 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Evolving Framework for Efficient Terminal Agents via Observational Context Compression
Apr 21, 2026As model capabilities advance, research has increasingly shifted toward long-horizon, multi-turn terminal-centric agentic tasks, where raw environment feedback is often preserved in the interaction history to support future decisions. However, repeatedly retaining such feedback introduces substantial redundancy and causes cumulative token cost to grow quadratically with the number of steps, hindering long-horizon reasoning. Although observation compression can mitigate this issue, the heterogeneity of terminal environments makes heuristic-based or fixed-prompt methods difficult to generalize. We propose TACO, a plug-and-play, self-evolving Terminal Agent Compression framework that automatically discovers and refines compression rules from interaction trajectories for existing terminal agents. Experiments on TerminalBench (TB 1.0 and TB 2.0) and four additional terminal-related benchmarks (i.e., SWE-Bench Lite, CompileBench, DevEval, and CRUST-Bench) show that TACO consistently improves performance across mainstream agent frameworks and strong backbone models. With MiniMax-2.5, it improves performance on most benchmarks while reducing token overhead by around 10%. On TerminalBench, it brings consistent gains of 1%-4% across strong agentic models, and further improves accuracy by around 2%-3% under the same token budget. These results demonstrate the effectiveness and generalization of self-evolving, task-aware compression for terminal agents.
Audio-Omni: Extending Multi-modal Understanding to Versatile Audio Generation and Editing
Apr 12, 2026Recent progress in multimodal models has spurred rapid advances in audio understanding, generation, and editing. However, these capabilities are typically addressed by specialized models, leaving the development of a truly unified framework that can seamlessly integrate all three tasks underexplored. While some pioneering works have explored unifying audio understanding and generation, they often remain confined to specific domains. To address this, we introduce Audio-Omni, the first end-to-end framework to unify generation and editing across general sound, music, and speech domains, with integrated multi-modal understanding capabilities. Our architecture synergizes a frozen Multimodal Large Language Model for high-level reasoning with a trainable Diffusion Transformer for high-fidelity synthesis. To overcome the critical data scarcity in audio editing, we construct AudioEdit, a new large-scale dataset comprising over one million meticulously curated editing pairs. Extensive experiments demonstrate that Audio-Omni achieves state-of-the-art performance across a suite of benchmarks, outperforming prior unified approaches while achieving performance on par with or superior to specialized expert models. Beyond its core capabilities, Audio-Omni exhibits remarkable inherited capabilities, including knowledge-augmented reasoning generation, in-context generation, and zero-shot cross-lingual control for audio generation, highlighting a promising direction toward universal generative audio intelligence. The code, model, and dataset will be publicly released on https://zeyuet.github.io/Audio-Omni.
CMI-RewardBench: Evaluating Music Reward Models with Compositional Multimodal Instruction
Mar 04, 2026While music generation models have evolved to handle complex multimodal inputs mixing text, lyrics, and reference audio, evaluation mechanisms have lagged behind. In this paper, we bridge this critical gap by establishing a comprehensive ecosystem for music reward modeling under Compositional Multimodal Instruction (CMI), where the generated music may be conditioned on text descriptions, lyrics, and audio prompts. We first introduce CMI-Pref-Pseudo, a large-scale preference dataset comprising 110k pseudo-labeled samples, and CMI-Pref, a high-quality, human-annotated corpus tailored for fine-grained alignment tasks. To unify the evaluation landscape, we propose CMI-RewardBench, a unified benchmark that evaluates music reward models on heterogeneous samples across musicality, text-music alignment, and compositional instruction alignment. Leveraging these resources, we develop CMI reward models (CMI-RMs), a parameter-efficient reward model family capable of processing heterogeneous inputs. We evaluate their correlation with human judgments scores on musicality and alignment on CMI-Pref along with previous datasets. Further experiments demonstrate that CMI-RM not only correlates strongly with human judgments, but also enables effective inference-time scaling via top-k filtering. The necessary training data, benchmarks, and reward models are publicly available.
Voices of Civilizations: A Multilingual QA Benchmark for Global Music Understanding
Feb 28, 2026We introduce Voices of Civilizations, the first multilingual QA benchmark for evaluating audio LLMs' cultural comprehension on full-length music recordings. Covering 380 tracks across 38 languages, our automated pipeline yields 1,190 multiple-choice questions through four stages - each followed by manual verification: 1) compiling a representative music list; 2) generating cultural-background documents for each sample in the music list via LLMs; 3) extracting key attributes from those documents; and 4) constructing multiple-choice questions probing language, region associations, mood, and thematic content. We evaluate models under four conditions and report per-language accuracy. Our findings demonstrate that even state-of-the-art audio LLMs struggle to capture subtle cultural nuances without rich textual context and exhibit systematic biases in interpreting music from different cultural traditions. The dataset is publicly available on Hugging Face to foster culturally inclusive music understanding research.
