 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Haircut: Prior-Guided Strand-Based Hair Reconstruction
Jun 12, 2023



Generating realistic human 3D reconstructions using image or video data is essential for various communication and entertainment applications. While existing methods achieved impressive results for body and facial regions, realistic hair modeling still remains challenging due to its high mechanical complexity. This work proposes an approach capable of accurate hair geometry reconstruction at a strand level from a monocular video or multi-view images captured in uncontrolled lighting conditions. Our method has two stages, with the first stage performing joint reconstruction of coarse hair and bust shapes and hair orientation using implicit volumetric representations. The second stage then estimates a strand-level hair reconstruction by reconciling in a single optimization process the coarse volumetric constraints with hair strand and hairstyle priors learned from the synthetic data. To further increase the reconstruction fidelity, we incorporate image-based losses into the fitting process using a new differentiable renderer. The combined system, named Neural Haircut, achieves high realism and personalization of the reconstructed hairstyles.
MoRF: Mobile Realistic Fullbody Avatars from a Monocular Video
Mar 17, 2023



We present a new approach for learning Mobile Realistic Fullbody (MoRF) avatars. MoRF avatars can be rendered in real-time on mobile phones, have high realism, and can be learned from monocular videos. As in previous works, we use a combination of neural textures and the mesh-based body geometry modeling SMPL-X. We improve on prior work, by learning per-frame warping fields in the neural texture space, allowing to better align the training signal between different frames. We also apply existing SMPL-X fitting procedure refinements for videos to improve overall avatar quality. In the comparisons to other monocular video-based avatar systems, MoRF avatars achieve higher image sharpness and temporal consistency. Participants of our user study also preferred avatars generated by MoRF.
DINAR: Diffusion Inpainting of Neural Textures for One-Shot Human Avatars
Mar 17, 2023



We present DINAR, an approach for creating realistic rigged fullbody avatars from single RGB images. Similarly to previous works, our method uses neural textures combined with the SMPL-X body model to achieve photo-realistic quality of avatars while keeping them easy to animate and fast to infer. To restore the texture, we use a latent diffusion model and show how such model can be trained in the neural texture space. The use of the diffusion model allows us to realistically reconstruct large unseen regions such as the back of a person given the frontal view. The models in our pipeline are trained using 2D images and videos only. In the experiments, our approach achieves state-of-the-art rendering quality and good generalization to new poses and viewpoints. In particular, the approach improves state-of-the-art on the SnapshotPeople public benchmark.
Multi-NeuS: 3D Head Portraits from Single Image with Neural Implicit Functions
Sep 07, 2022
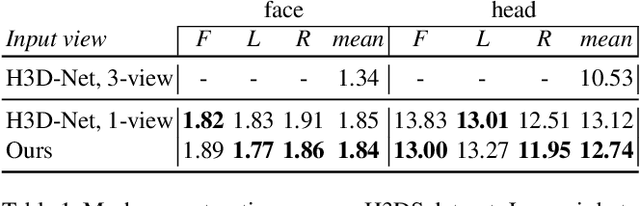
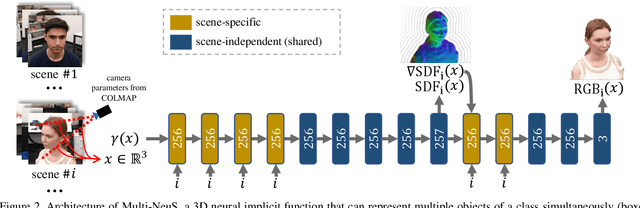

We present an approach for the reconstruction of textured 3D meshes of human heads from one or few views. Since such few-shot reconstruction is underconstrained, it requires prior knowledge which is hard to impose on traditional 3D reconstruction algorithms. In this work, we rely on the recently introduced 3D representation $\unicode{x2013}$ neural implicit functions $\unicode{x2013}$ which, being based on neural networks, allows to naturally learn priors about human heads from data, and is directly convertible to textured mesh. Namely, we extend NeuS, a state-of-the-art neural implicit function formulation, to represent multiple objects of a class (human heads in our case) simultaneously. The underlying neural net architecture is designed to learn the commonalities among these objects and to generalize to unseen ones. Our model is trained on just a hundred smartphone videos and does not require any scanned 3D data. Afterwards, the model can fit novel heads in the few-shot or one-shot modes with good results.
