 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Preserving Reinforcement Learning
Mar 12, 2026Policy gradient algorithms have driven many recent advancements in language model reasoning. An appealing property is their ability to learn from exploration on their own trajectories, a process crucial for fostering diverse and creative solutions. As we show in this paper, many policy gradient algorithms naturally reduce the entropy -- and thus the diversity of explored trajectories -- as part of training, yielding a policy increasingly limited in its ability to explore. In this paper, we argue that entropy should be actively monitored and controlled throughout training. We formally analyze the contributions of leading policy gradient objectives on entropy dynamics, identify empirical factors (such as numerical precision) that significantly impact entropy behavior, and propose explicit mechanisms for entropy control. These include REPO, a family of algorithms that modify the advantage function to regulate entropy, and ADAPO, an adaptive asymmetric clipping approach. Models trained with our entropy-preserving methods maintain diversity throughout training, yielding final policies that are more performant and retain their trainability for sequential learning in new environments.
* Published at ICLR 2026
RAGPerf: An End-to-End Benchmarking Framework for Retrieval-Augmented Generation Systems
Mar 11, 2026We present the design and implementation of a RAG-based AI system benchmarking (RAGPerf) framework for characterizing the system behaviors of RAG pipelines. To facilitate detailed profiling and fine-grained performance analysis, RAGPerf decouples the RAG workflow into several modular components - embedding, indexing, retrieval, reranking, and generation. RAGPerf offers the flexibility for users to configure the core parameters of each component and examine their impact on the end-to-end query performance and quality. RAGPerf has a workload generator to model real-world scenarios by supporting diverse datasets (e.g., text, pdf, code, and audio), different retrieval and update ratios, and query distributions. RAGPerf also supports different embedding models, major vector databases such as LanceDB, Milvus, Qdrant, Chroma, and Elasticsearch, as well as different LLMs for content generation. It automates the collection of performance metrics (i.e., end-to-end query throughput, host/GPU memory footprint, and CPU/GPU utilization) and accuracy metrics (i.e., context recall, query accuracy, and factual consistency). We demonstrate the capabilities of RAGPerf through a comprehensive set of experiments and open source its codebase at GitHub. Our evaluation shows that RAGPerf incurs negligible performance overhead.
MoCap2Radar: A Spatiotemporal Transformer for Synthesizing Micro-Doppler Radar Signatures from Motion Capture
Nov 14, 2025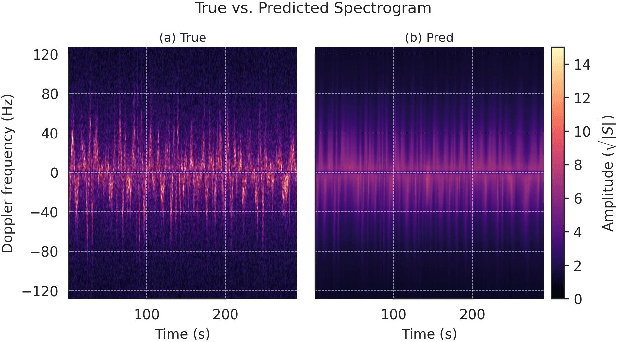
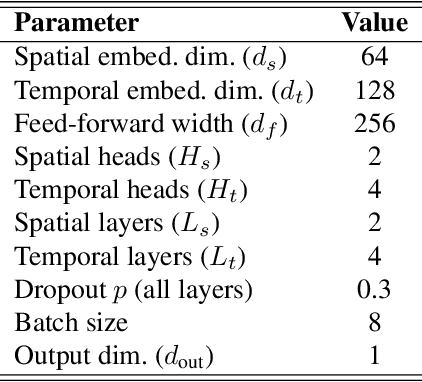
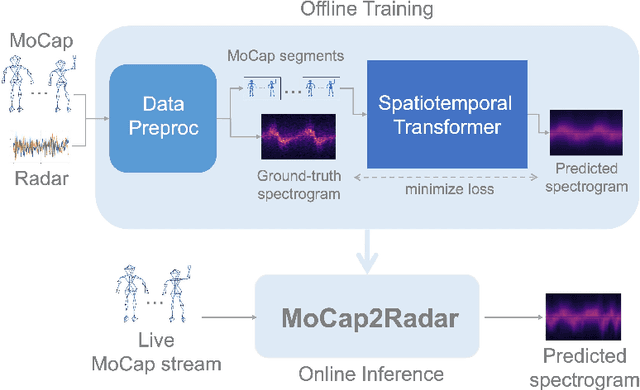
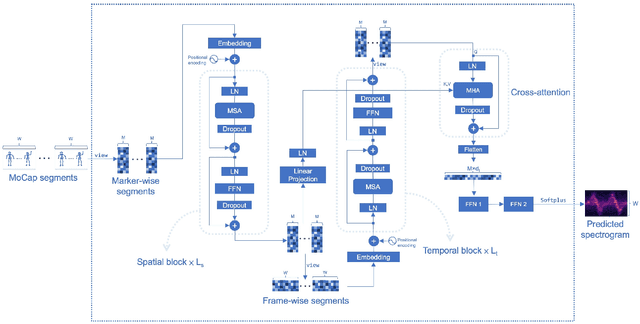
