 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Adapt: Self-Improving Web Agent via Cognitive-Aware Exploration
May 29, 2026Recent advances in Multimodal Large Language Models (MLLMs) have led to promising progress in web agents. However, existing web agents often rely on handcrafted execution pipelines or expensive expert trajectories, limiting their adaptability to complex, dynamic environments. To address these challenges, we propose SCALE (Self-Cognitive-Aware Learning and Exploration), which leverages three adversarial roles, Selector, Predictor, and Judger to autonomously discover the agent's limitations and expand its cognitive boundaries through environmental exploration. Moreover, we propose SCALE-Hop, a graph exploration strategy that facilitates global planning and helps agents avoid local exploration traps. To further support learning, we construct SCALE-20k, a large-scale dataset collected from 19 real-world websites, containing diverse task types and structured demonstrations generated from SCALE's exploration traces. Experimental results show that our approach significantly improves the performance and generalization of multiple MLLMs in various web environments. Our framework offers a scalable and generalizable solution for building truly autonomous and adaptive web agents.
CORE: Code-based Inverse Self-Training Framework with Graph Expansion for Virtual Agents
Jan 05, 2026The development of Multimodal Virtual Agents has made significant progress through the integration of Multimodal Large Language Models. However, mainstream training paradigms face key challenges: Behavior Cloning is simple and effective through imitation but suffers from low behavioral diversity, while Reinforcement Learning is capable of discovering novel strategies through exploration but heavily relies on manually designed reward functions. To address the conflict between these two methods, we present CORE, a Code-based Inverse Self-Training Framework with Graph Expansion that bridges imitation and exploration, offering a novel training framework that promotes behavioral diversity while eliminating the reliance on manually reward design. Specifically, we introduce Semantic Code Abstraction to automatically infers reward functions from expert demonstrations without manual design. The inferred reward function, referred to as the Label Function, is executable code that verifies one key step within a task. Building on this, we propose Strategy Graph Expansion to enhance in-domain behavioral diversity, which constructs a multi-path graph called Strategy Graph that captures diverse valid solutions beyond expert demonstrations. Furthermore, we introduce Trajectory-Guided Extrapolation, which enriches out-of-domain behavioral diversity by utilizing both successful and failed trajectories to expand the task space. Experiments on Web and Android platforms demonstrate that CORE significantly improves both overall performance and generalization, highlighting its potential as a robust and generalizable training paradigm for building powerful virtual agents.
RoboTidy : A 3D Gaussian Splatting Household Tidying Benchmark for Embodied Navigation and Action
Nov 19, 2025Household tidying is an important application area, yet current benchmarks neither model user preferences nor support mobility, and they generalize poorly, making it hard to comprehensively assess integrated language-to-action capabilities. To address this, we propose RoboTidy, a unified benchmark for language-guided household tidying that supports Vision-Language-Action (VLA) and Vision-Language-Navigation (VLN) training and evaluation. RoboTidy provides 500 photorealistic 3D Gaussian Splatting (3DGS) household scenes (covering 500 objects and containers) with collisions, formulates tidying as an "Action (Object, Container)" list, and supplies 6.4k high-quality manipulation demonstration trajectories and 1.5k naviagtion trajectories to support both few-shot and large-scale training. We also deploy RoboTidy in the real world for object tidying, establishing an end-to-end benchmark for household tidying. RoboTidy offers a scalable platform and bridges a key gap in embodied AI by enabling holistic and realistic evaluation of language-guided robots.
