks and significantly outperforms prior methods on PairComp.
Boosting Virtual Agent Learning and Reasoning: A Step-wise, Multi-dimensional, and Generalist Reward Model with Benchmark
Mar 24, 2025The development of Generalist Virtual Agents (GVAs) powered by Multimodal Large Language Models (MLLMs) has shown significant promise in autonomous task execution. However, current training paradigms face critical limitations, including reliance on outcome supervision and labor-intensive human annotations. To address these challenges, we propose Similar, a Step-wise Multi-dimensional Generalist Reward Model, which offers fine-grained signals for agent training and can choose better action for inference-time scaling. Specifically, we begin by systematically defining five dimensions for evaluating agent actions. Building on this framework, we design an MCTS-P algorithm to automatically collect and annotate step-wise, five-dimensional agent execution data. Using this data, we train Similar with the Triple-M strategy. Furthermore, we introduce the first benchmark in the virtual agent domain for step-wise, multi-dimensional reward model training and evaluation, named SRM. This benchmark consists of two components: SRMTrain, which serves as the training set for Similar, and SRMEval, a manually selected test set for evaluating the reward model. Experimental results demonstrate that Similar, through its step-wise, multi-dimensional assessment and synergistic gain, provides GVAs with effective intermediate signals during both training and inference-time scaling. The code is available at https://github.com/Galery23/Similar-v1.