 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStream3D-VLM: Online 3D Spatial Understanding with Incremental Geometry Priors
Jun 05, 2026Despite advances in 3D scene understanding, existing 3D Large Multimodal Models operate in offline settings, requiring complete scene observations or predefined video clips. In this paper, we present an online 3D vision-language model that enables real-time spatial understanding from streaming video. Our approach adopts an autoregressive streaming control modeling based on the LLM's next-token prediction objective to learn when to respond, and employs a lightweight Visual-Spatial Feature Integration (VSFI) module to incrementally inject temporally aligned geometry priors into the visual stream. To alleviate long-context decoding overhead, we propose a plug-and-play Geometry-Adaptive Voxel Compression (GAVC) module for efficient visual token compression. To address the scarcity of streaming 3D-language data, we further develop a scalable data generation pipeline that curates over 1M online spatio-temporal 3D QA pairs and establishes a comprehensive benchmark spanning 29 tasks. Extensive experiments show that our approach significantly outperforms both proprietary and open-source models across online and offline 3D spatial understanding, reasoning, and grounding tasks. The project page is available at https://stream3d-vlm.github.io/
DynFlowDrive: Flow-Based Dynamic World Modeling for Autonomous Driving
Mar 20, 2026Recently, world models have been incorporated into the autonomous driving systems to improve the planning reliability. Existing approaches typically predict future states through appearance generation or deterministic regression, which limits their ability to capture trajectory-conditioned scene evolution and leads to unreliable action planning. To address this, we propose DynFlowDrive, a latent world model that leverages flow-based dynamics to model the transition of world states under different driving actions. By adopting the rectifiedflow formulation, the model learns a velocity field that describes how the scene state changes under different driving actions, enabling progressive prediction of future latent states. Building upon this, we further introduce a stability-aware multi-mode trajectory selection strategy that evaluates candidate trajectories according to the stability of the induced scene transitions. Extensive experiments on the nuScenes and NavSim benchmarks demonstrate consistent improvements across diverse driving frameworks without introducing additional inference overhead. Source code will be abaliable at https://github.com/xiaolul2/DynFlowDrive.
AgentVLN: Towards Agentic Vision-and-Language Navigation
Mar 18, 2026Vision-and-Language Navigation (VLN) requires an embodied agent to ground complex natural-language instructions into long-horizon navigation in unseen environments. While Vision-Language Models (VLMs) offer strong 2D semantic understanding, current VLN systems remain constrained by limited spatial perception, 2D-3D representation mismatch, and monocular scale ambiguity. In this paper, we propose AgentVLN, a novel and efficient embodied navigation framework that can be deployed on edge computing platforms. We formulate VLN as a Partially Observable Semi-Markov Decision Process (POSMDP) and introduce a VLM-as-Brain paradigm that decouples high-level semantic reasoning from perception and planning via a plug-and-play skill library. To resolve multi-level representation inconsistency, we design a cross-space representation mapping that projects perception-layer 3D topological waypoints into the image plane, yielding pixel-aligned visual prompts for the VLM. Building on this bridge, we integrate a context-aware self-correction and active exploration strategy to recover from occlusions and suppress error accumulation over long trajectories. To further address the spatial ambiguity of instructions in unstructured environments, we propose a Query-Driven Perceptual Chain-of-Thought (QD-PCoT) scheme, enabling the agent with the metacognitive ability to actively seek geometric depth information. Finally, we construct AgentVLN-Instruct, a large-scale instruction-tuning dataset with dynamic stage routing conditioned on target visibility. Extensive experiments show that AgentVLN consistently outperforms prior state-of-the-art methods (SOTA) on long-horizon VLN benchmarks, offering a practical paradigm for lightweight deployment of next-generation embodied navigation models. Code: https://github.com/Allenxinn/AgentVLN.
WorldStereo: Bridging Camera-Guided Video Generation and Scene Reconstruction via 3D Geometric Memories
Mar 02, 2026Recent advances in foundational Video Diffusion Models (VDMs) have yielded significant progress. Yet, despite the remarkable visual quality of generated videos, reconstructing consistent 3D scenes from these outputs remains challenging, due to limited camera controllability and inconsistent generated content when viewed from distinct camera trajectories. In this paper, we propose WorldStereo, a novel framework that bridges camera-guided video generation and 3D reconstruction via two dedicated geometric memory modules. Formally, the global-geometric memory enables precise camera control while injecting coarse structural priors through incrementally updated point clouds. Moreover, the spatial-stereo memory constrains the model's attention receptive fields with 3D correspondence to focus on fine-grained details from the memory bank. These components enable WorldStereo to generate multi-view-consistent videos under precise camera control, facilitating high-quality 3D reconstruction. Furthermore, the flexible control branch-based WorldStereo shows impressive efficiency, benefiting from the distribution matching distilled VDM backbone without joint training. Extensive experiments across both camera-guided video generation and 3D reconstruction benchmarks demonstrate the effectiveness of our approach. Notably, we show that WorldStereo acts as a powerful world model, tackling diverse scene generation tasks (whether starting from perspective or panoramic images) with high-fidelity 3D results. Models will be released.
