 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching
Apr 01, 2018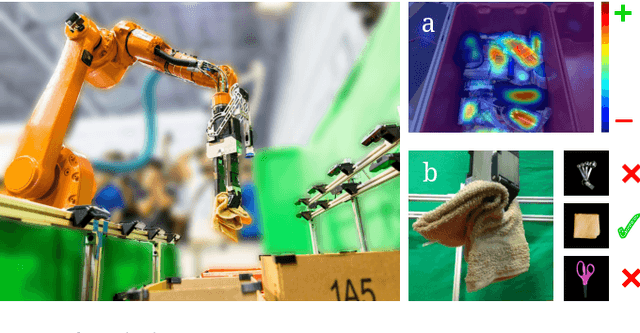


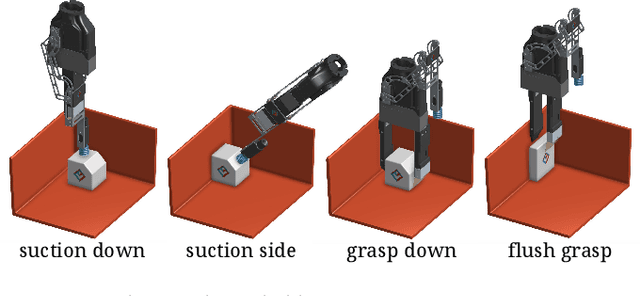
This paper presents a robotic pick-and-place system that is capable of grasping and recognizing both known and novel objects in cluttered environments. The key new feature of the system is that it handles a wide range of object categories without needing any task-specific training data for novel objects. To achieve this, it first uses a category-agnostic affordance prediction algorithm to select and execute among four different grasping primitive behaviors. It then recognizes picked objects with a cross-domain image classification framework that matches observed images to product images. Since product images are readily available for a wide range of objects (e.g., from the web), the system works out-of-the-box for novel objects without requiring any additional training data. Exhaustive experimental results demonstrate that our multi-affordance grasping achieves high success rates for a wide variety of objects in clutter, and our recognition algorithm achieves high accuracy for both known and novel grasped objects. The approach was part of the MIT-Princeton Team system that took 1st place in the stowing task at the 2017 Amazon Robotics Challenge. All code, datasets, and pre-trained models are available online at http://arc.cs.princeton.edu
Text2Shape: Generating Shapes from Natural Language by Learning Joint Embeddings
Mar 22, 2018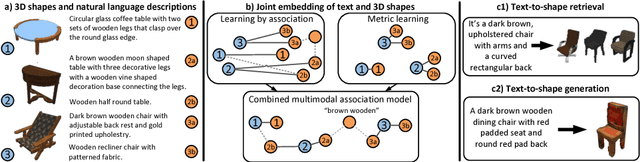



We present a method for generating colored 3D shapes from natural language. To this end, we first learn joint embeddings of freeform text descriptions and colored 3D shapes. Our model combines and extends learning by association and metric learning approaches to learn implicit cross-modal connections, and produces a joint representation that captures the many-to-many relations between language and physical properties of 3D shapes such as color and shape. To evaluate our approach, we collect a large dataset of natural language descriptions for physical 3D objects in the ShapeNet