 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoDiff3D: Self-Supervised 3D Scene Generation with Geometry-Constrained 2D Diffusion Guidance
Jan 28, 20263D scene generation is a core technology for gaming, film/VFX, and VR/AR. Growing demand for rapid iteration, high-fidelity detail, and accessible content creation has further increased interest in this area. Existing methods broadly follow two paradigms - indirect 2D-to-3D reconstruction and direct 3D generation - but both are limited by weak structural modeling and heavy reliance on large-scale ground-truth supervision, often producing structural artifacts, geometric inconsistencies, and degraded high-frequency details in complex scenes. We propose GeoDiff3D, an efficient self-supervised framework that uses coarse geometry as a structural anchor and a geometry-constrained 2D diffusion model to provide texture-rich reference images. Importantly, GeoDiff3D does not require strict multi-view consistency of the diffusion-generated references and remains robust to the resulting noisy, inconsistent guidance. We further introduce voxel-aligned 3D feature aggregation and dual self-supervision to maintain scene coherence and fine details while substantially reducing dependence on labeled data. GeoDiff3D also trains with low computational cost and enables fast, high-quality 3D scene generation. Extensive experiments on challenging scenes show improved generalization and generation quality over existing baselines, offering a practical solution for accessible and efficient 3D scene construction.
CAGE-GS: High-fidelity Cage Based 3D Gaussian Splatting Deformation
Apr 17, 2025



As 3D Gaussian Splatting (3DGS) gains popularity as a 3D representation of real scenes, enabling user-friendly deformation to create novel scenes while preserving fine details from the original 3DGS has attracted significant research attention. We introduce CAGE-GS, a cage-based 3DGS deformation method that seamlessly aligns a source 3DGS scene with a user-defined target shape. Our approach learns a deformation cage from the target, which guides the geometric transformation of the source scene. While the cages effectively control structural alignment, preserving the textural appearance of 3DGS remains challenging due to the complexity of covariance parameters. To address this, we employ a Jacobian matrix-based strategy to update the covariance parameters of each Gaussian, ensuring texture fidelity post-deformation. Our method is highly flexible, accommodating various target shape representations, including texts, images, point clouds, meshes and 3DGS models. Extensive experiments and ablation studies on both public datasets and newly proposed scenes demonstrate that our method significantly outperforms existing techniques in both efficiency and deformation quality.
ARAP-GS: Drag-driven As-Rigid-As-Possible 3D Gaussian Splatting Editing with Diffusion Prior
Apr 17, 2025Drag-driven editing has become popular among designers for its ability to modify complex geometric structures through simple and intuitive manipulation, allowing users to adjust and reshape content with minimal technical skill. This drag operation has been incorporated into numerous methods to facilitate the editing of 2D images and 3D meshes in design. However, few studies have explored drag-driven editing for the widely-used 3D Gaussian Splatting (3DGS) representation, as deforming 3DGS while preserving shape coherence and visual continuity remains challenging. In this paper, we introduce ARAP-GS, a drag-driven 3DGS editing framework based on As-Rigid-As-Possible (ARAP) deformation. Unlike previous 3DGS editing methods, we are the first to apply ARAP deformation directly to 3D Gaussians, enabling flexible, drag-driven geometric transformations. To preserve scene appearance after deformation, we incorporate an advanced diffusion prior for image super-resolution within our iterative optimization process. This approach enhances visual quality while maintaining multi-view consistency in the edited results. Experiments show that ARAP-GS outperforms current methods across diverse 3D scenes, demonstrating its effectiveness and superiority for drag-driven 3DGS editing. Additionally, our method is highly efficient, requiring only 10 to 20 minutes to edit a scene on a single RTX 3090 GPU.
LL-Gaussian: Low-Light Scene Reconstruction and Enhancement via Gaussian Splatting for Novel View Synthesis
Apr 15, 2025Novel view synthesis (NVS) in low-light scenes remains a significant challenge due to degraded inputs characterized by severe noise, low dynamic range (LDR) and unreliable initialization. While recent NeRF-based approaches have shown promising results, most suffer from high computational costs, and some rely on carefully captured or pre-processed data--such as RAW sensor inputs or multi-exposure sequences--which severely limits their practicality. In contrast, 3D Gaussian Splatting (3DGS) enables real-time rendering with competitive visual fidelity; however, existing 3DGS-based methods struggle with low-light sRGB inputs, resulting in unstable Gaussian initialization and ineffective noise suppression. To address these challenges, we propose LL-Gaussian, a novel framework for 3D reconstruction and enhancement from low-light sRGB images, enabling pseudo normal-light novel view synthesis. Our method introduces three key innovations: 1) an end-to-end Low-Light Gaussian Initialization Module (LLGIM) that leverages dense priors from learning-based MVS approach to generate high-quality initial point clouds; 2) a dual-branch Gaussian decomposition model that disentangles intrinsic scene properties (reflectance and illumination) from transient interference, enabling stable and interpretable optimization; 3) an unsupervised optimization strategy guided by both physical constrains and diffusion prior to jointly steer decomposition and enhancement. Additionally, we contribute a challenging dataset collected in extreme low-light environments and demonstrate the effectiveness of LL-Gaussian. Compared to state-of-the-art NeRF-based methods, LL-Gaussian achieves up to 2,000 times faster inference and reduces training time to just 2%, while delivering superior reconstruction and rendering quality.
SweepNet: Unsupervised Learning Shape Abstraction via Neural Sweepers
Jul 08, 2024



