 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne for All: A Non-Linear Transformer can Enable Cross-Domain Generalization for In-Context Reinforcement Learning
May 10, 2026A central challenge in reinforcement learning (RL) is to learn models that generalize beyond the tasks on which they are trained, a goal traditionally pursued through multi-task and meta RL. Recently, transformer architectures have emerged as a promising approach, enabling adaptation to new tasks via in-context learning without explicit parameter updates. From a functional perspective, a transformer can be viewed as a functional operator that maps a context to a task-specific function. It is thus fundamental to understand and design this operator to support stronger generalization in RL. In this work, we address this resulting question of generalization from a kernel-based perspective by establishing a connection between non-linear transformers and kernel-based temporal difference learning. By interpreting the transformer as performing regression in a Reproducing Kernel Hilbert Space (RKHS), we show that value functions from different domains can be represented using a shared set of weights, provided they lie within the same RKHS. Experiments on multiple MetaWorld domains support this interpretation, demonstrating convergence of the temporal-difference objective.
Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
SAIL-Embedding Technical Report: Omni-modal Embedding Foundation Model
Oct 14, 2025



Multimodal embedding models aim to yield informative unified representations that empower diverse cross-modal tasks. Despite promising developments in the evolution from CLIP-based dual-tower architectures to large vision-language models, prior works still face unavoidable challenges in real-world applications and business scenarios, such as the limited modality support, unstable training mechanisms, and industrial domain gaps. In this work, we introduce SAIL-Embedding, an omni-modal embedding foundation model that addresses these issues through tailored training strategies and architectural design. In the optimization procedure, we propose a multi-stage training scheme to boost the multifaceted effectiveness of representation learning. Specifically, the content-aware progressive training aims to enhance the model's adaptability to diverse downstream tasks and master enriched cross-modal proficiency. The collaboration-aware recommendation enhancement training further adapts multimodal representations for recommendation scenarios by distilling knowledge from sequence-to-item and ID-to-item embeddings while mining user historical interests. Concurrently, we develop the stochastic specialization and dataset-driven pattern matching to strengthen model training flexibility and generalizability. Experimental results show that SAIL-Embedding achieves SOTA performance compared to other methods in different retrieval tasks. In online experiments across various real-world scenarios integrated with our model, we observe a significant increase in Lifetime (LT), which is a crucial indicator for the recommendation experience. For instance, the model delivers the 7-day LT gain of +0.158% and the 14-day LT gain of +0.144% in the Douyin-Selected scenario. For the Douyin feed rank model, the match features produced by SAIL-Embedding yield a +0.08% AUC gain.
Fast Convergence Rates for Subsampled Natural Gradient Algorithms on Quadratic Model Problems
Aug 28, 2025



Subsampled natural gradient descent (SNGD) has shown impressive results for parametric optimization tasks in scientific machine learning, such as neural network wavefunctions and physics-informed neural networks, but it has lacked a theoretical explanation. We address this gap by analyzing the convergence of SNGD and its accelerated variant, SPRING, for idealized parametric optimization problems where the model is linear and the loss function is strongly convex and quadratic. In the special case of a least-squares loss, namely the standard linear least-squares problem, we prove that SNGD is equivalent to a regularized Kaczmarz method while SPRING is equivalent to an accelerated regularized Kaczmarz method. As a result, by leveraging existing analyses we obtain under mild conditions (i) the first fast convergence rate for SNGD, (ii) the first convergence guarantee for SPRING in any setting, and (iii) the first proof that SPRING can accelerate SNGD. In the case of a general strongly convex quadratic loss, we extend the analysis of the regularized Kaczmarz method to obtain a fast convergence rate for SNGD under stronger conditions, providing the first explanation for the effectiveness of SNGD outside of the least-squares setting. Overall, our results illustrate how tools from randomized linear algebra can shed new light on the interplay between subsampling and curvature-aware optimization strategies.
Operator-Level Quantum Acceleration of Non-Logconcave Sampling
May 08, 2025Sampling from probability distributions of the form $\sigma \propto e^{-\beta V}$, where $V$ is a continuous potential, is a fundamental task across physics, chemistry, biology, computer science, and statistics. However, when $V$ is non-convex, the resulting distribution becomes non-logconcave, and classical methods such as Langevin dynamics often exhibit poor performance. We introduce the first quantum algorithm that provably accelerates a broad class of continuous-time sampling dynamics. For Langevin dynamics, our method encodes the target Gibbs measure into the amplitudes of a quantum state, identified as the kernel of a block matrix derived from a factorization of the Witten Laplacian operator. This connection enables Gibbs sampling via singular value thresholding and yields the first provable quantum advantage with respect to the Poincar\'e constant in the non-logconcave setting. Building on this framework, we further develop the first quantum algorithm that accelerates replica exchange Langevin diffusion, a widely used method for sampling from complex, rugged energy landscapes.