MegaPortraits: One-shot Megapixel Neural Head Avatars
Jul 15, 2022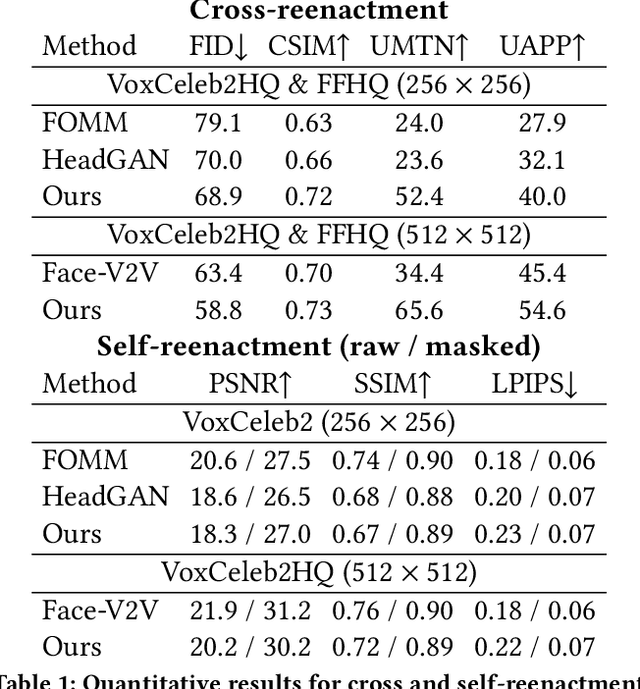
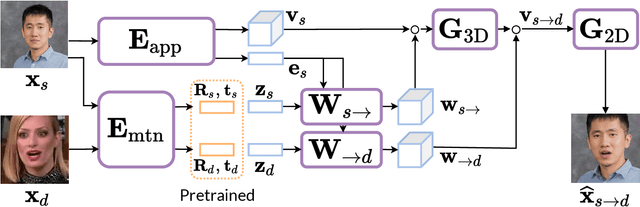
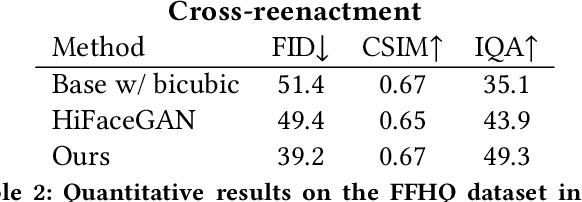

In this work, we advance the neural head avatar technology to the megapixel resolution while focusing on the particularly challenging task of cross-driving synthesis, i.e., when the appearance of the driving image is substantially different from the animated source image. We propose a set of new neural architectures and training methods that can leverage both medium-resolution video data and high-resolution image data to achieve the desired levels of rendered image quality and generalization to novel views and motion. We demonstrate that suggested architectures and methods produce convincing high-resolution neural avatars, outperforming the competitors in the cross-driving scenario. Lastly, we show how a trained high-resolution neural avatar model can be distilled into a lightweight student model which runs in real-time and locks the identities of neural avatars to several dozens of pre-defined source images. Real-time operation and identity lock are essential for many practical applications head avatar systems.
