 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-FLAN: A Preliminary Release
Feb 23, 2025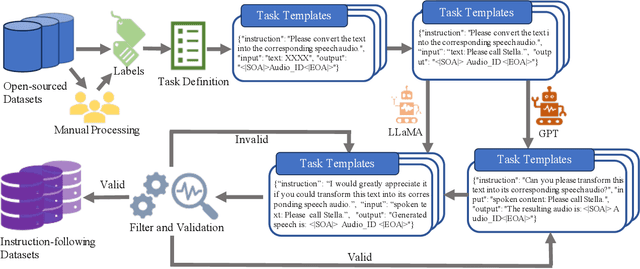

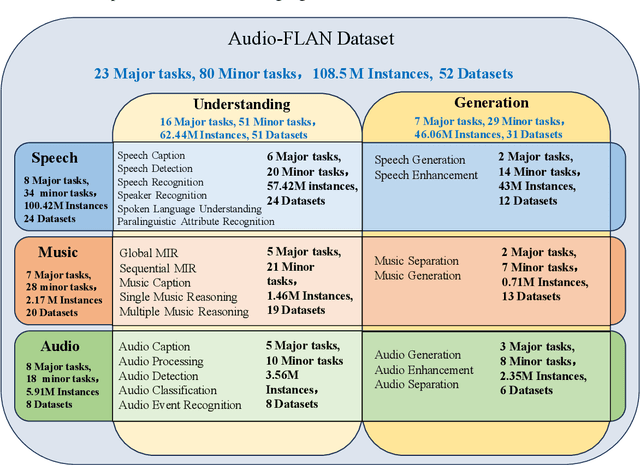

Recent advancements in audio tokenization have significantly enhanced the integration of audio capabilities into large language models (LLMs). However, audio understanding and generation are often treated as distinct tasks, hindering the development of truly unified audio-language models. While instruction tuning has demonstrated remarkable success in improving generalization and zero-shot learning across text and vision, its application to audio remains largely unexplored. A major obstacle is the lack of comprehensive datasets that unify audio understanding and generation. To address this, we introduce Audio-FLAN, a large-scale instruction-tuning dataset covering 80 diverse tasks across speech, music, and sound domains, with over 100 million instances. Audio-FLAN lays the foundation for unified audio-language models that can seamlessly handle both understanding (e.g., transcription, comprehension) and generation (e.g., speech, music, sound) tasks across a wide range of audio domains in a zero-shot manner. The Audio-FLAN dataset is available on HuggingFace and GitHub and will be continuously updated.
Speaking from Coarse to Fine: Improving Neural Codec Language Model via Multi-Scale Speech Coding and Generation
Sep 18, 2024



The neural codec language model (CLM) has demonstrated remarkable performance in text-to-speech (TTS) synthesis. However, troubled by ``recency bias", CLM lacks sufficient attention to coarse-grained information at a higher temporal scale, often producing unnatural or even unintelligible speech. This work proposes CoFi-Speech, a coarse-to-fine CLM-TTS approach, employing multi-scale speech coding and generation to address this issue. We train a multi-scale neural codec, CoFi-Codec, to encode speech into a multi-scale discrete representation, comprising multiple token sequences with different time resolutions. Then, we propose CoFi-LM that can generate this representation in two modes: the single-LM-based chain-of-scale generation and the multiple-LM-based stack-of-scale generation. In experiments, CoFi-Speech significantly outperforms single-scale baseline systems on naturalness and speaker similarity in zero-shot TTS. The analysis of multi-scale coding demonstrates the effectiveness of CoFi-Codec in learning multi-scale discrete speech representations while keeping high-quality speech reconstruction. The coarse-to-fine multi-scale generation, especially for the stack-of-scale approach, is also validated as a crucial approach in pursuing a high-quality neural codec language model for TTS.
SoCodec: A Semantic-Ordered Multi-Stream Speech Codec for Efficient Language Model Based Text-to-Speech Synthesis
Sep 02, 2024