Shape abstraction is an important task for simplifying complex geometric structures while retaining essential features. Sweep surfaces, commonly found in human-made objects, aid in this process by effectively capturing and representing object geometry, thereby facilitating abstraction. In this paper, we introduce \papername, a novel approach to shape abstraction through sweep surfaces. We propose an effective parameterization for sweep surfaces, utilizing superellipses for profile representation and B-spline curves for the axis. This compact representation, requiring as few as 14 float numbers, facilitates intuitive and interactive editing while preserving shape details effectively. Additionally, by introducing a differentiable neural sweeper and an encoder-decoder architecture, we demonstrate the ability to predict sweep surface representations without supervision. We show the superiority of our model through several quantitative and qualitative experiments throughout the paper. Our code is available at https://mingrui-zhao.github.io/SweepNet/
DPA-Net: Structured 3D Abstraction from Sparse Views via Differentiable Primitive Assembly
Apr 02, 2024



We present a differentiable rendering framework to learn structured 3D abstractions in the form of primitive assemblies from sparse RGB images capturing a 3D object. By leveraging differentiable volume rendering, our method does not require 3D supervision. Architecturally, our network follows the general pipeline of an image-conditioned neural radiance field (NeRF) exemplified by pixelNeRF for color prediction. As our core contribution, we introduce differential primitive assembly (DPA) into NeRF to output a 3D occupancy field in place of density prediction, where the predicted occupancies serve as opacity values for volume rendering. Our network, coined DPA-Net, produces a union of convexes, each as an intersection of convex quadric primitives, to approximate the target 3D object, subject to an abstraction loss and a masking loss, both defined in the image space upon volume rendering. With test-time adaptation and additional sampling and loss designs aimed at improving the accuracy and compactness of the obtained assemblies, our method demonstrates superior performance over state-of-the-art alternatives for 3D primitive abstraction from sparse views.
Coarse-to-Fine Active Segmentation of Interactable Parts in Real Scene Images
Mar 21, 2023



We introduce the first active learning (AL) framework for high-accuracy instance segmentation of dynamic, interactable parts from RGB images of real indoor scenes. As with most human-in-the-loop approaches, the key criterion for success in AL is to minimize human effort while still attaining high performance. To this end, we employ a transformer-based segmentation network that utilizes a masked-attention mechanism. To enhance the network, tailoring to our task, we introduce a coarse-to-fine model which first uses object-aware masked attention and then a pose-aware one, leveraging a correlation between interactable parts and object poses and leading to improved handling of multiple articulated objects in an image. Our coarse-to-fine active segmentation module learns both 2D instance and 3D pose information using the transformer, which supervises the active segmentation and effectively reduces human effort. Our method achieves close to fully accurate (96% and higher) segmentation results on real images, with 77% time saving over manual effort, where the training data consists of only 16.6% annotated real photographs. At last, we contribute a dataset of 2,550 real photographs with annotated interactable parts, demonstrating its superior quality and diversity over the current best alternative.
DualCSG: Learning Dual CSG Trees for General and Compact CAD Modeling
Jan 27, 2023We present DualCSG, a novel neural network composed of two dual and complementary branches for unsupervised learning of constructive solid geometry (CSG) representations of 3D CAD shapes. Our network is trained to reconstruct a given 3D CAD shape through a compact assembly of quadric surface primitives via fixed-order CSG operations along two branches. The key difference between our method and all previous neural CSG models is that DualCSG has a dedicated branch, the residual branch, to assemble the potentially complex, complement or residual shape that is to be subtracted from an overall cover shape. The cover shape is modeled by the other branch, the cover branch. Both branches construct a union of primitive intersections, where the only difference is that the residual branch also learns primitive inverses while operating in the complement space. With the shape complements, our network is provably general. We demonstrate both quantitatively and qualitatively that our network produces CSG reconstructions with superior quality, more natural trees, and better quality-compactness tradeoff than all existing alternatives, especially over complex and high-genus CAD shapes.
HAL3D: Hierarchical Active Learning for Fine-Grained 3D Part Labeling
Jan 25, 2023