Realistic One-shot Mesh-based Head Avatars
Jun 16, 2022
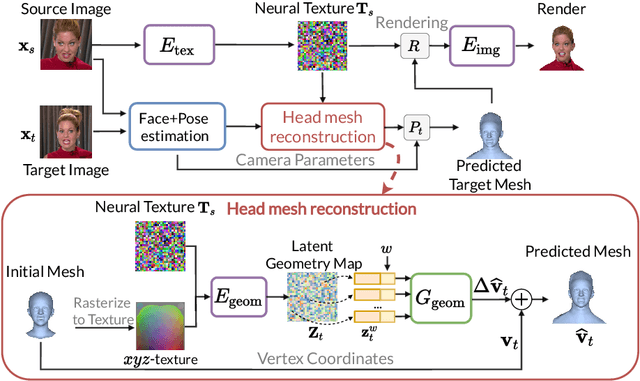
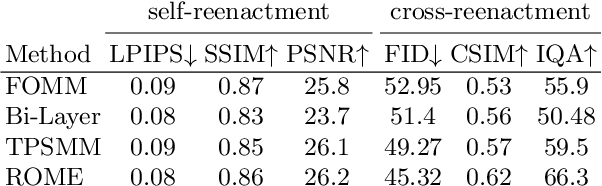
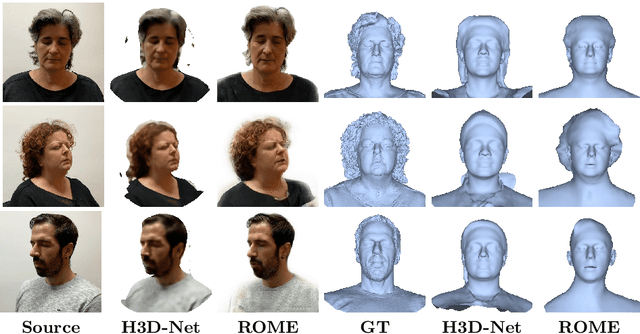
We present a system for realistic one-shot mesh-based human head avatars creation, ROME for short. Using a single photograph, our model estimates a person-specific head mesh and the associated neural texture, which encodes both local photometric and geometric details. The resulting avatars are rigged and can be rendered using a neural network, which is trained alongside the mesh and texture estimators on a dataset of in-the-wild videos. In the experiments, we observe that our system performs competitively both in terms of head geometry recovery and the quality of renders, especially for the cross-person reenactment. See results https://samsunglabs.github.io/rome/
NPBG++: Accelerating Neural Point-Based Graphics
Mar 24, 2022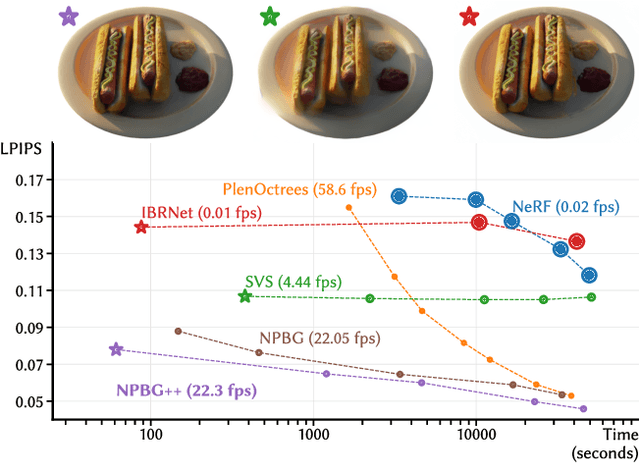
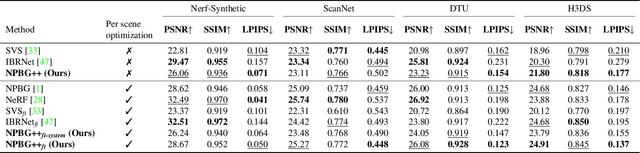
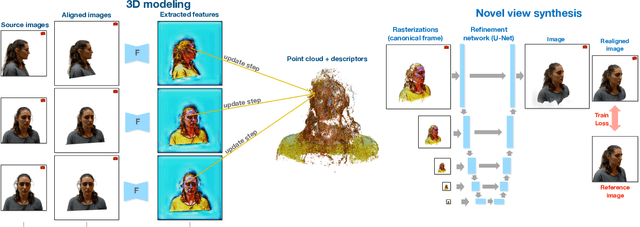
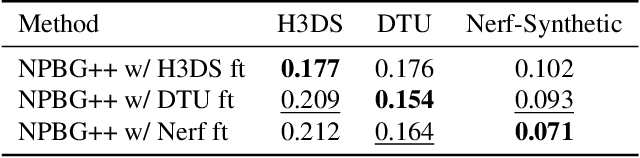
We present a new system (NPBG++) for the novel view synthesis (NVS) task that achieves high rendering realism with low scene fitting time. Our method efficiently leverages the multiview observations and the point cloud of a static scene to predict a neural descriptor for each point, improving upon the pipeline of Neural Point-Based Graphics in several important ways. By predicting the descriptors with a single pass through the source images, we lift the requirement of per-scene optimization while also making the neural descriptors view-dependent and more suitable for scenes with strong non-Lambertian effects. In our comparisons, the proposed system outperforms previous NVS approaches in terms of fitting and rendering runtimes while producing images of similar quality.