VisionTrim: Unified Vision Token Compression for Training-Free MLLM Acceleration
Jan 30, 2026Multimodal large language models (MLLMs) suffer from high computational costs due to excessive visual tokens, particularly in high-resolution and video-based scenarios. Existing token reduction methods typically focus on isolated pipeline components and often neglect textual alignment, leading to performance degradation. In this paper, we propose VisionTrim, a unified framework for training-free MLLM acceleration, integrating two effective plug-and-play modules: 1) the Dominant Vision Token Selection (DVTS) module, which preserves essential visual tokens via a global-local view, and 2) the Text-Guided Vision Complement (TGVC) module, which facilitates context-aware token merging guided by textual cues. Extensive experiments across diverse image and video multimodal benchmarks demonstrate the performance superiority of our VisionTrim, advancing practical MLLM deployment in real-world applications. The code is available at: https://github.com/hanxunyu/VisionTrim.
Interp3D: Correspondence-aware Interpolation for Generative Textured 3D Morphing
Jan 20, 2026Textured 3D morphing seeks to generate smooth and plausible transitions between two 3D assets, preserving both structural coherence and fine-grained appearance. This ability is crucial not only for advancing 3D generation research but also for practical applications in animation, editing, and digital content creation. Existing approaches either operate directly on geometry, limiting them to shape-only morphing while neglecting textures, or extend 2D interpolation strategies into 3D, which often causes semantic ambiguity, structural misalignment, and texture blurring. These challenges underscore the necessity to jointly preserve geometric consistency, texture alignment, and robustness throughout the transition process. To address this, we propose Interp3D, a novel training-free framework for textured 3D morphing. It harnesses generative priors and adopts a progressive alignment principle to ensure both geometric fidelity and texture coherence. Starting from semantically aligned interpolation in condition space, Interp3D enforces structural consistency via SLAT (Structured Latent)-guided structure interpolation, and finally transfers appearance details through fine-grained texture fusion. For comprehensive evaluations, we construct a dedicated dataset, Interp3DData, with graded difficulty levels and assess generation results from fidelity, transition smoothness, and plausibility. Both quantitative metrics and human studies demonstrate the significant advantages of our proposed approach over previous methods. Source code is available at https://github.com/xiaolul2/Interp3D.
Forging Spatial Intelligence: A Roadmap of Multi-Modal Data Pre-Training for Autonomous Systems
Dec 30, 2025The rapid advancement of autonomous systems, including self-driving vehicles and drones, has intensified the need to forge true Spatial Intelligence from multi-modal onboard sensor data. While foundation models excel in single-modal contexts, integrating their capabilities across diverse sensors like cameras and LiDAR to create a unified understanding remains a formidable challenge. This paper presents a comprehensive framework for multi-modal pre-training, identifying the core set of techniques driving progress toward this goal. We dissect the interplay between foundational sensor characteristics and learning strategies, evaluating the role of platform-specific datasets in enabling these advancements. Our central contribution is the formulation of a unified taxonomy for pre-training paradigms: ranging from single-modality baselines to sophisticated unified frameworks that learn holistic representations for advanced tasks like 3D object detection and semantic occupancy prediction. Furthermore, we investigate the integration of textual inputs and occupancy representations to facilitate open-world perception and planning. Finally, we identify critical bottlenecks, such as computational efficiency and model scalability, and propose a roadmap toward general-purpose multi-modal foundation models capable of achieving robust Spatial Intelligence for real-world deployment.
Vision-Language-Action Models for Autonomous Driving: Past, Present, and Future
Dec 18, 2025Autonomous driving has long relied on modular "Perception-Decision-Action" pipelines, where hand-crafted interfaces and rule-based components often break down in complex or long-tailed scenarios. Their cascaded design further propagates perception errors, degrading downstream planning and control. Vision-Action (VA) models address some limitations by learning direct mappings from visual inputs to actions, but they remain opaque, sensitive to distribution shifts, and lack structured reasoning or instruction-following capabilities. Recent progress in Large Language Models (LLMs) and multimodal learning has motivated the emergence of Vision-Language-Action (VLA) frameworks, which integrate perception with language-grounded decision making. By unifying visual understanding, linguistic reasoning, and actionable outputs, VLAs offer a pathway toward more interpretable, generalizable, and human-aligned driving policies. This work provides a structured characterization of the emerging VLA landscape for autonomous driving. We trace the evolution from early VA approaches to modern VLA frameworks and organize existing methods into two principal paradigms: End-to-End VLA, which integrates perception, reasoning, and planning within a single model, and Dual-System VLA, which separates slow deliberation (via VLMs) from fast, safety-critical execution (via planners). Within these paradigms, we further distinguish subclasses such as textual vs. numerical action generators and explicit vs. implicit guidance mechanisms. We also summarize representative datasets and benchmarks for evaluating VLA-based driving systems and highlight key challenges and open directions, including robustness, interpretability, and instruction fidelity. Overall, this work aims to establish a coherent foundation for advancing human-compatible autonomous driving systems.