We present a pure machine learning process for synthesizing radar spectrograms from Motion-Capture (MoCap) data. We formulate MoCap-to-spectrogram translation as a windowed sequence-to-sequence task using a transformer-based model that jointly captures spatial relations among MoCap markers and temporal dynamics across frames. Real-world experiments show that the proposed approach produces visually and quantitatively plausible doppler radar spectrograms and achieves good generalizability. Ablation experiments show that the learned model includes both the ability to convert multi-part motion into doppler signatures and an understanding of the spatial relations between different parts of the human body. The result is an interesting example of using transformers for time-series signal processing. It is especially applicable to edge computing and Internet of Things (IoT) radars. It also suggests the ability to augment scarce radar datasets using more abundant MoCap data for training higher-level applications. Finally, it requires far less computation than physics-based methods for generating radar data.
Defurnishing with X-Ray Vision: Joint Removal of Furniture from Panoramas and Mesh
Jun 06, 2025



We present a pipeline for generating defurnished replicas of indoor spaces represented as textured meshes and corresponding multi-view panoramic images. To achieve this, we first segment and remove furniture from the mesh representation, extend planes, and fill holes, obtaining a simplified defurnished mesh (SDM). This SDM acts as an ``X-ray'' of the scene's underlying structure, guiding the defurnishing process. We extract Canny edges from depth and normal images rendered from the SDM. We then use these as a guide to remove the furniture from panorama images via ControlNet inpainting. This control signal ensures the availability of global geometric information that may be hidden from a particular panoramic view by the furniture being removed. The inpainted panoramas are used to texture the mesh. We show that our approach produces higher quality assets than methods that rely on neural radiance fields, which tend to produce blurry low-resolution images, or RGB-D inpainting, which is highly susceptible to hallucinations.
Reinforcement Learning for Long-Horizon Interactive LLM Agents
Feb 04, 2025Interactive digital agents (IDAs) leverage APIs of stateful digital environments to perform tasks in response to user requests. While IDAs powered by instruction-tuned large language models (LLMs) can react to feedback from interface invocations in multi-step exchanges, they have not been trained in their respective digital environments. Prior methods accomplish less than half of tasks in sophisticated benchmarks such as AppWorld. We present a reinforcement learning (RL) approach that trains IDAs directly in their target environments. We formalize this training as a partially observable Markov decision process and derive LOOP, a data- and memory-efficient variant of proximal policy optimization. LOOP uses no value network and maintains exactly one copy of the underlying LLM in memory, making its implementation straightforward and as memory-efficient as fine-tuning a single LLM. A 32-billion-parameter agent trained with LOOP in the AppWorld environment outperforms the much larger OpenAI o1 agent by 9 percentage points (15% relative). To our knowledge, this is the first reported application of RL to IDAs that interact with a stateful, multi-domain, multi-app environment via direct API calls. Our analysis sheds light on the effectiveness of RL in this area, showing that the agent learns to consult the API documentation, avoid unwarranted assumptions, minimize confabulation, and recover from setbacks.