Stereo Magnification with Multi-Layer Images
Jan 13, 2022
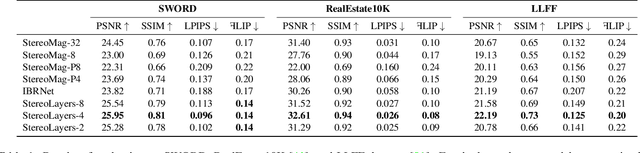

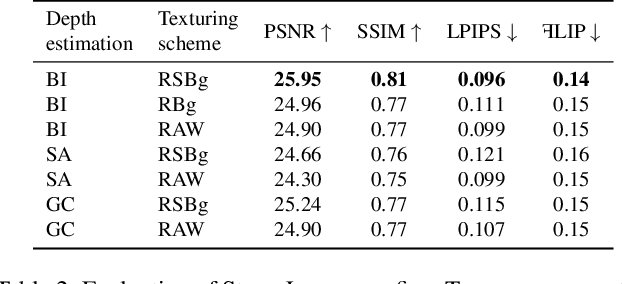
Representing scenes with multiple semi-transparent colored layers has been a popular and successful choice for real-time novel view synthesis. Existing approaches infer colors and transparency values over regularly-spaced layers of planar or spherical shape. In this work, we introduce a new view synthesis approach based on multiple semi-transparent layers with scene-adapted geometry. Our approach infers such representations from stereo pairs in two stages. The first stage infers the geometry of a small number of data-adaptive layers from a given pair of views. The second stage infers the color and the transparency values for these layers producing the final representation for novel view synthesis. Importantly, both stages are connected through a differentiable renderer and are trained in an end-to-end manner. In the experiments, we demonstrate the advantage of the proposed approach over the use of regularly-spaced layers with no adaptation to scene geometry. Despite being orders of magnitude faster during rendering, our approach also outperforms a recently proposed IBRNet system based on implicit geometry representation. See results at https://samsunglabs.github.io/StereoLayers .
Resolution-robust Large Mask Inpainting with Fourier Convolutions
Sep 15, 2021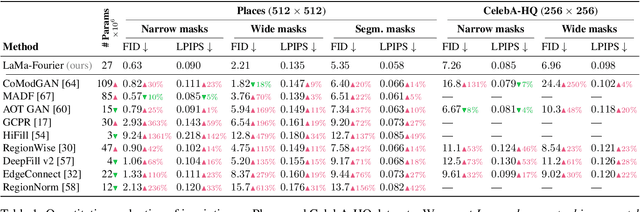
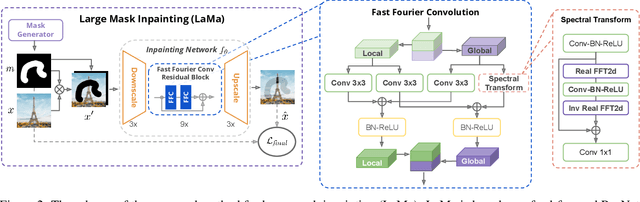
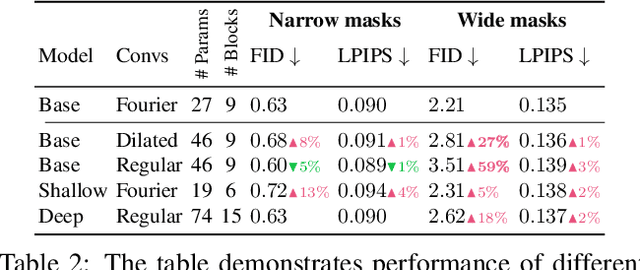

Modern image inpainting systems, despite the significant progress, often struggle with large missing areas, complex geometric structures, and high-resolution images. We find that one of the main reasons for that is the lack of an effective receptive field in both the inpainting network and the loss function. To alleviate this issue, we propose a new method called large mask inpainting (LaMa). LaMa is based on i) a new inpainting network architecture that uses fast Fourier convolutions, which have the image-wide receptive field; ii) a high receptive field perceptual loss; and iii) large training masks, which unlocks the potential of the first two components. Our inpainting network improves the state-of-the-art across a range of datasets and achieves excellent performance even in challenging scenarios, e.g. completion of periodic structures. Our model generalizes surprisingly well to resolutions that are higher than those seen at train time, and achieves this at lower parameter&compute costs than the competitive baselines. The code is available at https://github.com/saic-mdal/lama.