RewardMap: Tackling Sparse Rewards in Fine-grained Visual Reasoning via Multi-Stage Reinforcement Learning
Oct 02, 2025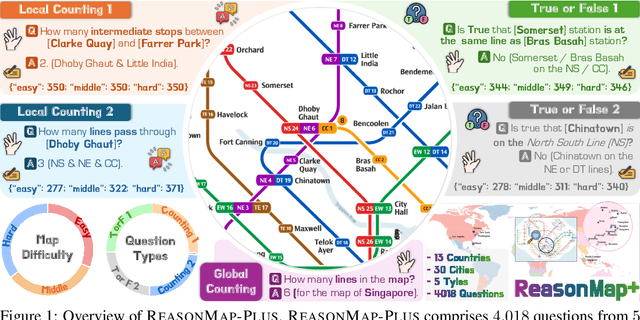
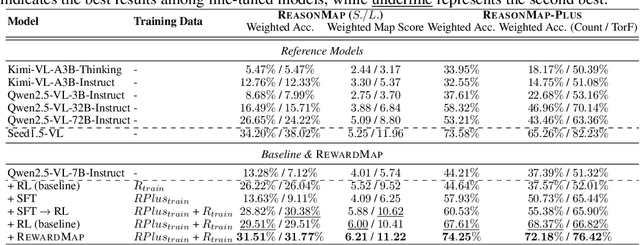
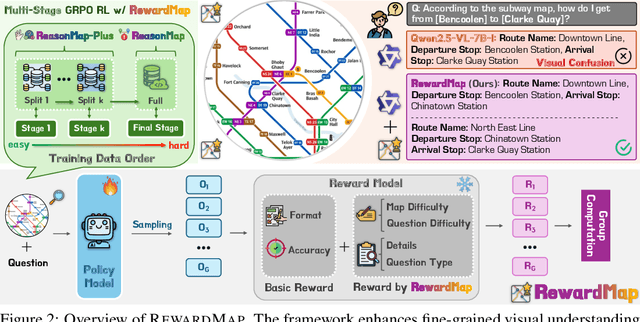
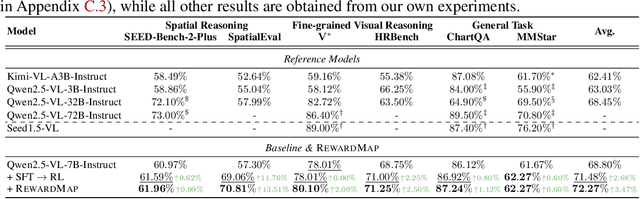
Fine-grained visual reasoning remains a core challenge for multimodal large language models (MLLMs). The recently introduced ReasonMap highlights this gap by showing that even advanced MLLMs struggle with spatial reasoning in structured and information-rich settings such as transit maps, a task of clear practical and scientific importance. However, standard reinforcement learning (RL) on such tasks is impeded by sparse rewards and unstable optimization. To address this, we first construct ReasonMap-Plus, an extended dataset that introduces dense reward signals through Visual Question Answering (VQA) tasks, enabling effective cold-start training of fine-grained visual understanding skills. Next, we propose RewardMap, a multi-stage RL framework designed to improve both visual understanding and reasoning capabilities of MLLMs. RewardMap incorporates two key designs. First, we introduce a difficulty-aware reward design that incorporates detail rewards, directly tackling the sparse rewards while providing richer supervision. Second, we propose a multi-stage RL scheme that bootstraps training from simple perception to complex reasoning tasks, offering a more effective cold-start strategy than conventional Supervised Fine-Tuning (SFT). Experiments on ReasonMap and ReasonMap-Plus demonstrate that each component of RewardMap contributes to consistent performance gains, while their combination yields the best results. Moreover, models trained with RewardMap achieve an average improvement of 3.47% across 6 benchmarks spanning spatial reasoning, fine-grained visual reasoning, and general tasks beyond transit maps, underscoring enhanced visual understanding and reasoning capabilities.
MambaMap: Online Vectorized HD Map Construction using State Space Model
Jul 27, 2025High-definition (HD) maps are essential for autonomous driving, as they provide precise road information for downstream tasks. Recent advances highlight the potential of temporal modeling in addressing challenges like occlusions and extended perception range. However, existing methods either fail to fully exploit temporal information or incur substantial computational overhead in handling extended sequences. To tackle these challenges, we propose MambaMap, a novel framework that efficiently fuses long-range temporal features in the state space to construct online vectorized HD maps. Specifically, MambaMap incorporates a memory bank to store and utilize information from historical frames, dynamically updating BEV features and instance queries to improve robustness against noise and occlusions. Moreover, we introduce a gating mechanism in the state space, selectively integrating dependencies of map elements in high computational efficiency. In addition, we design innovative multi-directional and spatial-temporal scanning strategies to enhance feature extraction at both BEV and instance levels. These strategies significantly boost the prediction accuracy of our approach while ensuring robust temporal consistency. Extensive experiments on the nuScenes and Argoverse2 datasets demonstrate that our proposed MambaMap approach outperforms state-of-the-art methods across various splits and perception ranges. Source code will be available at https://github.com/ZiziAmy/MambaMap.