dataset. With this learned joint embedding we demonstrate text-to-shape retrieval that outperforms baseline approaches. Using our embeddings with a novel conditional Wasserstein GAN framework, we generate colored 3D shapes from text. Our method is the first to connect natural language text with realistic 3D objects exhibiting rich variations in color, texture, and shape detail. See video at https://youtu.be/zraPvRdl13Q
Interactive 3D Modeling with a Generative Adversarial Network
Jan 07, 2018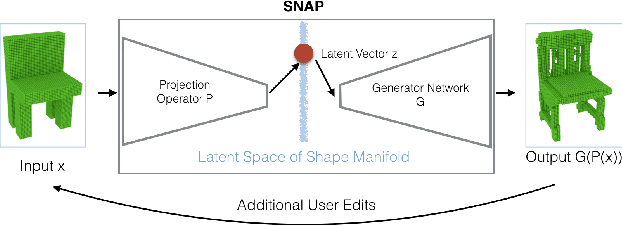
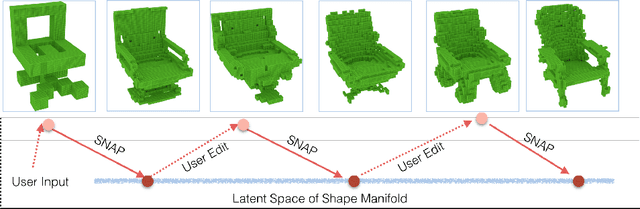
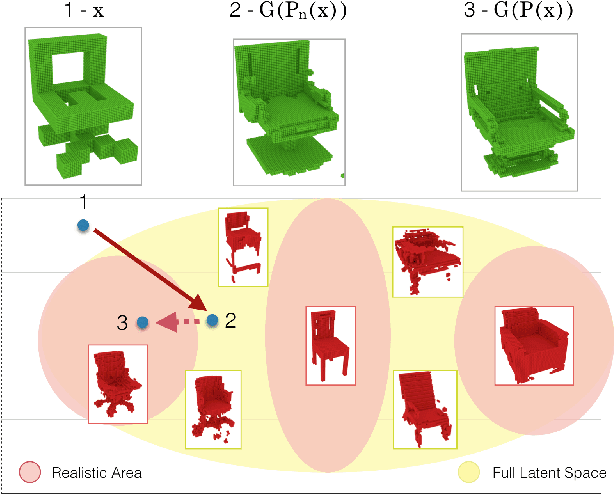
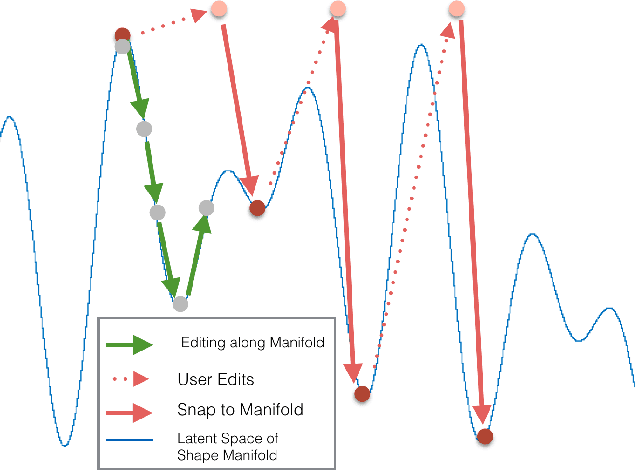
This paper proposes the idea of using a generative adversarial network (GAN) to assist a novice user in designing real-world shapes with a simple interface. The user edits a voxel grid with a painting interface (like Minecraft). Yet, at any time, he/she can execute a SNAP command, which projects the current voxel grid onto a latent shape manifold with a learned projection operator and then generates a similar, but more realistic, shape using a learned generator network. Then the user can edit the resulting shape and snap again until he/she is satisfied with the result. The main advantage of this approach is that the projection and generation operators assist novice users to create 3D models characteristic of a background distribution of object shapes, but without having to specify all the details. The core new research idea is to use a GAN to support this application. 3D GANs have previously been used for shape generation, interpolation, and completion, but never for interactive modeling. The new challenge for this application is to learn a projection operator that takes an arbitrary 3D voxel model and produces a latent vector on the shape manifold from which a similar and realistic shape can be generated. We develop algorithms for this and other steps of the SNAP processing pipeline and integrate them into a simple modeling tool. Experiments with these algorithms and tool suggest that GANs provide a promising approach to computer-assisted interactive modeling.
