 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Nano Banana Pro a Low-Level Vision All-Rounder? A Comprehensive Evaluation on 14 Tasks and 40 Datasets
Dec 19, 2025The rapid evolution of text-to-image generation models has revolutionized visual content creation. While commercial products like Nano Banana Pro have garnered significant attention, their potential as generalist solvers for traditional low-level vision challenges remains largely underexplored. In this study, we investigate the critical question: Is Nano Banana Pro a Low-Level Vision All-Rounder? We conducted a comprehensive zero-shot evaluation across 14 distinct low-level tasks spanning 40 diverse datasets. By utilizing simple textual prompts without fine-tuning, we benchmarked Nano Banana Pro against state-of-the-art specialist models. Our extensive analysis reveals a distinct performance dichotomy: while \textbf{Nano Banana Pro demonstrates superior subjective visual quality}, often hallucinating plausible high-frequency details that surpass specialist models, it lags behind in traditional reference-based quantitative metrics. We attribute this discrepancy to the inherent stochasticity of generative models, which struggle to maintain the strict pixel-level consistency required by conventional metrics. This report identifies Nano Banana Pro as a capable zero-shot contender for low-level vision tasks, while highlighting that achieving the high fidelity of domain specialists remains a significant hurdle.
GateFuseNet: An Adaptive 3D Multimodal Neuroimaging Fusion Network for Parkinson's Disease Diagnosis
Oct 26, 2025Accurate diagnosis of Parkinson's disease (PD) from MRI remains challenging due to symptom variability and pathological heterogeneity. Most existing methods rely on conventional magnitude-based MRI modalities, such as T1-weighted images (T1w), which are less sensitive to PD pathology than Quantitative Susceptibility Mapping (QSM), a phase-based MRI technique that quantifies iron deposition in deep gray matter nuclei. In this study, we propose GateFuseNet, an adaptive 3D multimodal fusion network that integrates QSM and T1w images for PD diagnosis. The core innovation lies in a gated fusion module that learns modality-specific attention weights and channel-wise gating vectors for selective feature modulation. This hierarchical gating mechanism enhances ROI-aware features while suppressing irrelevant signals. Experimental results show that our method outperforms three existing state-of-the-art approaches, achieving 85.00% accuracy and 92.06% AUC. Ablation studies further validate the contributions of ROI guidance, multimodal integration, and fusion positioning. Grad-CAM visualizations confirm the model's focus on clinically relevant pathological regions. The source codes and pretrained models can be found at https://github.com/YangGaoUQ/GateFuseNet
VideoLucy: Deep Memory Backtracking for Long Video Understanding
Oct 14, 2025



