 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025



We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.
DiTAR: Diffusion Transformer Autoregressive Modeling for Speech Generation
Feb 06, 2025



Several recent studies have attempted to autoregressively generate continuous speech representations without discrete speech tokens by combining diffusion and autoregressive models, yet they often face challenges with excessive computational loads or suboptimal outcomes. In this work, we propose Diffusion Transformer Autoregressive Modeling (DiTAR), a patch-based autoregressive framework combining a language model with a diffusion transformer. This approach significantly enhances the efficacy of autoregressive models for continuous tokens and reduces computational demands. DiTAR utilizes a divide-and-conquer strategy for patch generation, where the language model processes aggregated patch embeddings and the diffusion transformer subsequently generates the next patch based on the output of the language model. For inference, we propose defining temperature as the time point of introducing noise during the reverse diffusion ODE to balance diversity and determinism. We also show in the extensive scaling analysis that DiTAR has superb scalability. In zero-shot speech generation, DiTAR achieves state-of-the-art performance in robustness, speaker similarity, and naturalness.
Language Model Can Listen While Speaking
Aug 05, 2024



Dialogue serves as the most natural manner of human-computer interaction (HCI). Recent advancements in speech language models (SLM) have significantly enhanced speech-based conversational AI. However, these models are limited to turn-based conversation, lacking the ability to interact with humans in real-time spoken scenarios, for example, being interrupted when the generated content is not satisfactory. To address these limitations, we explore full duplex modeling (FDM) in interactive speech language models (iSLM), focusing on enhancing real-time interaction and, more explicitly, exploring the quintessential ability of interruption. We introduce a novel model design, namely listening-while-speaking language model (LSLM), an end-to-end system equipped with both listening and speaking channels. Our LSLM employs a token-based decoder-only TTS for speech generation and a streaming self-supervised learning (SSL) encoder for real-time audio input. LSLM fuses both channels for autoregressive generation and detects turn-taking in real time. Three fusion strategies -- early fusion, middle fusion, and late fusion -- are explored, with middle fusion achieving an optimal balance between speech generation and real-time interaction. Two experimental settings, command-based FDM and voice-based FDM, demonstrate LSLM's robustness to noise and sensitivity to diverse instructions. Our results highlight LSLM's capability to achieve duplex communication with minimal impact on existing systems. This study aims to advance the development of interactive speech dialogue systems, enhancing their applicability in real-world contexts.
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024



We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
U-Style: Cascading U-nets with Multi-level Speaker and Style Modeling for Zero-Shot Voice Cloning
Oct 06, 2023



Zero-shot speaker cloning aims to synthesize speech for any target speaker unseen during TTS system building, given only a single speech reference of the speaker at hand. Although more practical in real applications, the current zero-shot methods still produce speech with undesirable naturalness and speaker similarity. Moreover, endowing the target speaker with arbitrary speaking styles in the zero-shot setup has not been considered. This is because the unique challenge of zero-shot speaker and style cloning is to learn the disentangled speaker and style representations from only short references representing an arbitrary speaker and an arbitrary style. To address this challenge, we propose U-Style, which employs Grad-TTS as the backbone, particularly cascading a speaker-specific encoder and a style-specific encoder between the text encoder and the diffusion decoder. Thus, leveraging signal perturbation, U-Style is explicitly decomposed into speaker- and style-specific modeling parts, achieving better speaker and style disentanglement. To improve unseen speaker and style modeling ability, these two encoders conduct multi-level speaker and style modeling by skip-connected U-nets, incorporating the representation extraction and information reconstruction process. Besides, to improve the naturalness of synthetic speech, we adopt mean-based instance normalization and style adaptive layer normalization in these encoders to perform representation extraction and condition adaptation, respectively. Experiments show that U-Style significantly surpasses the state-of-the-art methods in unseen speaker cloning regarding naturalness and speaker similarity. Notably, U-Style can transfer the style from an unseen source speaker to another unseen target speaker, achieving flexible combinations of desired speaker timbre and style in zero-shot voice cloning.
DiCLET-TTS: Diffusion Model based Cross-lingual Emotion Transfer for Text-to-Speech -- A Study between English and Mandarin
Sep 02, 2023