ActiveGAMER: Active GAussian Mapping through Efficient Rendering
Jan 12, 2025



We introduce ActiveGAMER, an active mapping system that utilizes 3D Gaussian Splatting (3DGS) to achieve high-quality, real-time scene mapping and exploration. Unlike traditional NeRF-based methods, which are computationally demanding and restrict active mapping performance, our approach leverages the efficient rendering capabilities of 3DGS, allowing effective and efficient exploration in complex environments. The core of our system is a rendering-based information gain module that dynamically identifies the most informative viewpoints for next-best-view planning, enhancing both geometric and photometric reconstruction accuracy. ActiveGAMER also integrates a carefully balanced framework, combining coarse-to-fine exploration, post-refinement, and a global-local keyframe selection strategy to maximize reconstruction completeness and fidelity. Our system autonomously explores and reconstructs environments with state-of-the-art geometric and photometric accuracy and completeness, significantly surpassing existing approaches in both aspects. Extensive evaluations on benchmark datasets such as Replica and MP3D highlight ActiveGAMER's effectiveness in active mapping tasks.
AGGA: A Dataset of Academic Guidelines for Generative AI and Large Language Models
Jan 07, 2025
This study introduces AGGA, a dataset comprising 80 academic guidelines for the use of Generative AIs (GAIs) and Large Language Models (LLMs) in academic settings, meticulously collected from official university websites. The dataset contains 188,674 words and serves as a valuable resource for natural language processing tasks commonly applied in requirements engineering, such as model synthesis, abstraction identification, and document structure assessment. Additionally, AGGA can be further annotated to function as a benchmark for various tasks, including ambiguity detection, requirements categorization, and the identification of equivalent requirements. Our methodologically rigorous approach ensured a thorough examination, with a selection of universities that represent a diverse range of global institutions, including top-ranked universities across six continents. The dataset captures perspectives from a variety of academic fields, including humanities, technology, and both public and private institutions, offering a broad spectrum of insights into the integration of GAIs and LLMs in academia.
An Empty Room is All We Want: Automatic Defurnishing of Indoor Panoramas
May 06, 2024



We propose a pipeline that leverages Stable Diffusion to improve inpainting results in the context of defurnishing -- the removal of furniture items from indoor panorama images. Specifically, we illustrate how increased context, domain-specific model fine-tuning, and improved image blending can produce high-fidelity inpaints that are geometrically plausible without needing to rely on room layout estimation. We demonstrate qualitative and quantitative improvements over other furniture removal techniques.
Stereo-NEC: Enhancing Stereo Visual-Inertial SLAM Initialization with Normal Epipolar Constraints
Mar 12, 2024



We propose an accurate and robust initialization approach for stereo visual-inertial SLAM systems. Unlike the current state-of-the-art method, which heavily relies on the accuracy of a pure visual SLAM system to estimate inertial variables without updating camera poses, potentially compromising accuracy and robustness, our approach offers a different solution. We realize the crucial impact of precise gyroscope bias estimation on rotation accuracy. This, in turn, affects trajectory accuracy due to the accumulation of translation errors. To address this, we first independently estimate the gyroscope bias and use it to formulate a maximum a posteriori problem for further refinement. After this refinement, we proceed to update the rotation estimation by performing IMU integration with gyroscope bias removed from gyroscope measurements. We then leverage robust and accurate rotation estimates to enhance translation estimation via 3-DoF bundle adjustment. Moreover, we introduce a novel approach for determining the success of the initialization by evaluating the residual of the normal epipolar constraint. Extensive evaluations on the EuRoC dataset illustrate that our method excels in accuracy and robustness. It outperforms ORB-SLAM3, the current leading stereo visual-inertial initialization method, in terms of absolute trajectory error and relative rotation error, while maintaining competitive computational speed. Notably, even with 5 keyframes for initialization, our method consistently surpasses the state-of-the-art approach using 10 keyframes in rotation accuracy.
Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation
Sep 02, 2021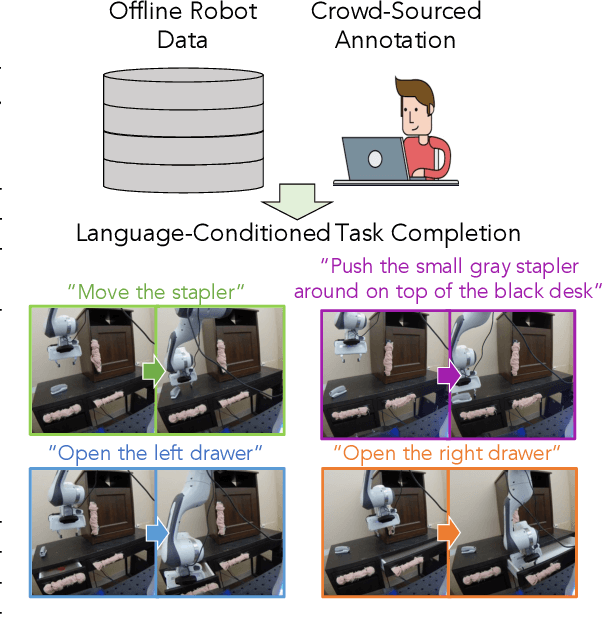
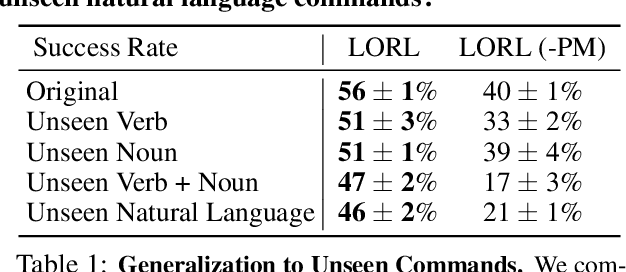
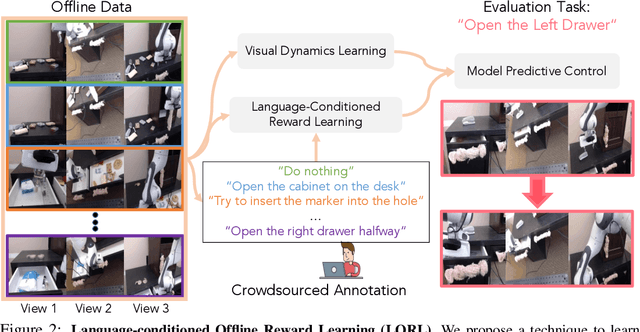

We study the problem of learning a range of vision-based manipulation tasks from a large offline dataset of robot interaction. In order to accomplish this, humans need easy and effective ways of specifying tasks to the robot. Goal images are one popular form of task specification, as they are already grounded in the robot's observation space. However, goal images also have a number of drawbacks: they are inconvenient for humans to provide, they can over-specify the desired behavior leading to a sparse reward signal, or under-specify task information in the case of non-goal reaching tasks. Natural language provides a convenient and flexible alternative for task specification, but comes with the challenge of grounding language in the robot's observation space. To scalably learn this grounding we propose to leverage offline robot datasets (including highly sub-optimal, autonomously collected data) with crowd-sourced natural language labels. With this data, we learn a simple classifier which predicts if a change in state completes a language instruction. This provides a language-conditioned reward function that can then be used for offline multi-task RL. In our experiments, we find that on language-conditioned manipulation tasks our approach outperforms both goal-image specifications and language conditioned imitation techniques by more than 25%, and is able to perform visuomotor tasks from natural language, such as "open the right drawer" and "move the stapler", on a Franka Emika Panda robot.