Recent studies have shown that agent-based systems leveraging large language models (LLMs) for key information retrieval and integration have emerged as a promising approach for long video understanding. However, these systems face two major challenges. First, they typically perform modeling and reasoning on individual frames, struggling to capture the temporal context of consecutive frames. Second, to reduce the cost of dense frame-level captioning, they adopt sparse frame sampling, which risks discarding crucial information. To overcome these limitations, we propose VideoLucy, a deep memory backtracking framework for long video understanding. Inspired by the human recollection process from coarse to fine, VideoLucy employs a hierarchical memory structure with progressive granularity. This structure explicitly defines the detail level and temporal scope of memory at different hierarchical depths. Through an agent-based iterative backtracking mechanism, VideoLucy systematically mines video-wide, question-relevant deep memories until sufficient information is gathered to provide a confident answer. This design enables effective temporal understanding of consecutive frames while preserving critical details. In addition, we introduce EgoMem, a new benchmark for long video understanding. EgoMem is designed to comprehensively evaluate a model's ability to understand complex events that unfold over time and capture fine-grained details in extremely long videos. Extensive experiments demonstrate the superiority of VideoLucy. Built on open-source models, VideoLucy significantly outperforms state-of-the-art methods on multiple long video understanding benchmarks, achieving performance even surpassing the latest proprietary models such as GPT-4o. Our code and dataset will be made publicly at https://videolucy.github.io
ReID5o: Achieving Omni Multi-modal Person Re-identification in a Single Model
Jun 11, 2025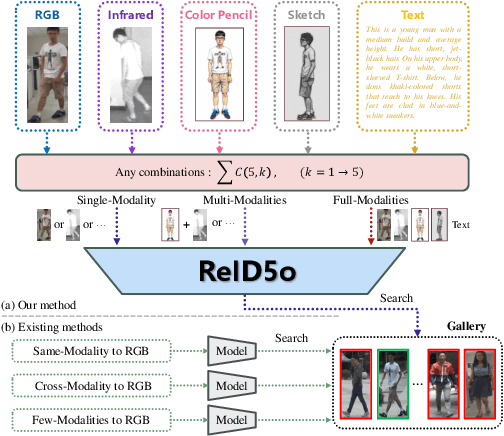
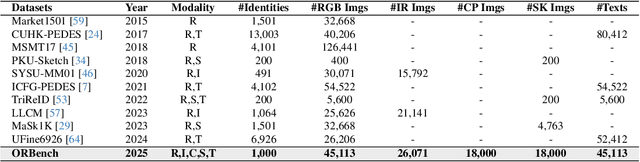
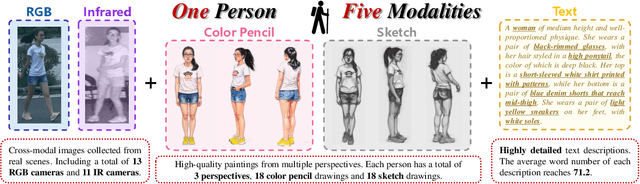
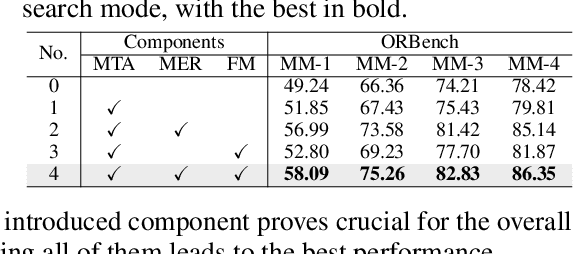
In real-word scenarios, person re-identification (ReID) expects to identify a person-of-interest via the descriptive query, regardless of whether the query is a single modality or a combination of multiple modalities. However, existing methods and datasets remain constrained to limited modalities, failing to meet this requirement. Therefore, we investigate a new challenging problem called Omni Multi-modal Person Re-identification (OM-ReID), which aims to achieve effective retrieval with varying multi-modal queries. To address dataset scarcity, we construct ORBench, the first high-quality multi-modal dataset comprising 1,000 unique identities across five modalities: RGB, infrared, color pencil, sketch, and textual description. This dataset also has significant superiority in terms of diversity, such as the painting perspectives and textual information. It could serve as an ideal platform for follow-up investigations in OM-ReID. Moreover, we propose ReID5o, a novel multi-modal learning framework for person ReID. It enables synergistic fusion and cross-modal alignment of arbitrary modality combinations in a single model, with a unified encoding and multi-expert routing mechanism proposed. Extensive experiments verify the advancement and practicality of our ORBench. A wide range of possible models have been evaluated and compared on it, and our proposed ReID5o model gives the best performance. The dataset and code will be made publicly available at https://github.com/Zplusdragon/ReID5o_ORBench.
HGS-Planner: Hierarchical Planning Framework for Active Scene Reconstruction Using 3D Gaussian Splatting
Sep 26, 2024In complex missions such as search and rescue,robots must make intelligent decisions in unknown environments, relying on their ability to perceive and understand their surroundings. High-quality and real-time reconstruction enhances situational awareness and is crucial for intelligent robotics. Traditional methods often struggle with poor scene representation or are too slow for real-time use. Inspired by the efficacy of 3D Gaussian Splatting (3DGS), we propose a hierarchical planning framework for fast and high-fidelity active reconstruction. Our method evaluates completion and quality gain to adaptively guide reconstruction, integrating global and local planning for efficiency. Experiments in simulated and real-world environments show our approach outperforms existing real-time methods.
AI-based Automatic Segmentation of Prostate on Multi-modality Images: A Review
Jul 09, 2024



Prostate cancer represents a major threat to health. Early detection is vital in reducing the mortality rate among prostate cancer patients. One approach involves using multi-modality (CT, MRI, US, etc.) computer-aided diagnosis (CAD) systems for the prostate region. However, prostate segmentation is challenging due to imperfections in the images and the prostate's complex tissue structure. The advent of precision medicine and a significant increase in clinical capacity have spurred the need for various data-driven tasks in the field of medical imaging. Recently, numerous machine learning and data mining tools have been integrated into various medical areas, including image segmentation. This article proposes a new classification method that differentiates supervision types, either in number or kind, during the training phase. Subsequently, we conducted a survey on artificial intelligence (AI)-based automatic prostate segmentation methods, examining the advantages and limitations of each. Additionally, we introduce variants of evaluation metrics for the verification and performance assessment of the segmentation method and summarize the current challenges. Finally, future research directions and development trends are discussed, reflecting the outcomes of our literature survey, suggesting high-precision detection and treatment of prostate cancer as a promising avenue.
GS-Planner: A Gaussian-Splatting-based Planning Framework for Active High-Fidelity Reconstruction
May 16, 2024Active reconstruction technique enables robots to autonomously collect scene data for full coverage, relieving users from tedious and time-consuming data capturing process. However, designed based on unsuitable scene representations, existing methods show unrealistic reconstruction results or the inability of online quality evaluation. Due to the recent advancements in explicit radiance field technology, online active high-fidelity reconstruction has become achievable. In this paper, we propose GS-Planner, a planning framework for active high-fidelity reconstruction using 3D Gaussian Splatting. With improvement on 3DGS to recognize unobserved regions, we evaluate the reconstruction quality and completeness of 3DGS map online to guide the robot. Then we design a sampling-based active reconstruction strategy to explore the unobserved areas and improve the reconstruction geometric and textural quality. To establish a complete robot active reconstruction system, we choose quadrotor as the robotic platform for its high agility. Then we devise a safety constraint with 3DGS to generate executable trajectories for quadrotor navigation in the 3DGS map. To validate the effectiveness of our method, we conduct extensive experiments and ablation studies in highly realistic simulation scenes.
Adaptive Tracking and Perching for Quadrotor in Dynamic Scenarios
Dec 19, 2023