What Limits Virtual Agent Application? OmniBench: A Scalable Multi-Dimensional Benchmark for Essential Virtual Agent Capabilities
Jun 10, 2025
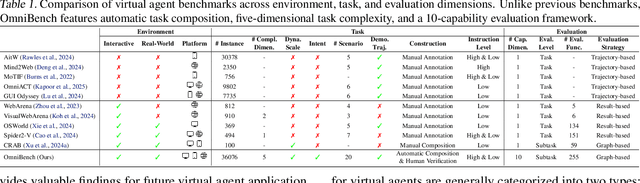
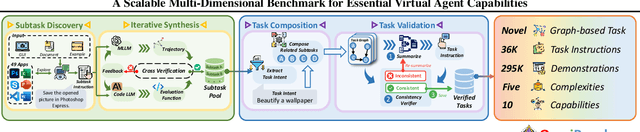

As multimodal large language models (MLLMs) advance, MLLM-based virtual agents have demonstrated remarkable performance. However, existing benchmarks face significant limitations, including uncontrollable task complexity, extensive manual annotation with limited scenarios, and a lack of multidimensional evaluation. In response to these challenges, we introduce OmniBench, a self-generating, cross-platform, graph-based benchmark with an automated pipeline for synthesizing tasks of controllable complexity through subtask composition. To evaluate the diverse capabilities of virtual agents on the graph, we further present OmniEval, a multidimensional evaluation framework that includes subtask-level evaluation, graph-based metrics, and comprehensive tests across 10 capabilities. Our synthesized dataset contains 36k graph-structured tasks across 20 scenarios, achieving a 91\% human acceptance rate. Training on our graph-structured data shows that it can more efficiently guide agents compared to manually annotated data. We conduct multidimensional evaluations for various open-source and closed-source models, revealing their performance across various capabilities and paving the way for future advancements. Our project is available at https://omni-bench.github.io/.
Boosting Virtual Agent Learning and Reasoning: A Step-wise, Multi-dimensional, and Generalist Reward Model with Benchmark
Mar 24, 2025The development of Generalist Virtual Agents (GVAs) powered by Multimodal Large Language Models (MLLMs) has shown significant promise in autonomous task execution. However, current training paradigms face critical limitations, including reliance on outcome supervision and labor-intensive human annotations. To address these challenges, we propose Similar, a Step-wise Multi-dimensional Generalist Reward Model, which offers fine-grained signals for agent training and can choose better action for inference-time scaling. Specifically, we begin by systematically defining five dimensions for evaluating agent actions. Building on this framework, we design an MCTS-P algorithm to automatically collect and annotate step-wise, five-dimensional agent execution data. Using this data, we train Similar with the Triple-M strategy. Furthermore, we introduce the first benchmark in the virtual agent domain for step-wise, multi-dimensional reward model training and evaluation, named SRM. This benchmark consists of two components: SRMTrain, which serves as the training set for Similar, and SRMEval, a manually selected test set for evaluating the reward model. Experimental results demonstrate that Similar, through its step-wise, multi-dimensional assessment and synergistic gain, provides GVAs with effective intermediate signals during both training and inference-time scaling. The code is available at https://github.com/Galery23/Similar-v1.
RADAR: Robust Two-stage Modality-incomplete Industrial Anomaly Detection
Oct 02, 2024Multimodal Industrial Anomaly Detection (MIAD), utilizing 3D point clouds and 2D RGB images to identify the abnormal region of products, plays a crucial role in industrial quality inspection. However, the conventional MIAD setting presupposes that all 2D and 3D modalities are paired, overlooking the fact that multimodal data collected from the real world is often imperfect due to missing modalities. Consequently, MIAD models that demonstrate robustness against modal-incomplete data are highly desirable in practice. To address this practical challenge, we introduce a first-of-its-kind study that comprehensively investigates Modality-Incomplete Industrial Anomaly Detection (MIIAD), to consider the imperfect learning environment in which the multimodal information may be incomplete. Not surprisingly, we discovered that most existing MIAD approaches are inadequate for addressing MIIAD challenges, leading to significant performance degradation on the MIIAD benchmark we developed. In this paper, we propose a novel two-stage Robust modAlity-imcomplete fusing and Detecting frAmewoRk, abbreviated as RADAR. Our bootstrapping philosophy is to enhance two stages in MIIAD, improving the robustness of the Multimodal Transformer: i) In feature fusion, we first explore learning modality-incomplete instruction, guiding the pre-trained Multimodal Transformer to robustly adapt to various modality-incomplete scenarios, and implement adaptive parameter learning based on a HyperNetwork; ii) In anomaly detection, we construct a real-pseudo hybrid module to highlight the distinctiveness of modality combinations, further enhancing the robustness of the MIIAD model. Our experimental results demonstrate that the proposed RADAR significantly surpasses conventional MIAD methods in terms of effectiveness and robustness on our newly created MIIAD dataset, underscoring its practical application value.