 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuMesh++: Towards Versatile and Efficient Volumetric Editing with Disentangled Neural Mesh-based Implicit Field
Jun 17, 2026Recently neural implicit rendering techniques have evolved rapidly and demonstrated significant advantages in novel view synthesis and 3D scene reconstruction. However, existing neural rendering methods for editing purposes offer limited functionalities, e.g., rigid transformation and category-specific editing. In this paper, we present a novel mesh-based representation by encoding the neural radiance field with disentangled geometry, texture, and semantic codes on mesh vertices, which empowers a set of efficient and comprehensive editing functionalities, including mesh-guided geometry editing, designated texture editing with texture swapping, filling and painting operations, and semantic-guided editing. To this end, we develop several techniques including a novel local space parameterization to enhance rendering quality and training stability, a learnable modification color on vertex to improve the fidelity of texture editing, a spatial-aware optimization strategy to realize precise texture editing, and a semantic-aided region selection to ease the laborious annotation of implicit field editing. Extensive experiments and editing examples on both real and synthetic datasets demonstrate the superiority of our method on representation quality and editing ability. Project page: https://zju3dv.github.io/neumeshplusplus/
Archon: A Unified Multimodal Model for Holistic Digital Human Generation
May 28, 2026Digital humans are fundamental to immersive interaction, yet creating a unified model for holistic modalities, including text, audio, motion, and visual content, remains an open challenge. In this paper, we present Archon, a fully pretrained, human-centric unified multimodal model for holistic avatar generation. Archon unifies seven modalities with modality-specific tokenizers, and a native autoregressive unified multimodal model pretrained on synchronized modalities and 72 diverse tasks to model holistic joint distributions. To address the token explosion challenge in high-fidelity talking videos, we introduce a memory-efficient semantic video reparameterization, achieving 4x token reduction while preserving fine-grained dynamics, coupled with a semantic-driven video diffusion decoder. We further propose a "Thinking in Modality" that decomposes ambiguous cross-modal tasks into stepwise thinking in an alternative chain of modality, progressively enhancing fidelity and controllability. Extensive experiments demonstrate that Archon achieves superior or comparable performance across diverse digital human generation tasks, validating the effectiveness of our unified framework. Project page: https://zju3dv.github.io/archon/.
EgoRelight: Egocentric Human Capture and Illumination Recovery for Relightable and Photoreal Avatar Rendering
May 27, 2026Mixed Reality (MR) headsets promise a future of immersive telepresence where virtual humans blend indistinguishably into real or virtual surroundings. Achieving this vision requires a method for capturing a user's motion, estimating appearance under novel lighting, and understanding the environment - all from the constrained viewpoint of a head-mounted display (HMD). Existing approaches treat these as isolated problems: they either focus on driving avatars with baked-in lighting or rely on studio setups for relighting. In this paper, we present EgoRelight, a holistic framework for egocentric telepresence that simultaneously captures full-body human performance, synthesizes photorealistic and relightable appearance, and estimates high dynamic