SLAM-LLM: A Modular, Open-Source Multimodal Large Language Model Framework and Best Practice for Speech, Language, Audio and Music Processing
Jan 14, 2026The recent surge in open-source Multimodal Large Language Models (MLLM) frameworks, such as LLaVA, provides a convenient kickoff for artificial intelligence developers and researchers. However, most of the MLLM frameworks take vision as the main input modality, and provide limited in-depth support for the modality of speech, audio, and music. This situation hinders the development of audio-language models, and forces researchers to spend a lot of effort on code writing and hyperparameter tuning. We present SLAM-LLM, an open-source deep learning framework designed to train customized MLLMs, focused on speech, language, audio, and music processing. SLAM-LLM provides a modular configuration of different encoders, projectors, LLMs, and parameter-efficient fine-tuning plugins. SLAM-LLM also includes detailed training and inference recipes for mainstream tasks, along with high-performance checkpoints like LLM-based Automatic Speech Recognition (ASR), Automated Audio Captioning (AAC), and Music Captioning (MC). Some of these recipes have already reached or are nearing state-of-the-art performance, and some relevant techniques have also been accepted by academic papers. We hope SLAM-LLM will accelerate iteration, development, data engineering, and model training for researchers. We are committed to continually pushing forward audio-based MLLMs through this open-source framework, and call on the community to contribute to the LLM-based speech, audio and music processing.
AutoMV: An Automatic Multi-Agent System for Music Video Generation
Dec 13, 2025Music-to-Video (M2V) generation for full-length songs faces significant challenges. Existing methods produce short, disjointed clips, failing to align visuals with musical structure, beats, or lyrics, and lack temporal consistency. We propose AutoMV, a multi-agent system that generates full music videos (MVs) directly from a song. AutoMV first applies music processing tools to extract musical attributes, such as structure, vocal tracks, and time-aligned lyrics, and constructs these features as contextual inputs for following agents. The screenwriter Agent and director Agent then use this information to design short script, define character profiles in a shared external bank, and specify camera instructions. Subsequently, these agents call the image generator for keyframes and different video generators for "story" or "singer" scenes. A Verifier Agent evaluates their output, enabling multi-agent collaboration to produce a coherent longform MV. To evaluate M2V generation, we further propose a benchmark with four high-level categories (Music Content, Technical, Post-production, Art) and twelve ine-grained criteria. This benchmark was applied to compare commercial products, AutoMV, and human-directed MVs with expert human raters: AutoMV outperforms current baselines significantly across all four categories, narrowing the gap to professional MVs. Finally, we investigate using large multimodal models as automatic MV judges; while promising, they still lag behind human expert, highlighting room for future work.
