 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLM as Video Narrator: Mitigating Modality Imbalance in Video Moment Retrieval
Jun 25, 2024



Video Moment Retrieval (VMR) aims to localize a specific temporal segment within an untrimmed long video given a natural language query. Existing methods often suffer from inadequate training annotations, i.e., the sentence typically matches with a fraction of the prominent video content in the foreground with limited wording diversity. This intrinsic modality imbalance leaves a considerable portion of visual information remaining unaligned with text. It confines the cross-modal alignment knowledge within the scope of a limited text corpus, thereby leading to sub-optimal visual-textual modeling and poor generalizability. By leveraging the visual-textual understanding capability of multi-modal large language models (MLLM), in this work, we take an MLLM as a video narrator to generate plausible textual descriptions of the video, thereby mitigating the modality imbalance and boosting the temporal localization. To effectively maintain temporal sensibility for localization, we design to get text narratives for each certain video timestamp and construct a structured text paragraph with time information, which is temporally aligned with the visual content. Then we perform cross-modal feature merging between the temporal-aware narratives and corresponding video temporal features to produce semantic-enhanced video representation sequences for query localization. Subsequently, we introduce a uni-modal narrative-query matching mechanism, which encourages the model to extract complementary information from contextual cohesive descriptions for improved retrieval. Extensive experiments on two benchmarks show the effectiveness and generalizability of our proposed method.
Generative Video Diffusion for Unseen Cross-Domain Video Moment Retrieval
Jan 29, 2024Video Moment Retrieval (VMR) requires precise modelling of fine-grained moment-text associations to capture intricate visual-language relationships. Due to the lack of a diverse and generalisable VMR dataset to facilitate learning scalable moment-text associations, existing methods resort to joint training on both source and target domain videos for cross-domain applications. Meanwhile, recent developments in vision-language multimodal models pre-trained on large-scale image-text and/or video-text pairs are only based on coarse associations (weakly labelled). They are inadequate to provide fine-grained moment-text correlations required for cross-domain VMR. In this work, we solve the problem of unseen cross-domain VMR, where certain visual and textual concepts do not overlap across domains, by only utilising target domain sentences (text prompts) without accessing their videos. To that end, we explore generative video diffusion for fine-grained editing of source videos controlled by the target sentences, enabling us to simulate target domain videos. We address two problems in video editing for optimising unseen domain VMR: (1) generation of high-quality simulation videos of different moments with subtle distinctions, (2) selection of simulation videos that complement existing source training videos without introducing harmful noise or unnecessary repetitions. On the first problem, we formulate a two-stage video diffusion generation controlled simultaneously by (1) the original video structure of a source video, (2) subject specifics, and (3) a target sentence prompt. This ensures fine-grained variations between video moments. On the second problem, we introduce a hybrid selection mechanism that combines two quantitative metrics for noise filtering and one qualitative metric for leveraging VMR prediction on simulation video selection.
Efficient Adaptive Human-Object Interaction Detection with Concept-guided Memory
Sep 07, 2023Human Object Interaction (HOI) detection aims to localize and infer the relationships between a human and an object. Arguably, training supervised models for this task from scratch presents challenges due to the performance drop over rare classes and the high computational cost and time required to handle long-tailed distributions of HOIs in complex HOI scenes in realistic settings. This observation motivates us to design an HOI detector that can be trained even with long-tailed labeled data and can leverage existing knowledge from pre-trained models. Inspired by the powerful generalization ability of the large Vision-Language Models (VLM) on classification and retrieval tasks, we propose an efficient Adaptive HOI Detector with Concept-guided Memory (ADA-CM). ADA-CM has two operating modes. The first mode makes it tunable without learning new parameters in a training-free paradigm. Its second mode incorporates an instance-aware adapter mechanism that can further efficiently boost performance if updating a lightweight set of parameters can be afforded. Our proposed method achieves competitive results with state-of-the-art on the HICO-DET and V-COCO datasets with much less training time. Code can be found at https://github.com/ltttpku/ADA-CM.
