 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Agents Look the Same: Quantifying Distillation-Induced Similarity in Tool-Use Behaviors
Apr 23, 2026Model distillation is a primary driver behind the rapid progress of LLM agents, yet it often leads to behavioral homogenization. Many emerging agents share nearly identical reasoning steps and failure modes, suggesting they may be distilled echoes of a few dominant teachers. Existing metrics, however, fail to distinguish mandatory behaviors required for task success from non-mandatory patterns that reflect a model's autonomous preferences. We propose two complementary metrics to isolate non-mandatory behavioral patterns: \textbf{Response Pattern Similarity (RPS)} for verbal alignment and \textbf{Action Graph Similarity (AGS)} for tool-use habits modeled as directed graphs. Evaluating 18 models from 8 providers on $τ$-Bench and $τ^2$-Bench against Claude Sonnet 4.5 (thinking), we find that within-family model pairs score 5.9 pp higher in AGS than cross-family pairs, and that Kimi-K2 (thinking) reaches 82.6\% $S_{\text{node}}$ and 94.7\% $S_{\text{dep}}$, exceeding Anthropic's own Opus 4.1. A controlled distillation experiment further confirms that AGS distinguishes teacher-specific convergence from general improvement. RPS and AGS capture distinct behavioral dimensions (Pearson $r$ = 0.491), providing complementary diagnostic signals for behavioral convergence in the agent ecosystem. Our code is available at https://github.com/Syuchin/AgentEcho.
WorldTravel: A Realistic Multimodal Travel-Planning Benchmark with Tightly Coupled Constraints
Feb 09, 2026Real-world autonomous planning requires coordinating tightly coupled constraints where a single decision dictates the feasibility of all subsequent actions. However, existing benchmarks predominantly feature loosely coupled constraints solvable through local greedy decisions and rely on idealized data, failing to capture the complexity of extracting parameters from dynamic web environments. We introduce \textbf{WorldTravel}, a benchmark comprising 150 real-world travel scenarios across 5 cities that demand navigating an average of 15+ interdependent temporal and logical constraints. To evaluate agents in realistic deployments, we develop \textbf{WorldTravel-Webscape}, a multi-modal environment featuring over 2,000 rendered webpages where agents must perceive constraint parameters directly from visual layouts to inform their planning. Our evaluation of 10 frontier models reveals a significant performance collapse: even the state-of-the-art GPT-5.2 achieves only 32.67\% feasibility in text-only settings, which plummets to 19.33\% in multi-modal environments. We identify a critical Perception-Action Gap and a Planning Horizon threshold at approximately 10 constraints where model reasoning consistently fails, suggesting that perception and reasoning remain independent bottlenecks. These findings underscore the need for next-generation agents that unify high-fidelity visual perception with long-horizon reasoning to handle brittle real-world logistics.
FutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
DiscoX: Benchmarking Discourse-Level Translation task in Expert Domains
Nov 14, 2025



The evaluation of discourse-level translation in expert domains remains inadequate, despite its centrality to knowledge dissemination and cross-lingual scholarly communication. While these translations demand discourse-level coherence and strict terminological precision, current evaluation methods predominantly focus on segment-level accuracy and fluency. To address this limitation, we introduce DiscoX, a new benchmark for discourse-level and expert-level Chinese-English translation. It comprises 200 professionally-curated texts from 7 domains, with an average length exceeding 1700 tokens. To evaluate performance on DiscoX, we also develop Metric-S, a reference-free system that provides fine-grained automatic assessments across accuracy, fluency, and appropriateness. Metric-S demonstrates strong consistency with human judgments, significantly outperforming existing metrics. Our experiments reveal a remarkable performance gap: even the most advanced LLMs still trail human experts on these tasks. This finding validates the difficulty of DiscoX and underscores the challenges that remain in achieving professional-grade machine translation. The proposed benchmark and evaluation system provide a robust framework for more rigorous evaluation, facilitating future advancements in LLM-based translation.
FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning
Sep 16, 2025



Search has emerged as core infrastructure for LLM-based agents and is widely viewed as critical on the path toward more general intelligence. Finance is a particularly demanding proving ground: analysts routinely conduct complex, multi-step searches over time-sensitive, domain-specific data, making it ideal for assessing both search proficiency and knowledge-grounded reasoning. Yet no existing open financial datasets evaluate data searching capability of end-to-end agents, largely because constructing realistic, complicated tasks requires deep financial expertise and time-sensitive data is hard to evaluate. We present FinSearchComp, the first fully open-source agent benchmark for realistic, open-domain financial search and reasoning. FinSearchComp comprises three tasks -- Time-Sensitive Data Fetching, Simple Historical Lookup, and Complex Historical Investigation -- closely reproduce real-world financial analyst workflows. To ensure difficulty and reliability, we engage 70 professional financial experts for annotation and implement a rigorous multi-stage quality-assurance pipeline. The benchmark includes 635 questions spanning global and Greater China markets, and we evaluate 21 models (products) on it. Grok 4 (web) tops the global subset, approaching expert-level accuracy. DouBao (web) leads on the Greater China subset. Experimental analyses show that equipping agents with web search and financial plugins substantially improves results on FinSearchComp, and the country origin of models and tools impact performance significantly.By aligning with realistic analyst tasks and providing end-to-end evaluation, FinSearchComp offers a professional, high-difficulty testbed for complex financial search and reasoning.
TreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling
Aug 24, 2025



Recent advancements in aligning large language models via reinforcement learning have achieved remarkable gains in solving complex reasoning problems, but at the cost of expensive on-policy rollouts and limited exploration of diverse reasoning paths. In this work, we introduce TreePO, involving a self-guided rollout algorithm that views sequence generation as a tree-structured searching process. Composed of dynamic tree sampling policy and fixed-length segment decoding, TreePO leverages local uncertainty to warrant additional branches. By amortizing computation across common prefixes and pruning low-value paths early, TreePO essentially reduces the per-update compute burden while preserving or enhancing exploration diversity. Key contributions include: (1) a segment-wise sampling algorithm that alleviates the KV cache burden through contiguous segments and spawns new branches along with an early-stop mechanism; (2) a tree-based segment-level advantage estimation that considers both global and local proximal policy optimization. and (3) analysis on the effectiveness of probability and quality-driven dynamic divergence and fallback strategy. We empirically validate the performance gain of TreePO on a set reasoning benchmarks and the efficiency saving of GPU hours from 22\% up to 43\% of the sampling design for the trained models, meanwhile showing up to 40\% reduction at trajectory-level and 35\% at token-level sampling compute for the existing models. While offering a free lunch of inference efficiency, TreePO reveals a practical path toward scaling RL-based post-training with fewer samples and less compute. Home page locates at https://m-a-p.ai/TreePO.
First Return, Entropy-Eliciting Explore
Jul 09, 2025Reinforcement Learning from Verifiable Rewards (RLVR) improves the reasoning abilities of Large Language Models (LLMs) but it struggles with unstable exploration. We propose FR3E (First Return, Entropy-Eliciting Explore), a structured exploration framework that identifies high-uncertainty decision points in reasoning trajectories and performs targeted rollouts to construct semantically grounded intermediate feedback. Our method provides targeted guidance without relying on dense supervision. Empirical results on mathematical reasoning benchmarks(AIME24) show that FR3E promotes more stable training, produces longer and more coherent responses, and increases the proportion of fully correct trajectories. These results highlight the framework's effectiveness in improving LLM reasoning through more robust and structured exploration.