The long speech sequence has been troubling language models (LM) based TTS approaches in terms of modeling complexity and efficiency. This work proposes SoCodec, a semantic-ordered multi-stream speech codec, to address this issue. It compresses speech into a shorter, multi-stream discrete semantic sequence with multiple tokens at each frame. Meanwhile, the ordered product quantization is proposed to constrain this sequence into an ordered representation. It can be applied with a multi-stream delayed LM to achieve better autoregressive generation along both time and stream axes in TTS. The experimental result strongly demonstrates the effectiveness of the proposed approach, achieving superior performance over baseline systems even if compressing the frameshift of speech from 20ms to 240ms (12x). The ablation studies further validate the importance of learning the proposed ordered multi-stream semantic representation in pursuing shorter speech sequences for efficient LM-based TTS.
UniAudio 1.5: Large Language Model-driven Audio Codec is A Few-shot Audio Task Learner
Jun 14, 2024



The Large Language models (LLMs) have demonstrated supreme capabilities in text understanding and generation, but cannot be directly applied to cross-modal tasks without fine-tuning. This paper proposes a cross-modal in-context learning approach, empowering the frozen LLMs to achieve multiple audio tasks in a few-shot style without any parameter update. Specifically, we propose a novel and LLMs-driven audio codec model, LLM-Codec, to transfer the audio modality into the textual space, \textit{i.e.} representing audio tokens with words or sub-words in the vocabulary of LLMs, while keeping high audio reconstruction quality. The key idea is to reduce the modality heterogeneity between text and audio by compressing the audio modality into a well-trained LLMs token space. Thus, the audio representation can be viewed as a new \textit{foreign language}, and LLMs can learn the new \textit{foreign language} with several demonstrations. In experiments, we investigate the performance of the proposed approach across multiple audio understanding and generation tasks, \textit{e.g.} speech emotion classification, audio classification, text-to-speech generation, speech enhancement, etc. The experimental results demonstrate that the LLMs equipped with the proposed LLM-Codec, named as UniAudio 1.5, prompted by only a few examples, can achieve the expected functions in simple scenarios. It validates the feasibility and effectiveness of the proposed cross-modal in-context learning approach. To facilitate research on few-shot audio task learning and multi-modal LLMs, we have open-sourced the LLM-Codec model.
Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation
Jun 11, 2024



The multi-codebook speech codec enables the application of large language models (LLM) in TTS but bottlenecks efficiency and robustness due to multi-sequence prediction. To avoid this obstacle, we propose Single-Codec, a single-codebook single-sequence codec, which employs a disentangled VQ-VAE to decouple speech into a time-invariant embedding and a phonetically-rich discrete sequence. Furthermore, the encoder is enhanced with 1) contextual modeling with a BLSTM module to exploit the temporal information, 2) a hybrid sampling module to alleviate distortion from upsampling and downsampling, and 3) a resampling module to encourage discrete units to carry more phonetic information. Compared with multi-codebook codecs, e.g., EnCodec and TiCodec, Single-Codec demonstrates higher reconstruction quality with a lower bandwidth of only 304bps. The effectiveness of Single-Code is further validated by LLM-TTS experiments, showing improved naturalness and intelligibility.
Addressing Index Collapse of Large-Codebook Speech Tokenizer with Dual-Decoding Product-Quantized Variational Auto-Encoder
Jun 05, 2024



VQ-VAE, as a mainstream approach of speech tokenizer, has been troubled by ``index collapse'', where only a small number of codewords are activated in large codebooks. This work proposes product-quantized (PQ) VAE with more codebooks but fewer codewords to address this problem and build large-codebook speech tokenizers. It encodes speech features into multiple VQ subspaces and composes them into codewords in a larger codebook. Besides, to utilize each VQ subspace well, we also enhance PQ-VAE via a dual-decoding training strategy with the encoding and quantized sequences. The experimental results demonstrate that PQ-VAE addresses ``index collapse" effectively, especially for larger codebooks. The model with the proposed training strategy further improves codebook perplexity and reconstruction quality, outperforming other multi-codebook VQ approaches. Finally, PQ-VAE demonstrates its effectiveness in language-model-based TTS, supporting higher-quality speech generation with larger codebooks.
SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models
Jun 04, 2024



