 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelecting Samples on Graphs: A Unified Dataset Pruning Framework for Lossless Training Acceleration
Jun 11, 2026The rapid growth of modern training datasets has significantly increased computational cost, motivating dataset pruning~(DP) methods which retain only a subset of informative samples to reduce training cost. Existing pruning criteria typically rely on either intrinsic signals that assess samples independently or extrinsic signals that promote diversity via pairwise relations. While effective in their own specific regimes, each captures only one aspect of sample utility and lacks robustness across different pruning ratios or data distribution. In this work, we present a unified graph-based DP framework. By modeling the dataset as a weighted graph, where node weights encode intrinsic value and edge weights encode extrinsic value, DP can be cast as a Maximum Weight Clique Problem (MWCP). Although MWCP is NP-hard, its structure admits a principled greedy solution based on sample-wise marginal gains. Under a few mild conditions, we further prove that this unified objective enjoys a formal approximation guarantee, which applies to a broad family of importance metrics and provides practical design guidelines. Extensive experiments show that our method outperforms existing DP methods while substantially reducing training cost, reducing training time by over 40\% without sacrificing accuracy on ImageNet-1k with ResNet-50.
INTACT: Ego-Guided Typed Sparse Evidence Retrieval for Heterogeneous Collaborative Perception
Jun 03, 2026Collaborative perception extends the perceptual range of autonomous vehicles by sharing information across agents, but heterogeneous sensors and perception models make intermediate feature fusion difficult to deploy at scale. Existing heterogeneous collaboration methods typically follow a translation-first paradigm: collaborator features must be aligned, adapted, or projected into an ego-compatible space before fusion. Such feature-compatibility contracts improve fixed-system performance, but they couple deployment to collaborator-specific adaptation and make newly joined heterogeneous agents costly to integrate. To address this gap, we propose INTACT, an ego-guided typed sparse evidence retrieval framework for heterogeneous collaborative perception. Instead of translating an entire collaborator feature map, INTACT lets the ego vehicle issue typed evidence queries that express suspected objects and evidence-deficient regions. Collaborators respond only with local evidence at queried locations, and the ego selects useful responses through sparse per-query routing and injects them through gated residual write-back. This changes the compatibility requirement from global feature-map interpretability to local, typed response comparability under ego-issued queries, enabling a zero-training heterogeneous insertion protocol in which the ego interface is trained once and new collaborators join through checkpoint merging. Extensive experiments on simulated and real-world heterogeneous collaborative perception benchmarks validate the effectiveness and deployability of INTACT. On OPV2V-H, INTACT achieves 80.1 AP70 with only 0.52M additional parameters and 18.0 $\log_2$ communication volume, corresponding to about 16$\times$ compression over dense feature transmission. On DAIR-V2X, INTACT achieves 43.8 AP50 under challenging real-world conditions.
DenseGRPO: From Sparse to Dense Reward for Flow Matching Model Alignment
Jan 28, 2026Recent GRPO-based approaches built on flow matching models have shown remarkable improvements in human preference alignment for text-to-image generation. Nevertheless, they still suffer from the sparse reward problem: the terminal reward of the entire denoising trajectory is applied to all intermediate steps, resulting in a mismatch between the global feedback signals and the exact fine-grained contributions at intermediate denoising steps. To address this issue, we introduce \textbf{DenseGRPO}, a novel framework that aligns human preference with dense rewards, which evaluates the fine-grained contribution of each denoising step. Specifically, our approach includes two key components: (1) we propose to predict the step-wise reward gain as dense reward of each denoising step, which applies a reward model on the intermediate clean images via an ODE-based approach. This manner ensures an alignment between feedback signals and the contributions of individual steps, facilitating effective training; and (2) based on the estimated dense rewards, a mismatch drawback between the uniform exploration setting and the time-varying noise intensity in existing GRPO-based methods is revealed, leading to an inappropriate exploration space. Thus, we propose a reward-aware scheme to calibrate the exploration space by adaptively adjusting a timestep-specific stochasticity injection in the SDE sampler, ensuring a suitable exploration space at all timesteps. Extensive experiments on multiple standard benchmarks demonstrate the effectiveness of the proposed DenseGRPO and highlight the critical role of the valid dense rewards in flow matching model alignment.