Perceptual Gradient Networks
May 05, 2021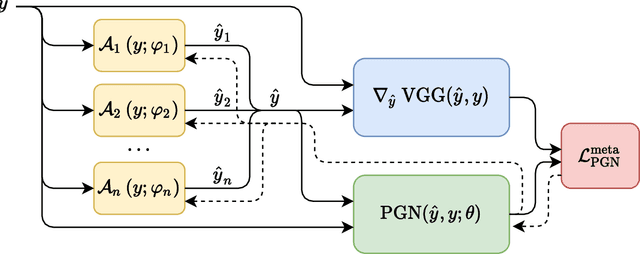
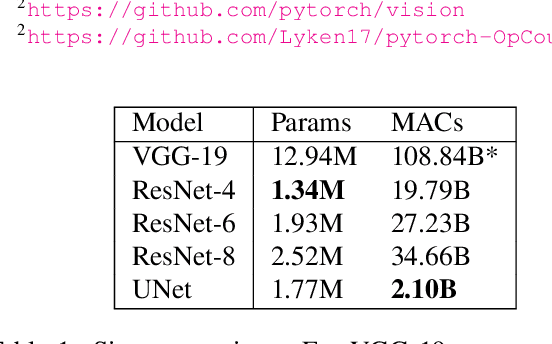
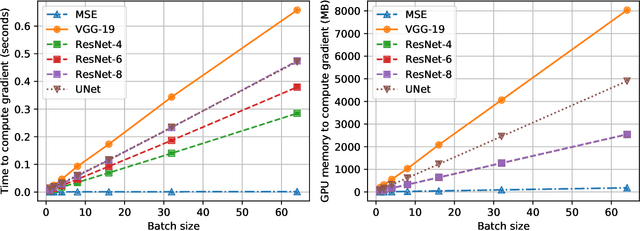
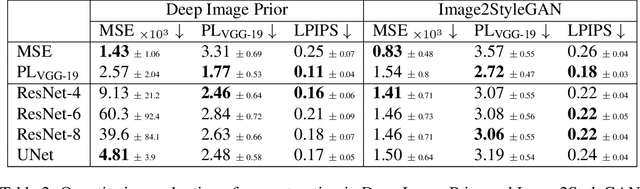
Many applications of deep learning for image generation use perceptual losses for either training or fine-tuning of the generator networks. The use of perceptual loss however incurs repeated forward-backward passes in a large image classification network as well as a considerable memory overhead required to store the activations of this network. It is therefore desirable or sometimes even critical to get rid of these overheads. In this work, we propose a way to train generator networks using approximations of perceptual loss that are computed without forward-backward passes. Instead, we use a simpler perceptual gradient network that directly synthesizes the gradient field of a perceptual loss. We introduce the concept of proxy targets, which stabilize the predicted gradient, meaning that learning with it does not lead to divergence or oscillations. In addition, our method allows interpretation of the predicted gradient, providing insight into the internals of perceptual loss and suggesting potential ways to improve it in future work.