Im2Pano3D: Extrapolating 360 Structure and Semantics Beyond the Field of View
Dec 12, 2017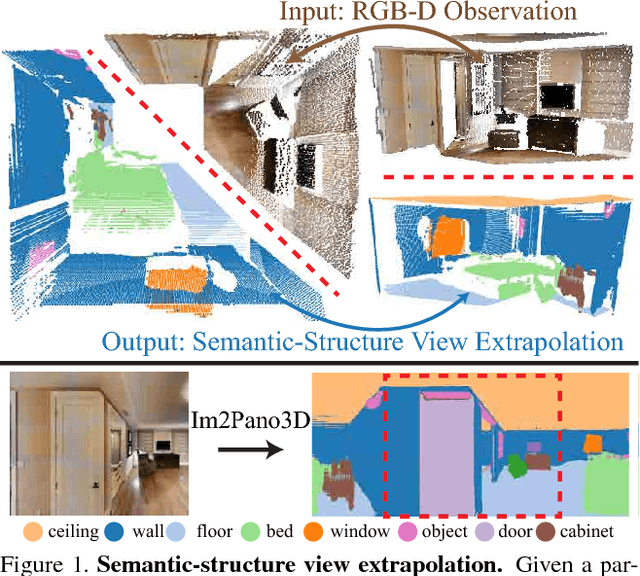
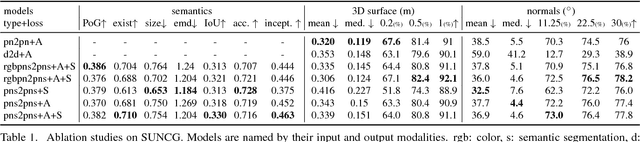
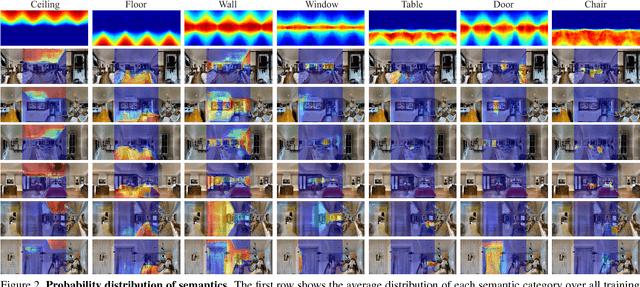
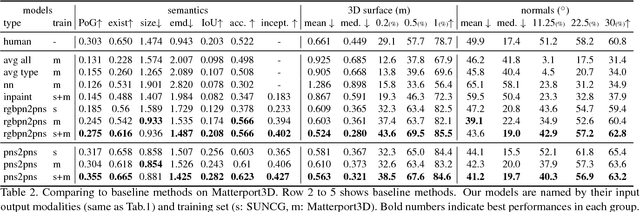
We present Im2Pano3D, a convolutional neural network that generates a dense prediction of 3D structure and a probability distribution of semantic labels for a full 360 panoramic view of an indoor scene when given only a partial observation (<= 50%) in the form of an RGB-D image. To make this possible, Im2Pano3D leverages strong contextual priors learned from large-scale synthetic and real-world indoor scenes. To ease the prediction of 3D structure, we propose to parameterize 3D surfaces with their plane equations and train the model to predict these parameters directly. To provide meaningful training supervision, we use multiple loss functions that consider both pixel level accuracy and global context consistency. Experiments demon- strate that Im2Pano3D is able to predict the semantics and 3D structure of the unobserved scene with more than 56% pixel accuracy and less than 0.52m average distance error, which is significantly better than alternative approaches.
MINOS: Multimodal Indoor Simulator for Navigation in Complex Environments
Dec 11, 2017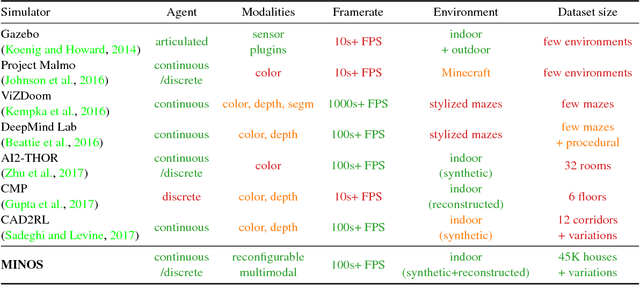
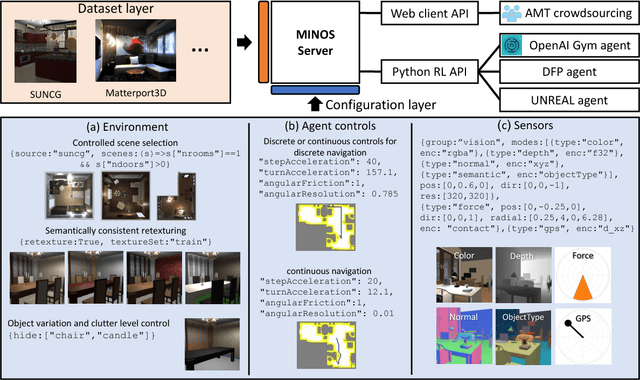

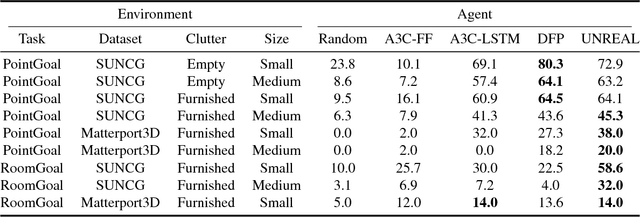