In this study, we propose a simple and efficient Non-Autoregressive (NAR) text-to-speech (TTS) system based on diffusion, named SimpleSpeech. Its simpleness shows in three aspects: (1) It can be trained on the speech-only dataset, without any alignment information; (2) It directly takes plain text as input and generates speech through an NAR way; (3) It tries to model speech in a finite and compact latent space, which alleviates the modeling difficulty of diffusion. More specifically, we propose a novel speech codec model (SQ-Codec) with scalar quantization, SQ-Codec effectively maps the complex speech signal into a finite and compact latent space, named scalar latent space. Benefits from SQ-Codec, we apply a novel transformer diffusion model in the scalar latent space of SQ-Codec. We train SimpleSpeech on 4k hours of a speech-only dataset, it shows natural prosody and voice cloning ability. Compared with previous large-scale TTS models, it presents significant speech quality and generation speed improvement. Demos are released.
BASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data
Feb 15, 2024



We introduce a text-to-speech (TTS) model called BASE TTS, which stands for $\textbf{B}$ig $\textbf{A}$daptive $\textbf{S}$treamable TTS with $\textbf{E}$mergent abilities. BASE TTS is the largest TTS model to-date, trained on 100K hours of public domain speech data, achieving a new state-of-the-art in speech naturalness. It deploys a 1-billion-parameter autoregressive Transformer that converts raw texts into discrete codes ("speechcodes") followed by a convolution-based decoder which converts these speechcodes into waveforms in an incremental, streamable manner. Further, our speechcodes are built using a novel speech tokenization technique that features speaker ID disentanglement and compression with byte-pair encoding. Echoing the widely-reported "emergent abilities" of large language models when trained on increasing volume of data, we show that BASE TTS variants built with 10K+ hours and 500M+ parameters begin to demonstrate natural prosody on textually complex sentences. We design and share a specialized dataset to measure these emergent abilities for text-to-speech. We showcase state-of-the-art naturalness of BASE TTS by evaluating against baselines that include publicly available large-scale text-to-speech systems: YourTTS, Bark and TortoiseTTS. Audio samples generated by the model can be heard at https://amazon-ltts-paper.com/.
Cross-Speaker Encoding Network for Multi-Talker Speech Recognition
Jan 08, 2024



End-to-end multi-talker speech recognition has garnered great interest as an effective approach to directly transcribe overlapped speech from multiple speakers. Current methods typically adopt either 1) single-input multiple-output (SIMO) models with a branched encoder, or 2) single-input single-output (SISO) models based on attention-based encoder-decoder architecture with serialized output training (SOT). In this work, we propose a Cross-Speaker Encoding (CSE) network to address the limitations of SIMO models by aggregating cross-speaker representations. Furthermore, the CSE model is integrated with SOT to leverage both the advantages of SIMO and SISO while mitigating their drawbacks. To the best of our knowledge, this work represents an early effort to integrate SIMO and SISO for multi-talker speech recognition. Experiments on the two-speaker LibrispeechMix dataset show that the CES model reduces word error rate (WER) by 8% over the SIMO baseline. The CSE-SOT model reduces WER by 10% overall and by 16% on high-overlap speech compared to the SOT model.
QS-TTS: Towards Semi-Supervised Text-to-Speech Synthesis via Vector-Quantized Self-Supervised Speech Representation Learning
Aug 31, 2023



This paper proposes a novel semi-supervised TTS framework, QS-TTS, to improve TTS quality with lower supervised data requirements via Vector-Quantized Self-Supervised Speech Representation Learning (VQ-S3RL) utilizing more unlabeled speech audio. This framework comprises two VQ-S3R learners: first, the principal learner aims to provide a generative Multi-Stage Multi-Codebook (MSMC) VQ-S3R via the MSMC-VQ-GAN combined with the contrastive S3RL, while decoding it back to the high-quality audio; then, the associate learner further abstracts the MSMC representation into a highly-compact VQ representation through a VQ-VAE. These two generative VQ-S3R learners provide profitable speech representations and pre-trained models for TTS, significantly improving synthesis quality with the lower requirement for supervised data. QS-TTS is evaluated comprehensively under various scenarios via subjective and objective tests in experiments. The results powerfully demonstrate the superior performance of QS-TTS, winning the highest MOS over supervised or semi-supervised baseline TTS approaches, especially in low-resource scenarios. Moreover, comparing various speech representations and transfer learning methods in TTS further validates the notable improvement of the proposed VQ-S3RL to TTS, showing the best audio quality and intelligibility metrics. The trend of slower decay in the synthesis quality of QS-TTS with decreasing supervised data further highlights its lower requirements for supervised data, indicating its great potential in low-resource scenarios.