Zero-Shot Video Moment Retrieval from Frozen Vision-Language Models
Sep 01, 2023Accurate video moment retrieval (VMR) requires universal visual-textual correlations that can handle unknown vocabulary and unseen scenes. However, the learned correlations are likely either biased when derived from a limited amount of moment-text data which is hard to scale up because of the prohibitive annotation cost (fully-supervised), or unreliable when only the video-text pairwise relationships are available without fine-grained temporal annotations (weakly-supervised). Recently, the vision-language models (VLM) demonstrate a new transfer learning paradigm to benefit different vision tasks through the universal visual-textual correlations derived from large-scale vision-language pairwise web data, which has also shown benefits to VMR by fine-tuning in the target domains. In this work, we propose a zero-shot method for adapting generalisable visual-textual priors from arbitrary VLM to facilitate moment-text alignment, without the need for accessing the VMR data. To this end, we devise a conditional feature refinement module to generate boundary-aware visual features conditioned on text queries to enable better moment boundary understanding. Additionally, we design a bottom-up proposal generation strategy that mitigates the impact of domain discrepancies and breaks down complex-query retrieval tasks into individual action retrievals, thereby maximizing the benefits of VLM. Extensive experiments conducted on three VMR benchmark datasets demonstrate the notable performance advantages of our zero-shot algorithm, especially in the novel-word and novel-location out-of-distribution setups.
Towards Generalisable Video Moment Retrieval: Visual-Dynamic Injection to Image-Text Pre-Training
Feb 28, 2023The correlation between the vision and text is essential for video moment retrieval (VMR), however, existing methods heavily rely on separate pre-training feature extractors for visual and textual understanding. Without sufficient temporal boundary annotations, it is non-trivial to learn universal video-text alignments. In this work, we explore multi-modal correlations derived from large-scale image-text data to facilitate generalisable VMR. To address the limitations of image-text pre-training models on capturing the video changes, we propose a generic method, referred to as Visual-Dynamic Injection (VDI), to empower the model's understanding of video moments. Whilst existing VMR methods are focusing on building