We present MINOS, a simulator designed to support the development of multisensory models for goal-directed navigation in complex indoor environments. The simulator leverages large datasets of complex 3D environments and supports flexible configuration of multimodal sensor suites. We use MINOS to benchmark deep-learning-based navigation methods, to analyze the influence of environmental complexity on navigation performance, and to carry out a controlled study of multimodality in sensorimotor learning. The experiments show that current deep reinforcement learning approaches fail in large realistic environments. The experiments also indicate that multimodality is beneficial in learning to navigate cluttered scenes. MINOS is released open-source to the research community at http://minosworld.org . A video that shows MINOS can be found at https://youtu.be/c0mL9K64q84
Large-Scale 3D Shape Reconstruction and Segmentation from ShapeNet Core55
Oct 27, 2017
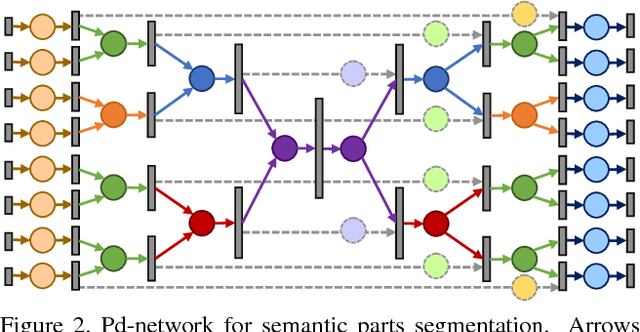
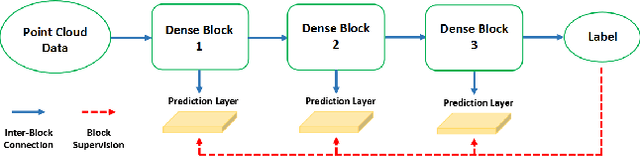
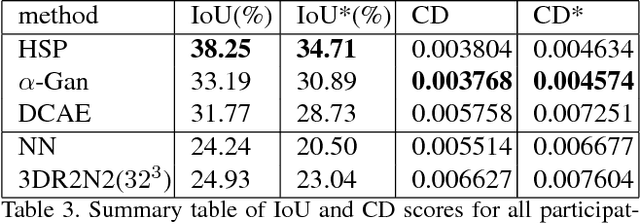
We introduce a large-scale 3D shape understanding benchmark using data and annotation from ShapeNet 3D object database. The benchmark consists of two tasks: part-level segmentation of 3D shapes and 3D reconstruction from single view images. Ten teams have participated in the challenge and the best performing teams have outperformed state-of-the-art approaches on both tasks. A few novel deep learning architectures have been proposed on various 3D representations on both tasks. We report the techniques used by each team and the corresponding performances. In addition, we summarize the major discoveries from the reported results and possible trends for the future work in the field.