MathMistake Checker: A Comprehensive Demonstration for Step-by-Step Math Problem Mistake Finding by Prompt-Guided LLMs
Mar 06, 2025We propose a novel system, MathMistake Checker, designed to automate step-by-step mistake finding in mathematical problems with lengthy answers through a two-stage process. The system aims to simplify grading, increase efficiency, and enhance learning experiences from a pedagogical perspective. It integrates advanced technologies, including computer vision and the chain-of-thought capabilities of the latest large language models (LLMs). Our system supports open-ended grading without reference answers and promotes personalized learning by providing targeted feedback. We demonstrate its effectiveness across various types of math problems, such as calculation and word problems.
Worth Their Weight: Randomized and Regularized Block Kaczmarz Algorithms without Preprocessing
Feb 02, 2025



Due to the ever growing amounts of data leveraged for machine learning and scientific computing, it is increasingly important to develop algorithms that sample only a small portion of the data at a time. In the case of linear least-squares, the randomized block Kaczmarz method (RBK) is an appealing example of such an algorithm, but its convergence is only understood under sampling distributions that require potentially prohibitively expensive preprocessing steps. To address this limitation, we analyze RBK when the data is sampled uniformly, showing that its iterates converge in a Monte Carlo sense to a $\textit{weighted}$ least-squares solution. Unfortunately, for general problems the condition number of the weight matrix and the variance of the iterates can become arbitrarily large. We resolve these issues by incorporating regularization into the RBK iterations. Numerical experiments, including examples arising from natural gradient optimization, suggest that the regularized algorithm, ReBlocK, outperforms minibatch stochastic gradient descent for realistic problems that exhibit fast singular value decay.
Constructing Cell-type Taxonomy by Optimal Transport with Relaxed Marginal Constraints
Jan 29, 2025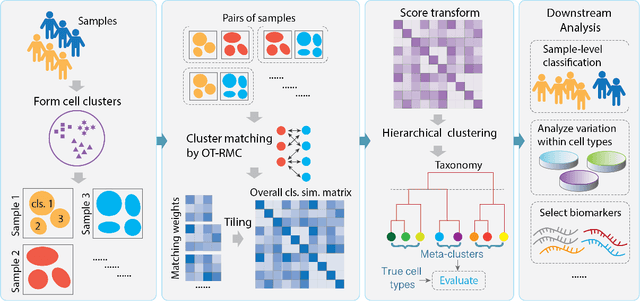
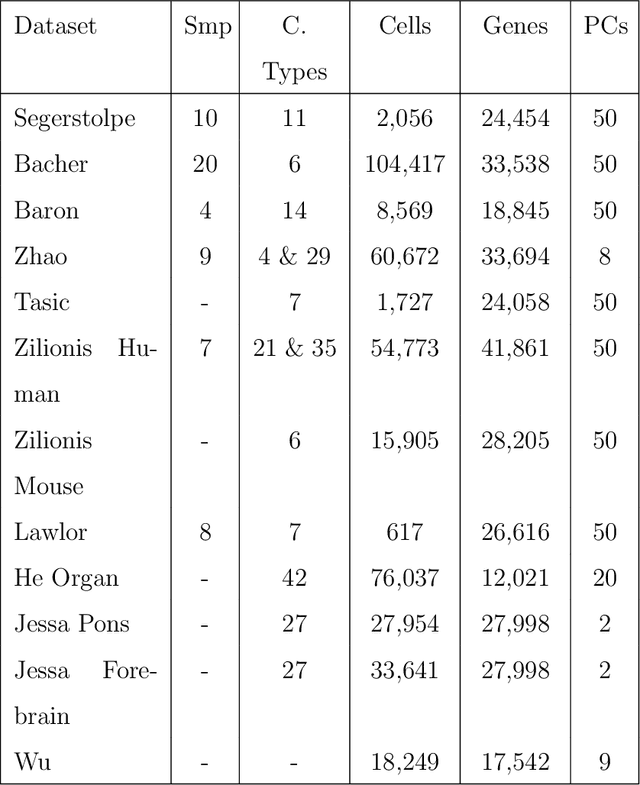
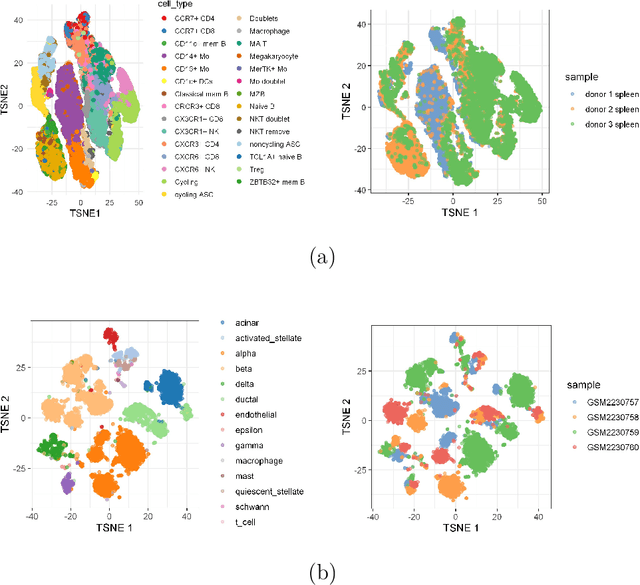
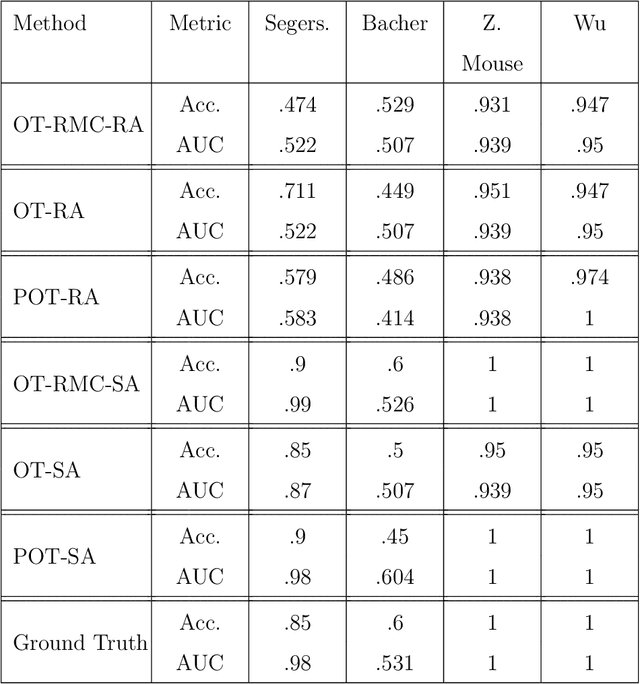
The rapid emergence of single-cell data has facilitated the study of many different biological conditions at the cellular level. Cluster analysis has been widely applied to identify cell types, capturing the essential patterns of the original data in a much more concise form. One challenge in the cluster analysis of cells is matching clusters extracted from datasets of different origins or conditions. Many existing algorithms cannot recognize