temporal-aware video features, being aware of the text descriptions about the temporal changes is also critical but originally overlooked in pre-training by matching static images with sentences. Therefore, we extract visual context and spatial dynamic information from video frames and explicitly enforce their alignments with the phrases describing video changes (e.g. verb). By doing so, the potentially relevant visual and motion patterns in videos are encoded in the corresponding text embeddings (injected) so to enable more accurate video-text alignments. We conduct extensive experiments on two VMR benchmark datasets (Charades-STA and ActivityNet-Captions) and achieve state-of-the-art performances. Especially, VDI yields notable advantages when being tested on the out-of-distribution splits where the testing samples involve novel scenes and vocabulary.
LiveSeg: Unsupervised Multimodal Temporal Segmentation of Long Livestream Videos
Oct 12, 2022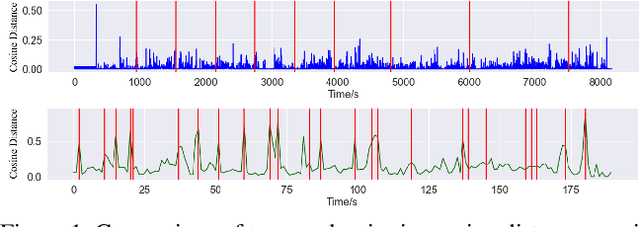
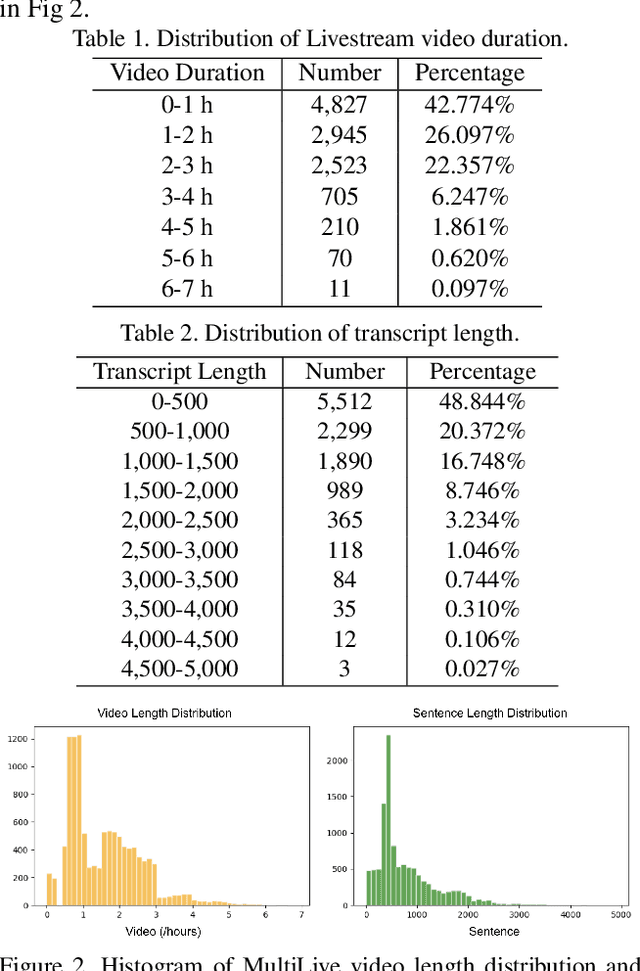
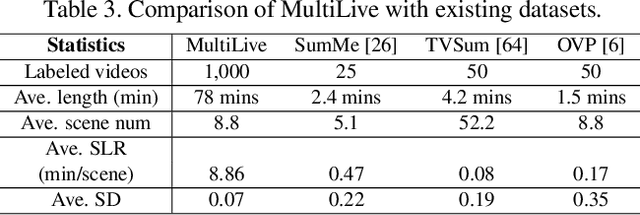
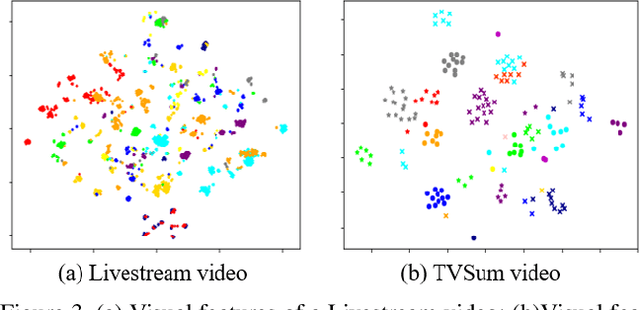
Livestream videos have become a significant part of online learning, where design, digital marketing, creative painting, and other skills are taught by experienced experts in the sessions, making them valuable materials. However, Livestream tutorial videos are usually hours long, recorded, and uploaded to the Internet directly after the live sessions, making it hard for other people to catch up quickly. An outline will be a beneficial solution, which requires the video to be temporally segmented according to topics. In this work, we introduced a large Livestream video dataset named MultiLive, and formulated the temporal segmentation of the long Livestream videos (TSLLV) task. We propose LiveSeg, an unsupervised Livestream video temporal Segmentation solution, which takes advantage of multimodal features from different domains. Our method achieved a $16.8\%$ F1-score performance improvement compared with the state-of-the-art method.
Semantics-Consistent Cross-domain Summarization via Optimal Transport Alignment
Oct 10, 2022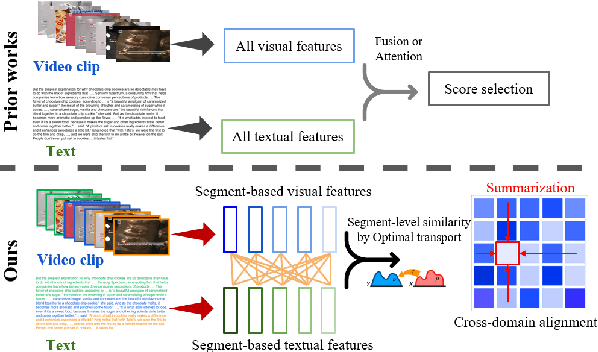
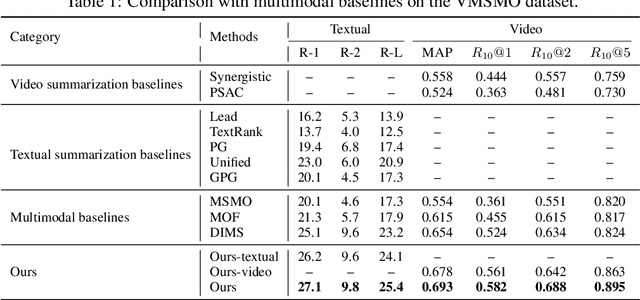
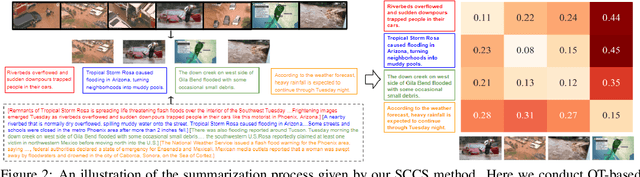
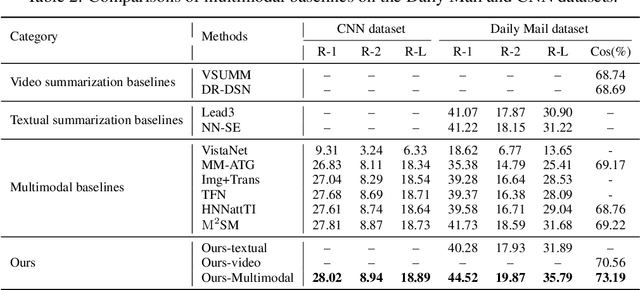