While the performance of cross-lingual TTS based on monolingual corpora has been significantly improved recently, generating cross-lingual speech still suffers from the foreign accent problem, leading to limited naturalness. Besides, current cross-lingual methods ignore modeling emotion, which is indispensable paralinguistic information in speech delivery. In this paper, we propose DiCLET-TTS, a Diffusion model based Cross-Lingual Emotion Transfer method that can transfer emotion from a source speaker to the intra- and cross-lingual target speakers. Specifically, to relieve the foreign accent problem while improving the emotion expressiveness, the terminal distribution of the forward diffusion process is parameterized into a speaker-irrelevant but emotion-related linguistic prior by a prior text encoder with the emotion embedding as a condition. To address the weaker emotional expressiveness problem caused by speaker disentanglement in emotion embedding, a novel orthogonal projection based emotion disentangling module (OP-EDM) is proposed to learn the speaker-irrelevant but emotion-discriminative embedding. Moreover, a condition-enhanced DPM decoder is introduced to strengthen the modeling ability of the speaker and the emotion in the reverse diffusion process to further improve emotion expressiveness in speech delivery. Cross-lingual emotion transfer experiments show the superiority of DiCLET-TTS over various competitive models and the good design of OP-EDM in learning speaker-irrelevant but emotion-discriminative embedding.
DSPGAN: a GAN-based universal vocoder for high-fidelity TTS by time-frequency domain supervision from DSP
Nov 02, 2022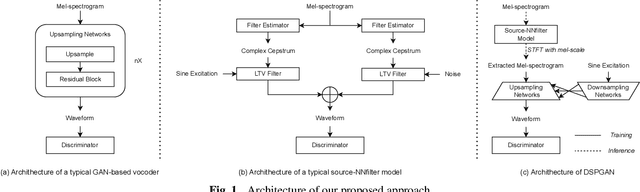
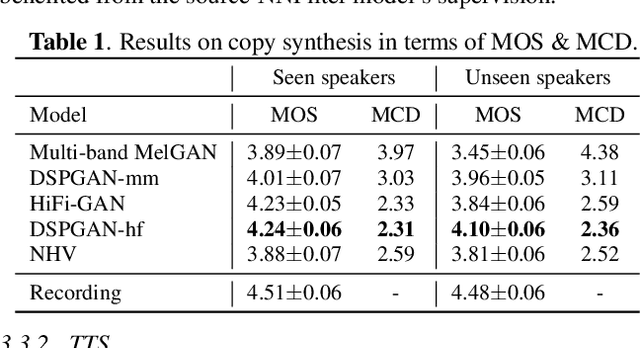
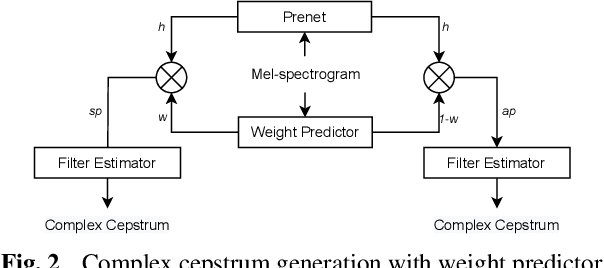

Recent development of neural vocoders based on the generative adversarial neural network (GAN) has shown their advantages of generating raw waveform conditioned on mel-spectrogram with fast inference speed and lightweight networks. Whereas, it is still challenging to train a universal neural vocoder that can synthesize high-fidelity speech from various scenarios with unseen speakers, languages, and speaking styles. In this paper, we propose DSPGAN, a GAN-based universal vocoder for high-fidelity speech synthesis by applying the time-frequency domain supervision from digital signal processing (DSP). To eliminate the mismatch problem caused by the ground-truth spectrograms in training phase and the predicted spectrograms in inference phase, we leverage the mel-spectrogram extracted from the waveform generated by a DSP module, rather than the predicted mel-spectrogram from the Text-to-Speech (TTS) acoustic model, as the time-frequency domain supervision to the GAN-based vocoder. We also utilize sine excitation as the time-domain supervision to improve the harmonic modeling and eliminate various artifacts of the GAN-based vocoder. Experimental results show that DSPGAN significantly outperforms the compared approaches and can generate high-fidelity speech based on diverse data in TTS.
Robust MelGAN: A robust universal neural vocoder for high-fidelity TTS
Nov 02, 2022



In current two-stage neural text-to-speech (TTS) paradigm, it is ideal to have a universal neural vocoder, once trained, which is robust to imperfect mel-spectrogram predicted from the acoustic model. To this end, we propose Robust MelGAN vocoder by solving the original multi-band MelGAN's metallic sound problem and increasing its generalization ability. Specifically, we introduce a fine-grained network dropout strategy to the generator. With a specifically designed over-smooth handler which separates speech signal intro periodic and aperiodic components, we only perform network dropout to the aperodic components, which alleviates metallic sounding and maintains good speaker similarity. To further improve generalization ability, we introduce several data augmentation methods to augment fake data in the discriminator, including harmonic shift, harmonic noise and phase noise. Experiments show that Robust MelGAN can be used as a universal vocoder, significantly improving sound quality in TTS systems built on various types of data.