Hollywood Town: Long-Video Generation via Cross-Modal Multi-Agent Orchestration
Oct 25, 2025



Recent advancements in multi-agent systems have demonstrated significant potential for enhancing creative task performance, such as long video generation. This study introduces three innovations to improve multi-agent collaboration. First, we propose OmniAgent, a hierarchical, graph-based multi-agent framework for long video generation that leverages a film-production-inspired architecture to enable modular specialization and scalable inter-agent collaboration. Second, inspired by context engineering, we propose hypergraph nodes that enable temporary group discussions among agents lacking sufficient context, reducing individual memory requirements while ensuring adequate contextual information. Third, we transition from directed acyclic graphs (DAGs) to directed cyclic graphs with limited retries, allowing agents to reflect and refine outputs iteratively, thereby improving earlier stages through feedback from subsequent nodes. These contributions lay the groundwork for developing more robust multi-agent systems in creative tasks.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025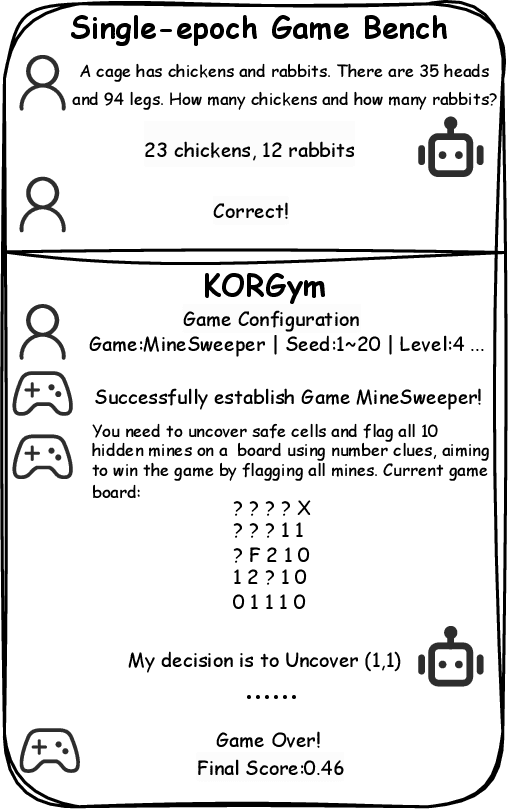
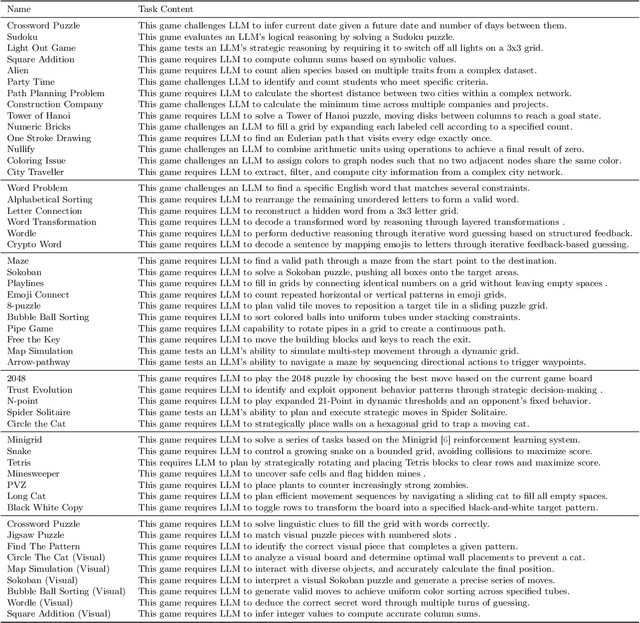
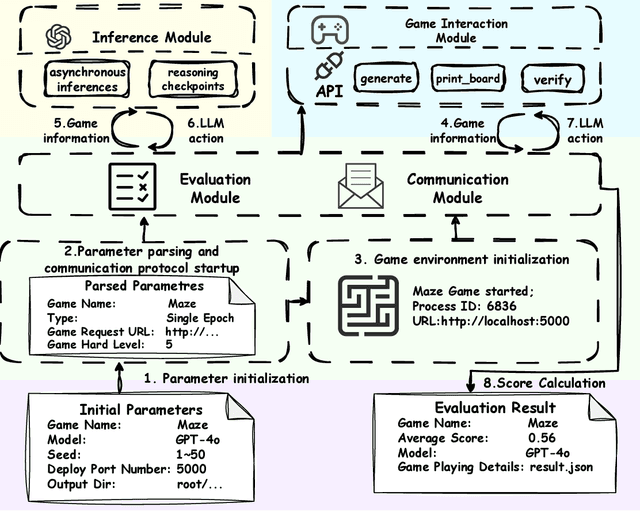

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025



We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.
SongEval: A Benchmark Dataset for Song Aesthetics Evaluation
May 16, 2025Aesthetics serve as an implicit and important criterion in song generation tasks that reflect human perception beyond objective metrics. However, evaluating the aesthetics of generated songs remains a fundamental challenge, as the appreciation of music is highly subjective. Existing evaluation metrics, such as embedding-based distances, are limited in reflecting the subjective and perceptual aspects that define musical appeal. To address this issue, we introduce SongEval, the first open-source, large-scale benchmark dataset for evaluating the aesthetics of full-length songs. SongEval includes over 2,399 songs in full length, summing up to more than 140 hours, with aesthetic ratings from 16 professional annotators with musical backgrounds. Each song is evaluated across five key dimensions: overall coherence, memorability, naturalness of vocal breathing and phrasing, clarity of song structure, and overall musicality. The dataset covers both English and Chinese songs, spanning nine mainstream genres. Moreover, to assess the effectiveness of song aesthetic evaluation, we conduct experiments using SongEval to predict aesthetic scores and demonstrate better performance than existing objective evaluation metrics in predicting human-perceived musical quality.