range (HDR) environment maps from a single HMD. First, to ensure motion and surface reconstruction, we propose an egocentric perception module that leverages stereo down-facing cameras to extract dense depth maps, which serve as geometric control signals to drive a mesh-based avatar. Second, we introduce a novel neural appearance model that learns to synthesize view-dependent specular and view-independent diffuse shading separately. By employing a specialized ray-sampling strategy, our model generalizes to unseen illumination without relying on restrictive analytical BRDF priors. Third, we enable seamless avatar integration into the physical world via a test-time inverse rendering process, which recovers an HDR environment map by matching the pre-trained avatar's appearance to live egocentric camera observations. We demonstrate our system through a social telepresence application, where remote users are coherently relit according to their physical environment. Extensive experiments show that our components and the integrated system significantly outperform state-of-the-art baselines in geometric accuracy and rendering as well as relighting fidelity.
Talking Together: Synthesizing Co-Located 3D Conversations from Audio
Mar 09, 2026We tackle the challenging task of generating complete 3D facial animations for two interacting, co-located participants from a mixed audio stream. While existing methods often produce disembodied "talking heads" akin to a video conference call, our work is the first to explicitly model the dynamic 3D spatial relationship -- including relative position, orientation, and mutual gaze -- that is crucial for realistic in-person dialogues. Our system synthesizes the full performance of both individuals, including precise lip-sync, and uniquely allows their relative head poses to be controlled via textual descriptions. To achieve this, we propose a dual-stream architecture where each stream is responsible for one participant's output. We employ speaker's role embeddings and inter-speaker cross-attention mechanisms designed to disentangle the mixed audio and model the interaction. Furthermore, we introduce a novel eye gaze loss to promote natural, mutual eye contact. To power our data-hungry approach, we introduce a novel pipeline to curate a large-scale conversational dataset consisting of over 2 million dyadic pairs from in-the-wild videos. Our method generates fluid, controllable, and spatially aware dyadic animations suitable for immersive applications in VR and telepresence, significantly outperforming existing baselines in perceived realism and interaction coherence.
LegacyAvatars: Volumetric Face Avatars For Traditional Graphics Pipelines
Jan 18, 2026We introduce a novel representation for efficient classical rendering of photorealistic 3D face avatars. Leveraging recent advances in radiance fields anchored to parametric face models, our approach achieves controllable volumetric rendering of complex facial features, including hair, skin, and eyes. At enrollment time, we learn a set of radiance manifolds in 3D space to extract an explicit layered mesh, along with appearance and warp textures. During deployment, this allows us to control and animate the face through simple linear blending and alpha compositing of textures over a static mesh. This explicit representation also enables the generated avatar to be efficiently streamed online and then rendered using classical mesh and shader-based rendering on legacy graphics platforms, eliminating the need for any custom engineering or integration.
S^2VG: 3D Stereoscopic and Spatial Video Generation via Denoising Frame Matrix
Aug 11, 2025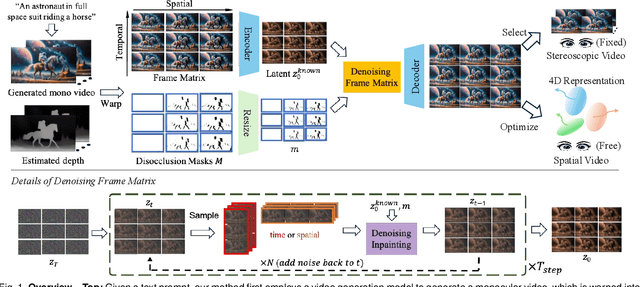