Is Nano Banana Pro a Low-Level Vision All-Rounder? A Comprehensive Evaluation on 14 Tasks and 40 Datasets
Dec 19, 2025The rapid evolution of text-to-image generation models has revolutionized visual content creation. While commercial products like Nano Banana Pro have garnered significant attention, their potential as generalist solvers for traditional low-level vision challenges remains largely underexplored. In this study, we investigate the critical question: Is Nano Banana Pro a Low-Level Vision All-Rounder? We conducted a comprehensive zero-shot evaluation across 14 distinct low-level tasks spanning 40 diverse datasets. By utilizing simple textual prompts without fine-tuning, we benchmarked Nano Banana Pro against state-of-the-art specialist models. Our extensive analysis reveals a distinct performance dichotomy: while \textbf{Nano Banana Pro demonstrates superior subjective visual quality}, often hallucinating plausible high-frequency details that surpass specialist models, it lags behind in traditional reference-based quantitative metrics. We attribute this discrepancy to the inherent stochasticity of generative models, which struggle to maintain the strict pixel-level consistency required by conventional metrics. This report identifies Nano Banana Pro as a capable zero-shot contender for low-level vision tasks, while highlighting that achieving the high fidelity of domain specialists remains a significant hurdle.
Learning to Tell Apart: Weakly Supervised Video Anomaly Detection via Disentangled Semantic Alignment
Nov 13, 2025Recent advancements in weakly-supervised video anomaly detection have achieved remarkable performance by applying the multiple instance learning paradigm based on multimodal foundation models such as CLIP to highlight anomalous instances and classify categories. However, their objectives may tend to detect the most salient response segments, while neglecting to mine diverse normal patterns separated from anomalies, and are prone to category confusion due to similar appearance, leading to unsatisfactory fine-grained classification results. Therefore, we propose a novel Disentangled Semantic Alignment Network (DSANet) to explicitly separate abnormal and normal features from coarse-grained and fine-grained aspects, enhancing the distinguishability. Specifically, at the coarse-grained level, we introduce a self-guided normality modeling branch that reconstructs input video features under the guidance of learned normal prototypes, encouraging the model to exploit normality cues inherent in the video, thereby improving the temporal separation of normal patterns and anomalous events. At the fine-grained level, we present a decoupled contrastive semantic alignment mechanism, which first temporally decomposes each video into event-centric and background-centric components using frame-level anomaly scores and then applies visual-language contrastive learning to enhance class-discriminative representations. Comprehensive experiments on two standard benchmarks, namely XD-Violence and UCF-Crime, demonstrate that DSANet outperforms existing state-of-the-art methods.