Multimedia summarization with multimodal output (MSMO) is a recently explored application in language grounding. It plays an essential role in real-world applications, i.e., automatically generating cover images and titles for news articles or providing introductions to online videos. However, existing methods extract features from the whole video and article and use fusion methods to select the representative one, thus usually ignoring the critical structure and varying semantics. In this work, we propose a Semantics-Consistent Cross-domain Summarization (SCCS) model based on optimal transport alignment with visual and textual segmentation. In specific, our method first decomposes both video and article into segments in order to capture the structural semantics, respectively. Then SCCS follows a cross-domain alignment objective with optimal transport distance, which leverages multimodal interaction to match and select the visual and textual summary. We evaluated our method on three recent multimodal datasets and demonstrated the effectiveness of our method in producing high-quality multimodal summaries.
Video Activity Localisation with Uncertainties in Temporal Boundary
Jun 26, 2022

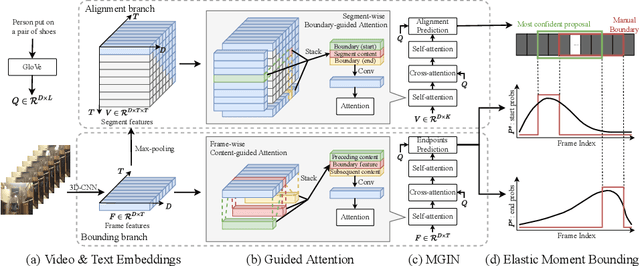
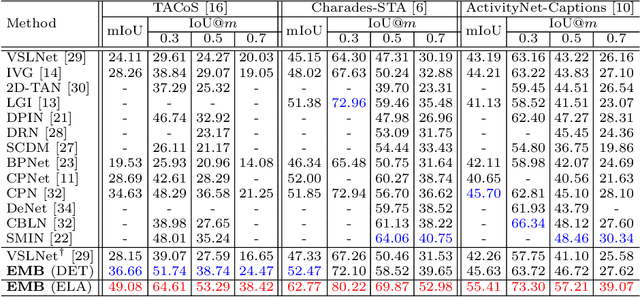
Current methods for video activity localisation over time assume implicitly that activity temporal boundaries labelled for model training are determined and precise. However, in unscripted natural videos, different activities mostly transit smoothly, so that it is intrinsically ambiguous to determine in labelling precisely when an activity starts and ends over time. Such uncertainties in temporal labelling are currently ignored in model training, resulting in learning mis-matched video-text correlation with poor generalisation in test. In this work, we solve this problem by introducing Elastic Moment Bounding (EMB) to accommodate flexible and adaptive activity temporal boundaries towards modelling universally interpretable video-text correlation with tolerance to underlying temporal uncertainties in pre-fixed annotations. Specifically, we construct elastic boundaries adaptively by mining and discovering frame-wise temporal endpoints that can maximise the alignment between video segments and query sentences. To enable both more robust matching (segment content attention) and more accurate localisation (segment elastic boundaries), we optimise the selection of frame-wise endpoints subject to segment-wise contents by a novel Guided Attention mechanism. Extensive experiments on three video activity localisation benchmarks demonstrate compellingly the EMB's advantages over existing methods without modelling uncertainty.
