 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSTBench: Beyond Semantic Evaluation for Speech Translation
May 29, 2026Speech translation systems increasingly span speech-to-text translation (S2TT), speech-to-speech translation (S2ST), offline translation, and streaming generation, producing outputs that differ in modality, speech realization, and timing behavior. Existing evaluation practices assess important aspects such as translation quality, speech quality, and temporal quality, but these aspects are often evaluated under separate protocols, making it difficult to compare heterogeneous systems comprehensively. To address this gap, we present OpenSTBench, a unified multidimensional evaluation framework that organizes heterogeneous speech translation outputs into a shared evaluation format. OpenSTBench supports both S2TT and S2ST systems in offline and streaming settings, and jointly evaluates translation quality, speech quality, speaker preservation, emotion and paralinguistic fidelity, temporal consistency, and latency. Through experiments on representative speech translation systems, we show that systems with strong translation quality can still differ substantially in speech quality, as well as in temporal quality. OpenSTBench provides a reproducible protocol for analyzing these cross-dimensional differences and supporting application-oriented comparison of speech translation systems. The code and datasets are available at https://github.com/sjtuayj/OpenSTBench.
X-VC: Zero-shot Streaming Voice Conversion in Codec Space
Apr 14, 2026Zero-shot voice conversion (VC) aims to convert a source utterance into the voice of an unseen target speaker while preserving its linguistic content. Although recent systems have improved conversion quality, building zero-shot VC systems for interactive scenarios remains challenging because high-fidelity speaker transfer and low-latency streaming inference are difficult to achieve simultaneously. In this work, we present X-VC, a zero-shot streaming VC system that performs one-step conversion in the latent space of a pretrained neural codec. X-VC uses a dual-conditioning acoustic converter that jointly models source codec latents and frame-level acoustic conditions derived from target reference speech, while injecting utterance-level target speaker information through adaptive normalization. To reduce the mismatch between training and inference, we train the model with generated paired data and a role-assignment strategy that combines standard, reconstruction, and reversed modes. For streaming inference, we further adopt a chunkwise inference scheme with overlap smoothing that is aligned with the segment-based training paradigm of the codec. Experiments on Seed-TTS-Eval show that X-VC achieves the best streaming WER in both English and Chinese, strong speaker similarity in same-language and cross-lingual settings, and substantially lower offline real-time factor than the compared baselines. These results suggest that codec-space one-step conversion is a practical approach for building high-quality low-latency zero-shot VC systems. Audio samples are available at https://x-vc.github.io. Our code and checkpoints will also be released.
Accelerating Flow-Matching-Based Text-to-Speech via Empirically Pruned Step Sampling
May 26, 2025



Flow-matching-based text-to-speech (TTS) models, such as Voicebox, E2 TTS, and F5-TTS, have attracted significant attention in recent years. These models require multiple sampling steps to reconstruct speech from noise, making inference speed a key challenge. Reducing the number of sampling steps can greatly improve inference efficiency. To this end, we introduce Fast F5-TTS, a training-free approach to accelerate the inference of flow-matching-based TTS models. By inspecting the sampling trajectory of F5-TTS, we identify redundant steps and propose Empirically Pruned Step Sampling (EPSS), a non-uniform time-step sampling strategy that effectively reduces the number of sampling steps. Our approach achieves a 7-step generation with an inference RTF of 0.030 on an NVIDIA RTX 3090 GPU, making it 4 times faster than the original F5-TTS while maintaining comparable performance. Furthermore, EPSS performs well on E2 TTS models, demonstrating its strong generalization ability.
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025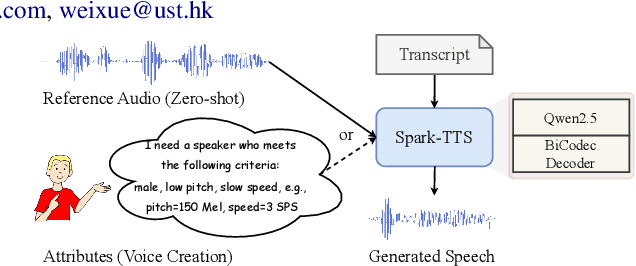



Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.