VideoLucy: Deep Memory Backtracking for Long Video Understanding
Oct 14, 2025



Recent studies have shown that agent-based systems leveraging large language models (LLMs) for key information retrieval and integration have emerged as a promising approach for long video understanding. However, these systems face two major challenges. First, they typically perform modeling and reasoning on individual frames, struggling to capture the temporal context of consecutive frames. Second, to reduce the cost of dense frame-level captioning, they adopt sparse frame sampling, which risks discarding crucial information. To overcome these limitations, we propose VideoLucy, a deep memory backtracking framework for long video understanding. Inspired by the human recollection process from coarse to fine, VideoLucy employs a hierarchical memory structure with progressive granularity. This structure explicitly defines the detail level and temporal scope of memory at different hierarchical depths. Through an agent-based iterative backtracking mechanism, VideoLucy systematically mines video-wide, question-relevant deep memories until sufficient information is gathered to provide a confident answer. This design enables effective temporal understanding of consecutive frames while preserving critical details. In addition, we introduce EgoMem, a new benchmark for long video understanding. EgoMem is designed to comprehensively evaluate a model's ability to understand complex events that unfold over time and capture fine-grained details in extremely long videos. Extensive experiments demonstrate the superiority of VideoLucy. Built on open-source models, VideoLucy significantly outperforms state-of-the-art methods on multiple long video understanding benchmarks, achieving performance even surpassing the latest proprietary models such as GPT-4o. Our code and dataset will be made publicly at https://videolucy.github.io
Learning Unpaired Image Dehazing with Physics-based Rehazy Generation
Jun 15, 2025



Overfitting to synthetic training pairs remains a critical challenge in image dehazing, leading to poor generalization capability to real-world scenarios. To address this issue, existing approaches utilize unpaired realistic data for training, employing CycleGAN or contrastive learning frameworks. Despite their progress, these methods often suffer from training instability, resulting in limited dehazing performance. In this paper, we propose a novel training strategy for unpaired image dehazing, termed Rehazy, to improve both dehazing performance and training stability. This strategy explores the consistency of the underlying clean images across hazy images and utilizes hazy-rehazy pairs for effective learning of real haze characteristics. To favorably construct hazy-rehazy pairs, we develop a physics-based rehazy generation pipeline, which is theoretically validated to reliably produce high-quality rehazy images. Additionally, leveraging the rehazy strategy, we introduce a dual-branch framework for dehazing network training, where a clean branch provides a basic dehazing capability in a synthetic manner, and a hazy branch enhances the generalization ability with hazy-rehazy pairs. Moreover, we design a new dehazing network within these branches to improve the efficiency, which progressively restores clean scenes from coarse to fine. Extensive experiments on four benchmarks demonstrate the superior performance of our approach, exceeding the previous state-of-the-art methods by 3.58 dB on the SOTS-Indoor dataset and by 1.85 dB on the SOTS-Outdoor dataset in PSNR. Our code will be publicly available.
ReID5o: Achieving Omni Multi-modal Person Re-identification in a Single Model
Jun 11, 2025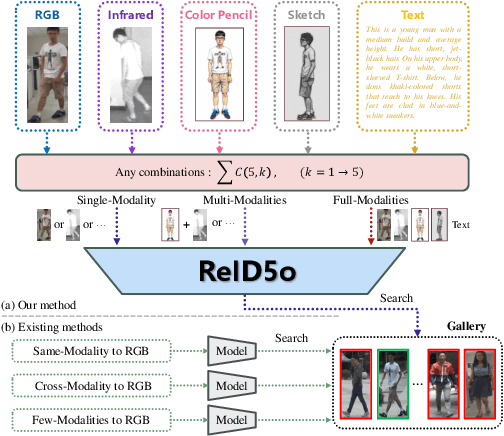
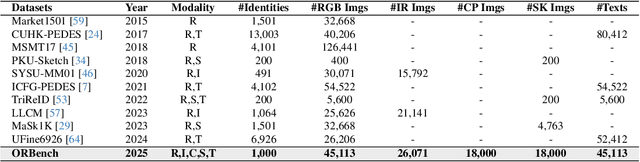
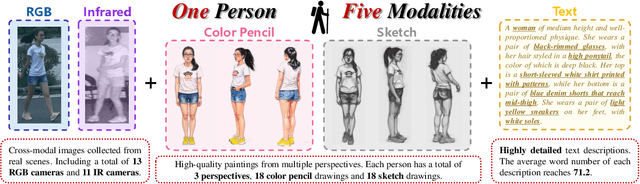
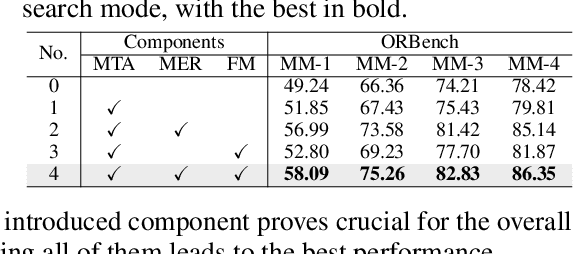