MHMS: Multimodal Hierarchical Multimedia Summarization
Apr 07, 2022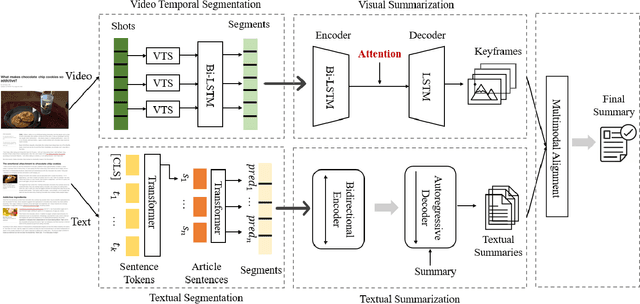
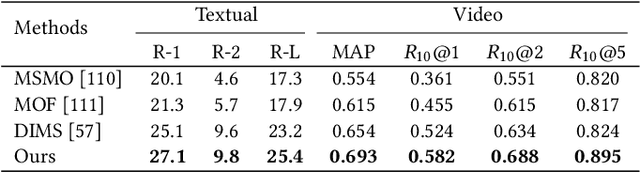

Multimedia summarization with multimodal output can play an essential role in real-world applications, i.e., automatically generating cover images and titles for news articles or providing introductions to online videos. In this work, we propose a multimodal hierarchical multimedia summarization (MHMS) framework by interacting visual and language domains to generate both video and textual summaries. Our MHMS method contains video and textual segmentation and summarization module, respectively. It formulates a cross-domain alignment objective with optimal transport distance which leverages cross-domain interaction to generate the representative keyframe and textual summary. We evaluated MHMS on three recent multimodal datasets and demonstrated the effectiveness of our method in producing high-quality multimodal summaries.
StyleBabel: Artistic Style Tagging and Captioning
Mar 11, 2022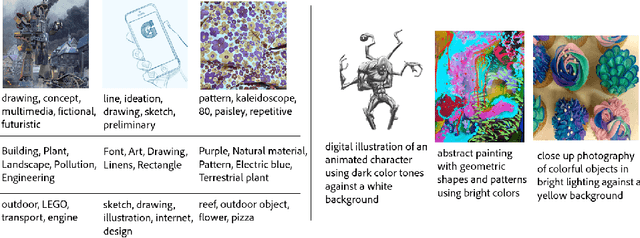
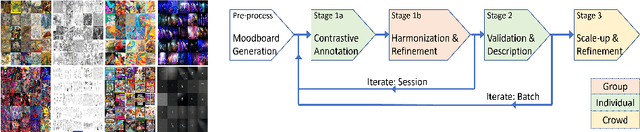

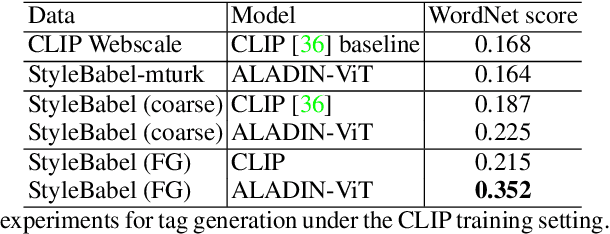
We present StyleBabel, a unique open access dataset of natural language captions and free-form tags describing the artistic style of over 135K digital artworks, collected via a novel participatory method from experts studying at specialist art and design schools. StyleBabel was collected via an iterative method, inspired by `Grounded Theory': a qualitative approach that enables annotation while co-evolving a shared language for fine-grained artistic style attribute description. We demonstrate several downstream tasks for StyleBabel, adapting the recent ALADIN architecture for fine-grained style similarity, to train cross-modal embeddings for: 1) free-form tag generation; 2) natural language description of artistic style; 3) fine-grained text search of style. To do so, we extend ALADIN with recent advances in Visual Transformer (ViT) and cross-modal representation learning, achieving a state of the art accuracy in fine-grained style retrieval.