new cell types present in only one of the two samples when establishing a correspondence between clusters obtained from two samples. Additionally, when there are more than two samples, it is advantageous to align clusters across all samples simultaneously rather than performing pairwise alignment. Our approach aims to construct a taxonomy for cell clusters across all samples to better annotate these clusters and effectively extract features for downstream analysis. A new system for constructing cell-type taxonomy has been developed by combining the technique of Optimal Transport with Relaxed Marginal Constraints (OT-RMC) and the simultaneous alignment of clusters across multiple samples. OT-RMC allows us to address challenges that arise when the proportions of clusters vary substantially between samples or when some clusters do not appear in all the samples. Experiments on more than twenty datasets demonstrate that the taxonomy constructed by this new system can yield highly accurate annotation of cell types. Additionally, sample-level features extracted based on the taxonomy result in accurate classification of samples.
RAG4ITOps: A Supervised Fine-Tunable and Comprehensive RAG Framework for IT Operations and Maintenance
Oct 21, 2024With the ever-increasing demands on Question Answering (QA) systems for IT operations and maintenance, an efficient and supervised fine-tunable framework is necessary to ensure the data security, private deployment and continuous upgrading. Although Large Language Models (LLMs) have notably improved the open-domain QA's performance, how to efficiently handle enterprise-exclusive corpora and build domain-specific QA systems are still less-studied for industrial applications. In this paper, we propose a general and comprehensive framework based on Retrieval Augmented Generation (RAG) and facilitate the whole business process of establishing QA systems for IT operations and maintenance. In accordance with the prevailing RAG method, our proposed framework, named with RAG4ITOps, composes of two major stages: (1) Models Fine-tuning \& Data Vectorization, and (2) Online QA System Process. At the Stage 1, we leverage a contrastive learning method with two negative sampling strategies to fine-tune the embedding model, and design the instruction templates to fine-tune the LLM with a Retrieval Augmented Fine-Tuning method. At the Stage 2, an efficient process of QA system is built for serving. We collect enterprise-exclusive corpora from the domain of cloud computing, and the extensive experiments show that our method achieves superior results than counterparts on two kinds of QA tasks. Our experiment also provide a case for applying the RAG4ITOps to real-world enterprise-level applications.