Matterport3D: Learning from RGB-D Data in Indoor Environments
Sep 18, 2017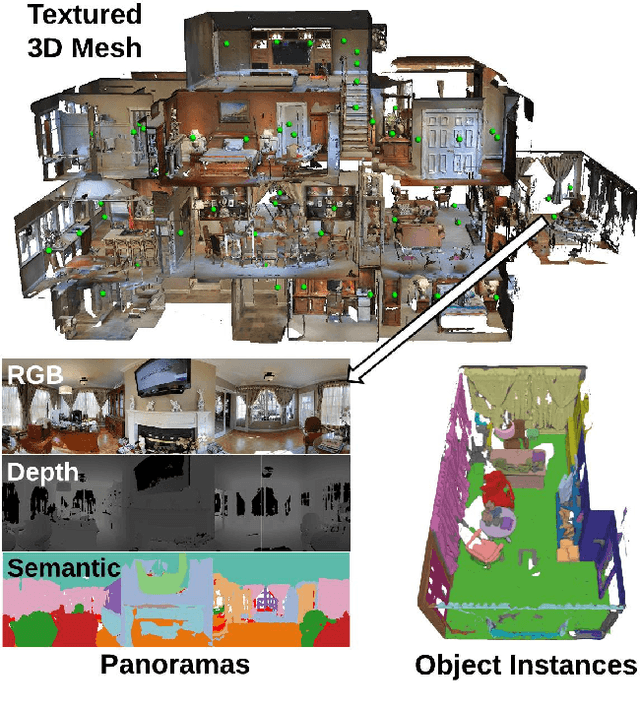

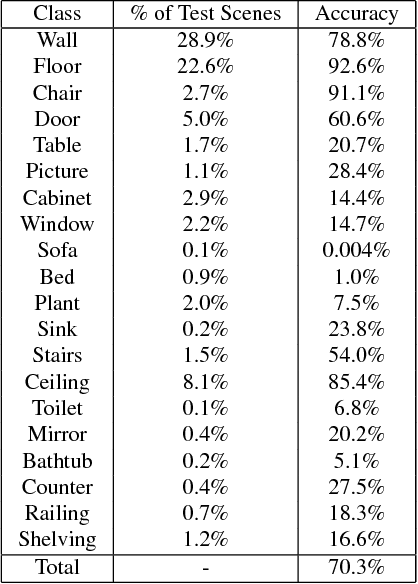

Access to large, diverse RGB-D datasets is critical for training RGB-D scene understanding algorithms. However, existing datasets still cover only a limited number of views or a restricted scale of spaces. In this paper, we introduce Matterport3D, a large-scale RGB-D dataset containing 10,800 panoramic views from 194,400 RGB-D images of 90 building-scale scenes. Annotations are provided with surface reconstructions, camera poses, and 2D and 3D semantic segmentations. The precise global alignment and comprehensive, diverse panoramic set of views over entire buildings enable a variety of supervised and self-supervised computer vision tasks, including keypoint matching, view overlap prediction, normal prediction from color, semantic segmentation, and region classification.
Physically-Based Rendering for Indoor Scene Understanding Using Convolutional Neural Networks
Jul 02, 2017
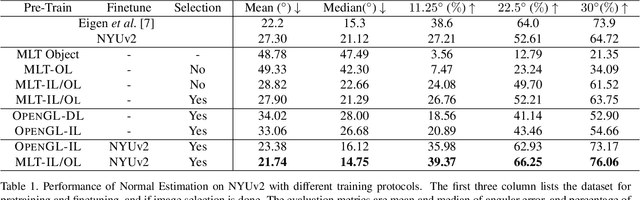


Indoor scene understanding is central to applications such as robot navigation and human companion assistance. Over the last years, data-driven deep neural networks have outperformed many traditional approaches thanks to their representation learning capabilities. One of the bottlenecks in training for better representations is the amount of available per-pixel ground truth data that is required for core scene understanding tasks such as semantic segmentation, normal prediction, and object edge detection. To address this problem, a number of works proposed using synthetic data. However, a systematic study of how such synthetic data is generated is missing. In this work, we introduce a large-scale synthetic dataset with 400K physically-based rendered images from 45K realistic 3D indoor scenes. We study the effects of rendering methods and scene lighting on training for three computer vision tasks: surface normal prediction, semantic segmentation, and object boundary detection. This study provides insights into the best practices for training with synthetic data (more realistic rendering is worth it) and shows that pretraining with our new synthetic dataset can improve results beyond the current state of the art on all three tasks.