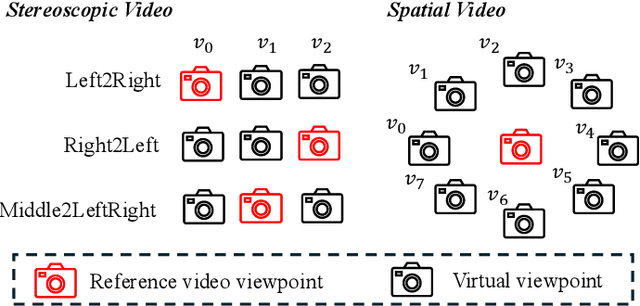

While video generation models excel at producing high-quality monocular videos, generating 3D stereoscopic and spatial videos for immersive applications remains an underexplored challenge. We present a pose-free and training-free method that leverages an off-the-shelf monocular video generation model to produce immersive 3D videos. Our approach first warps the generated monocular video into pre-defined camera viewpoints using estimated depth information, then applies a novel \textit{frame matrix} inpainting framework. This framework utilizes the original video generation model to synthesize missing content across different viewpoints and timestamps, ensuring spatial and temporal consistency without requiring additional model fine-tuning. Moreover, we develop a \dualupdate~scheme that further improves the quality of video inpainting by alleviating the negative effects propagated from disoccluded areas in the latent space. The resulting multi-view videos are then adapted into stereoscopic pairs or optimized into 4D Gaussians for spatial video synthesis. We validate the efficacy of our proposed method by conducting experiments on videos from various generative models, such as Sora, Lumiere, WALT, and Zeroscope. The experiments demonstrate that our method has a significant improvement over previous methods. Project page at: https://daipengwa.github.io/S-2VG_ProjectPage/
IM-Portrait: Learning 3D-aware Video Diffusion for Photorealistic Talking Heads from Monocular Videos
Apr 29, 2025We propose a novel 3D-aware diffusion-based method for generating photorealistic talking head videos directly from a single identity image and explicit control signals (e.g., expressions). Our method generates Multiplane Images (MPIs) that ensure geometric consistency, making them ideal for immersive viewing experiences like binocular videos for VR headsets. Unlike existing methods that often require a separate stage or joint optimization to reconstruct a 3D representation (such as NeRF or 3D Gaussians), our approach directly generates the final output through a single denoising process, eliminating the need for post-processing steps to render novel views efficiently. To effectively learn from monocular videos, we introduce a training mechanism that reconstructs the output MPI randomly in either the target or the reference camera space. This approach enables the model to simultaneously learn sharp image details and underlying 3D information. Extensive experiments demonstrate the effectiveness of our method, which achieves competitive avatar quality and novel-view rendering capabilities, even without explicit 3D reconstruction or high-quality multi-view training data.
HOGSA: Bimanual Hand-Object Interaction Understanding with 3D Gaussian Splatting Based Data Augmentation
Jan 06, 2025



Understanding of bimanual hand-object interaction plays an important role in robotics and virtual reality. However, due to significant occlusions between hands and object as well as the high degree-of-freedom motions, it is challenging to collect and annotate a high-quality, large-scale dataset, which prevents further improvement of bimanual hand-object interaction-related baselines. In this work, we propose a new 3D Gaussian Splatting based data augmentation framework for bimanual hand-object interaction, which is capable of augmenting existing dataset to large-scale photorealistic data with various hand-object pose and viewpoints. First, we use mesh-based 3DGS to model objects and hands, and to deal with the rendering blur problem due to multi-resolution input images used, we design a super-resolution module. Second, we extend the single hand grasping pose optimization module for the bimanual hand object to generate various poses of bimanual hand-object interaction, which can significantly expand the pose distribution of the dataset. Third, we conduct an analysis for the impact of different aspects of the proposed data augmentation on the understanding of the bimanual hand-object interaction. We perform our data augmentation on two benchmarks, H2O and Arctic, and verify that our method can improve the performance of the baselines.
Diffgrasp: Whole-Body Grasping Synthesis Guided by Object Motion Using a Diffusion Model
Dec 30, 2024



Generating high-quality whole-body human object interaction motion sequences is becoming increasingly important in various fields such as animation, VR/AR, and robotics. The main challenge of this task lies in determining the level of involvement of each hand given the complex shapes of objects in different sizes and their different motion trajectories, while ensuring strong grasping realism and guaranteeing the coordination of movement in all body parts. Contrasting with existing work, which either generates human interaction motion sequences without detailed hand grasping poses or only models a static grasping pose, we propose a simple yet effective framework that jointly models the relationship between the body, hands, and the given object motion sequences within a single diffusion model. To guide our network in perceiving the object's spatial position and learning more natural grasping poses, we introduce novel contact-aware losses and incorporate a data-driven, carefully designed guidance. Experimental results demonstrate that our approach outperforms the state-of-the-art method and generates plausible whole-body motion sequences.
EVER: Exact Volumetric Ellipsoid Rendering for Real-time View Synthesis
Oct 02, 2024



We present Exact Volumetric Ellipsoid Rendering (EVER), a method for real-time differentiable emission-only volume rendering. Unlike recent rasterization based approach by 3D Gaussian Splatting (3DGS), our primitive based representation allows for exact volume rendering, rather than alpha compositing 3D Gaussian billboards. As such, unlike 3DGS our formulation does not suffer from popping artifacts and view dependent density, but still achieves frame rates of $\sim\!30$ FPS at 720p on an NVIDIA RTX4090. Since our approach is built upon ray tracing it enables effects such as defocus blur and camera distortion (e.g. such as from fisheye cameras), which are difficult to achieve by rasterization. We show that our method is more accurate with fewer blending issues than 3DGS and follow-up work on view-consistent rendering, especially on the challenging large-scale scenes from the Zip-NeRF dataset where it achieves sharpest results among real-time techniques.