We present the first active learning tool for fine-grained 3D part labeling, a problem which challenges even the most advanced deep learning (DL) methods due to the significant structural variations among the small and intricate parts. For the same reason, the necessary data annotation effort is tremendous, motivating approaches to minimize human involvement. Our labeling tool iteratively verifies or modifies part labels predicted by a deep neural network, with human feedback continually improving the network prediction. To effectively reduce human efforts, we develop two novel features in our tool, hierarchical and symmetry-aware active labeling. Our human-in-the-loop approach, coined HAL3D, achieves 100% accuracy (barring human errors) on any test set with pre-defined hierarchical part labels, with 80% time-saving over manual effort.
CAPRI-Net: Learning Compact CAD Shapes with Adaptive Primitive Assembly
Apr 12, 2021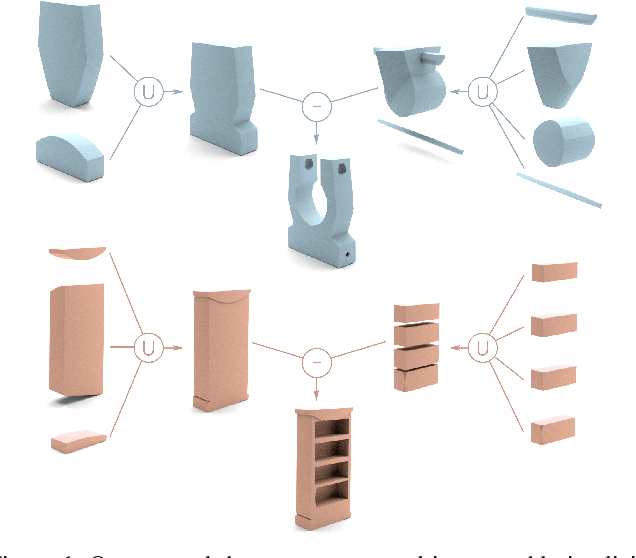
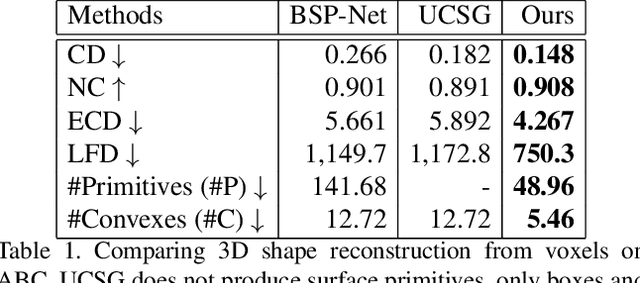

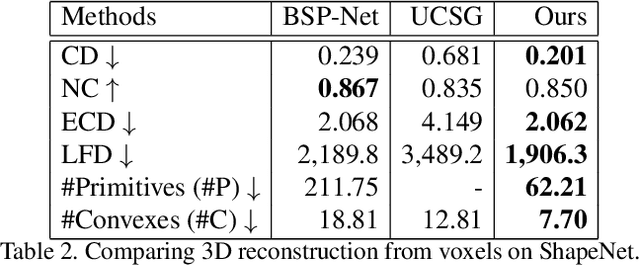
We introduce CAPRI-Net, a neural network for learning compact and interpretable implicit representations of 3D computer-aided design (CAD) models, in the form of adaptive primitive assemblies. Our network takes an input 3D shape that can be provided as a point cloud or voxel grids, and reconstructs it by a compact assembly of quadric surface primitives via constructive solid geometry (CSG) operations. The network is self-supervised with a reconstruction loss, leading to faithful 3D reconstructions with sharp edges and plausible CSG trees, without any ground-truth shape assemblies. While the parametric nature of CAD models does make them more predictable locally, at the shape level, there is a great deal of structural and topological variations, which present a significant generalizability challenge to state-of-the-art neural models for 3D shapes. Our network addresses this challenge by adaptive training with respect to each test shape, with which we fine-tune the network that was pre-trained on a model collection. We evaluate our learning framework on both ShapeNet and ABC, the largest and most diverse CAD dataset to date, in terms of reconstruction quality, shape edges, compactness, and interpretability, to demonstrate superiority over current alternatives suitable for neural CAD reconstruction.