Dilated Residual Networks
May 28, 2017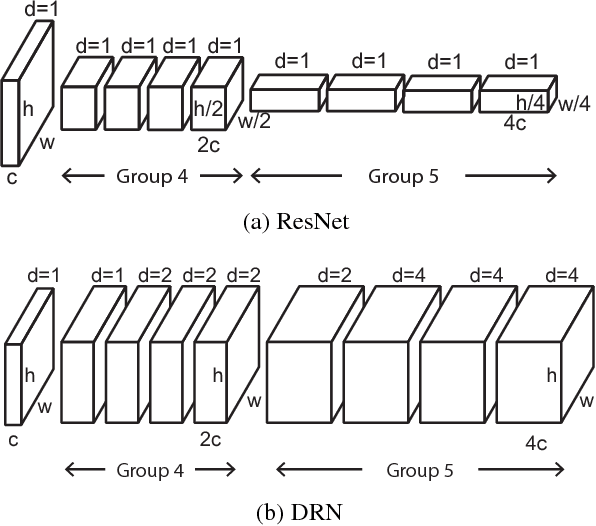
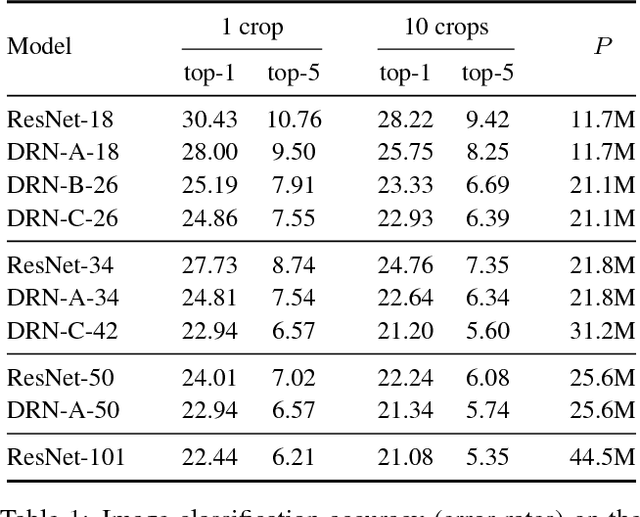
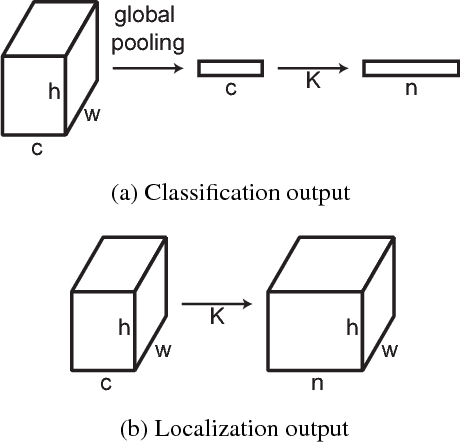
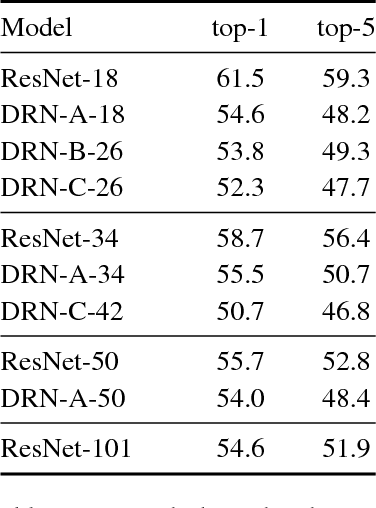
Convolutional networks for image classification progressively reduce resolution until the image is represented by tiny feature maps in which the spatial structure of the scene is no longer discernible. Such loss of spatial acuity can limit image classification accuracy and complicate the transfer of the model to downstream applications that require detailed scene understanding. These problems can be alleviated by dilation, which increases the resolution of output feature maps without reducing the receptive field of individual neurons. We show that dilated residual networks (DRNs) outperform their non-dilated counterparts in image classification without increasing the model's depth or complexity. We then study gridding artifacts introduced by dilation, develop an approach to removing these artifacts (`degridding'), and show that this further increases the performance of DRNs. In addition, we show that the accuracy advantage of DRNs is further magnified in downstream applications such as object localization and semantic segmentation.
ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes
Apr 11, 2017



A key requirement for leveraging supervised deep learning methods is the availability of large, labeled datasets. Unfortunately, in the context of RGB-D scene understanding, very little data is available -- current datasets cover a small range of scene views and have limited semantic annotations. To address this issue, we introduce ScanNet, an RGB-D video dataset containing 2.5M views in 1513 scenes annotated with 3D camera poses, surface reconstructions, and semantic segmentations. To collect this data, we designed an easy-to-use and scalable RGB-D capture system that includes automated surface reconstruction and crowdsourced semantic annotation. We show that using this data helps achieve state-of-the-art performance on several 3D scene understanding tasks, including 3D object classification, semantic voxel labeling, and CAD model retrieval. The dataset is freely available at http://www.scan-net.org.