SciDA: Scientific Dynamic Assessor of LLMs
Jun 15, 2025Advancement in Large Language Models (LLMs) reasoning capabilities enables them to solve scientific problems with enhanced efficacy. Thereby, a high-quality benchmark for comprehensive and appropriate assessment holds significance, while existing ones either confront the risk of data contamination or lack involved disciplines. To be specific, due to the data source overlap of LLMs training and static benchmark, the keys or number pattern of answers inadvertently memorized (i.e. data contamination), leading to systematic overestimation of their reasoning capabilities, especially numerical reasoning. We propose SciDA, a multidisciplinary benchmark that consists exclusively of over 1k Olympic-level numerical computation problems, allowing randomized numerical initializations for each inference round to avoid reliance on fixed numerical patterns. We conduct a series of experiments with both closed-source and open-source top-performing LLMs, and it is observed that the performance of LLMs drop significantly under random numerical initialization. Thus, we provide truthful and unbiased assessments of the numerical reasoning capabilities of LLMs. The data is available at https://huggingface.co/datasets/m-a-p/SciDA
MARS-Bench: A Multi-turn Athletic Real-world Scenario Benchmark for Dialogue Evaluation
May 27, 2025Large Language Models (\textbf{LLMs}), e.g. ChatGPT, have been widely adopted in real-world dialogue applications. However, LLMs' robustness, especially in handling long complex dialogue sessions, including frequent motivation transfer, sophisticated cross-turn dependency, is criticized all along. Nevertheless, no existing benchmarks can fully reflect these weaknesses. We present \textbf{MARS-Bench}, a \textbf{M}ulti-turn \textbf{A}thletic \textbf{R}eal-world \textbf{S}cenario Dialogue \textbf{Bench}mark, designed to remedy the gap. MARS-Bench is constructed from play-by-play text commentary so to feature realistic dialogues specifically designed to evaluate three critical aspects of multi-turn conversations: Ultra Multi-turn, Interactive Multi-turn, and Cross-turn Tasks. Extensive experiments on MARS-Bench also reveal that closed-source LLMs significantly outperform open-source alternatives, explicit reasoning significantly boosts LLMs' robustness on handling long complex dialogue sessions, and LLMs indeed face significant challenges when handling motivation transfer and sophisticated cross-turn dependency. Moreover, we provide mechanistic interpretability on how attention sinks due to special tokens lead to LLMs' performance degradation when handling long complex dialogue sessions based on attention visualization experiment in Qwen2.5-7B-Instruction.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025
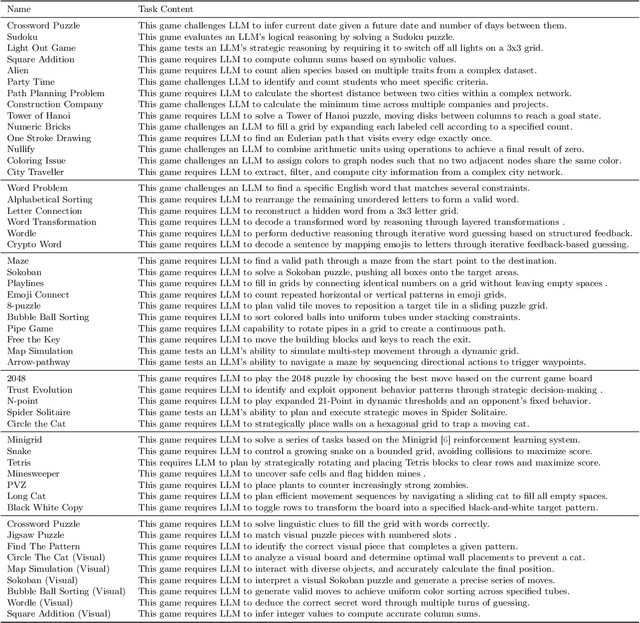
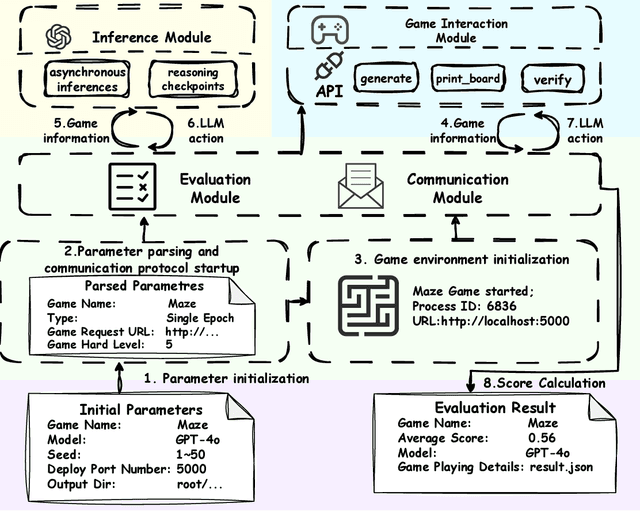

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.