In real-word scenarios, person re-identification (ReID) expects to identify a person-of-interest via the descriptive query, regardless of whether the query is a single modality or a combination of multiple modalities. However, existing methods and datasets remain constrained to limited modalities, failing to meet this requirement. Therefore, we investigate a new challenging problem called Omni Multi-modal Person Re-identification (OM-ReID), which aims to achieve effective retrieval with varying multi-modal queries. To address dataset scarcity, we construct ORBench, the first high-quality multi-modal dataset comprising 1,000 unique identities across five modalities: RGB, infrared, color pencil, sketch, and textual description. This dataset also has significant superiority in terms of diversity, such as the painting perspectives and textual information. It could serve as an ideal platform for follow-up investigations in OM-ReID. Moreover, we propose ReID5o, a novel multi-modal learning framework for person ReID. It enables synergistic fusion and cross-modal alignment of arbitrary modality combinations in a single model, with a unified encoding and multi-expert routing mechanism proposed. Extensive experiments verify the advancement and practicality of our ORBench. A wide range of possible models have been evaluated and compared on it, and our proposed ReID5o model gives the best performance. The dataset and code will be made publicly available at https://github.com/Zplusdragon/ReID5o_ORBench.
MP-Mat: A 3D-and-Instance-Aware Human Matting and Editing Framework with Multiplane Representation
Apr 20, 2025



Human instance matting aims to estimate an alpha matte for each human instance in an image, which is challenging as it easily fails in complex cases requiring disentangling mingled pixels belonging to multiple instances along hairy and thin boundary structures. In this work, we address this by introducing MP-Mat, a novel 3D-and-instance-aware matting framework with multiplane representation, where the multiplane concept is designed from two different perspectives: scene geometry level and instance level. Specifically, we first build feature-level multiplane representations to split the scene into multiple planes based on depth differences. This approach makes the scene representation 3D-aware, and can serve as an effective clue for splitting instances in different 3D positions, thereby improving interpretability and boundary handling ability especially in occlusion areas. Then, we introduce another multiplane representation that splits the scene in an instance-level perspective, and represents each instance with both matte and color. We also treat background as a special instance, which is often overlooked by existing methods. Such an instance-level representation facilitates both foreground and background content awareness, and is useful for other down-stream tasks like image editing. Once built, the representation can be reused to realize controllable instance-level image editing with high efficiency. Extensive experiments validate the clear advantage of MP-Mat in matting task. We also demonstrate its superiority in image editing tasks, an area under-explored by existing matting-focused methods, where our approach under zero-shot inference even outperforms trained specialized image editing techniques by large margins. Code is open-sourced at https://github.com/JiaoSiyi/MPMat.git}.
UniAnimate-DiT: Human Image Animation with Large-Scale Video Diffusion Transformer
Apr 15, 2025


This report presents UniAnimate-DiT, an advanced project that leverages the cutting-edge and powerful capabilities of the open-source Wan2.1 model for consistent human image animation. Specifically, to preserve the robust generative capabilities of the original Wan2.1 model, we implement Low-Rank Adaptation (LoRA) technique to fine-tune a minimal set of parameters, significantly reducing training memory overhead. A lightweight pose encoder consisting of multiple stacked 3D convolutional layers is designed to encode motion information of driving poses. Furthermore, we adopt a simple concatenation operation to integrate the reference appearance into the model and incorporate the pose information of the reference image for enhanced pose alignment. Experimental results show that our approach achieves visually appearing and temporally consistent high-fidelity animations. Trained on 480p (832x480) videos, UniAnimate-DiT demonstrates strong generalization capabilities to seamlessly upscale to 720P (1280x720) during inference. The training and inference code is publicly available at https://github.com/ali-vilab/UniAnimate-DiT.