Perching on the moving platforms is a promising solution to enhance the endurance and operational range of quadrotors, which could benefit the efficiency of a variety of air-ground cooperative tasks. To ensure robust perching, tracking with a steady relative state and reliable perception is a prerequisite. This paper presents an adaptive dynamic tracking and perching scheme for autonomous quadrotors to achieve tight integration with moving platforms. For reliable perception of dynamic targets, we introduce elastic visibility-aware planning to actively avoid occlusion and target loss. Additionally, we propose a flexible terminal adjustment method that adapts the changes in flight duration and the coupled terminal states, ensuring full-state synchronization with the time-varying perching surface at various angles. A relaxation strategy is developed by optimizing the tangential relative speed to address the dynamics and safety violations brought by hard boundary conditions. Moreover, we take SE(3) motion planning into account to ensure no collision between the quadrotor and the platform until the contact moment. Furthermore, we propose an efficient spatiotemporal trajectory optimization framework considering full state dynamics for tracking and perching. The proposed method is extensively tested through benchmark comparisons and ablation studies. To facilitate the application of academic research to industry and to validate the efficiency of our scheme under strictly limited computational resources, we deploy our system on a commercial drone (DJI-MAVIC3) with a full-size sport-utility vehicle (SUV). We conduct extensive real-world experiments, where the drone successfully tracks and perches at 30~km/h (8.3~m/s) on the top of the SUV, and at 3.5~m/s with 60{\deg} inclined into the trunk of the SUV.
Crossword: A Semantic Approach to Data Compression via Masking
Apr 03, 2023



The traditional methods for data compression are typically based on the symbol-level statistics, with the information source modeled as a long sequence of i.i.d. random variables or a stochastic process, thus establishing the fundamental limit as entropy for lossless compression and as mutual information for lossy compression. However, the source (including text, music, and speech) in the real world is often statistically ill-defined because of its close connection to human perception, and thus the model-driven approach can be quite suboptimal. This study places careful emphasis on English text and exploits its semantic aspect to enhance the compression efficiency further. The main idea stems from the puzzle crossword, observing that the hidden words can still be precisely reconstructed so long as some key letters are provided. The proposed masking-based strategy resembles the above game. In a nutshell, the encoder evaluates the semantic importance of each word according to the semantic loss and then masks the minor ones, while the decoder aims to recover the masked words from the semantic context by means of the Transformer. Our experiments show that the proposed semantic approach can achieve much higher compression efficiency than the traditional methods such as Huffman code and UTF-8 code, while preserving the meaning in the target text to a great extent.
MixNN: A design for protecting deep learning models
Mar 28, 2022

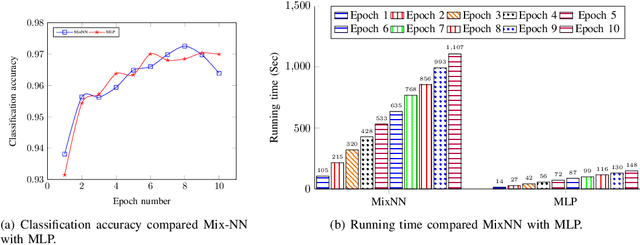
In this paper, we propose a novel design, called MixNN, for protecting deep learning model structure and parameters. The layers in a deep learning model of MixNN are fully decentralized. It hides communication address, layer parameters and operations, and forward as well as backward message flows among non-adjacent layers using the ideas from mix networks. MixNN has following advantages: 1) an adversary cannot fully control all layers of a model including the structure and parameters, 2) even some layers may collude but they cannot tamper with other honest layers, 3) model privacy is preserved in the training phase. We provide detailed descriptions for deployment. In one classification experiment, we compared a neural network deployed in a virtual machine with the same one using the MixNN design on the AWS EC2. The result shows that our MixNN retains less than 0.001 difference in terms of classification accuracy, while the whole running time of MixNN is about 7.5 times slower than the one running on a single virtual machine.