 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpiScreen: Early Epilepsy Detection from Electronic Health Records with Large Language Models
Mar 30, 2026Epilepsy and psychogenic non-epileptic seizures often present with similar seizure-like manifestations but require fundamentally different management strategies. Misdiagnosis is common and can lead to prolonged diagnostic delays, unnecessary treatments, and substantial patient morbidity. Although prolonged video-electroencephalography is the diagnostic gold standard, its high cost and limited accessibility hinder timely diagnosis. Here, we developed a low-cost, effective approach, EpiScreen, for early epilepsy detection by utilizing routinely collected clinical notes from electronic health records. Through fine-tuning large language models on labeled notes, EpiScreen achieved an AUC of up to 0.875 on the MIMIC-IV dataset and 0.980 on a private cohort of the University of Minnesota. In a clinician-AI collaboration setting, EpiScreen-assisted neurologists outperformed unaided experts by up to 10.9%. Overall, this study demonstrates that EpiScreen supports early epilepsy detection, facilitating timely and cost-effective screening that may reduce diagnostic delays and avoid unnecessary interventions, particularly in resource-limited regions.
MedCL-Bench: Benchmarking stability-efficiency trade-offs and scaling in biomedical continual learning
Mar 17, 2026Medical language models must be updated as evidence and terminology evolve, yet sequential updating can trigger catastrophic forgetting. Although biomedical NLP has many static benchmarks, no unified, task-diverse benchmark exists for evaluating continual learning under standardized protocols, robustness to task order and compute-aware reporting. We introduce MedCL-Bench, which streams ten biomedical NLP datasets spanning five task families and evaluates eleven continual learning strategies across eight task orders, reporting retention, transfer, and GPU-hour cost. Across backbones and task orders, direct sequential fine-tuning on incoming tasks induces catastrophic forgetting, causing update-induced performance regressions on prior tasks. Continual learning methods occupy distinct retention-compute frontiers: parameter-isolation provides the best retention per GPU-hour, replay offers strong protection at higher cost, and regularization yields limited benefit. Forgetting is task-dependent, with multi-label topic classification most vulnerable and constrained-output tasks more robust. MedCL-Bench provides a reproducible framework for auditing model updates before deployment.
HeartAgent: An Autonomous Agent System for Explainable Differential Diagnosis in Cardiology
Mar 11, 2026Heart diseases remain a leading cause of morbidity and mortality worldwide, necessitating accurate and trustworthy differential diagnosis. However, existing artificial intelligence-based diagnostic methods are often limited by insufficient cardiology knowledge, inadequate support for complex reasoning, and poor interpretability. Here we present HeartAgent, a cardiology-specific agent system designed to support a reliable and explainable differential diagnosis. HeartAgent integrates customized tools and curated data resources and orchestrates multiple specialized sub-agents to perform complex reasoning while generating transparent reasoning trajectories and verifiable supporting references. Evaluated on the MIMIC dataset and a private electronic health records cohort, HeartAgent achieved over 36% and 20% improvements over established comparative methods, in top-3 diagnostic accuracy, respectively. Additionally, clinicians assisted by HeartAgent demonstrated gains of 26.9% in diagnostic accuracy and 22.7% in explanatory quality compared with unaided experts. These results demonstrate that HeartAgent provides reliable, explainable, and clinically actionable decision support for cardiovascular care.
To Reason or Not to: Selective Chain-of-Thought in Medical Question Answering
Feb 23, 2026Objective: To improve the efficiency of medical question answering (MedQA) with large language models (LLMs) by avoiding unnecessary reasoning while maintaining accuracy. Methods: We propose Selective Chain-of-Thought (Selective CoT), an inference-time strategy that first predicts whether a question requires reasoning and generates a rationale only when needed. Two open-source LLMs (Llama-3.1-8B and Qwen-2.5-7B) were evaluated on four biomedical QA benchmarks-HeadQA, MedQA-USMLE, MedMCQA, and PubMedQA. Metrics included accuracy, total generated tokens, and inference time. Results: Selective CoT reduced inference time by 13-45% and token usage by 8-47% with minimal accuracy loss ($\leq$4\%). In some model-task pairs, it achieved both higher accuracy and greater efficiency than standard CoT. Compared with fixed-length CoT, Selective CoT reached similar or superior accuracy at substantially lower computational cost. Discussion: Selective CoT dynamically balances reasoning depth and efficiency by invoking explicit reasoning only when beneficial, reducing redundancy on recall-type questions while preserving interpretability. Conclusion: Selective CoT provides a simple, model-agnostic, and cost-effective approach for medical QA, aligning reasoning effort with question complexity to enhance real-world deployability of LLM-based clinical systems.
Dynamic Residual Encoding with Slide-Level Contrastive Learning for End-to-End Whole Slide Image Representation
Nov 07, 2025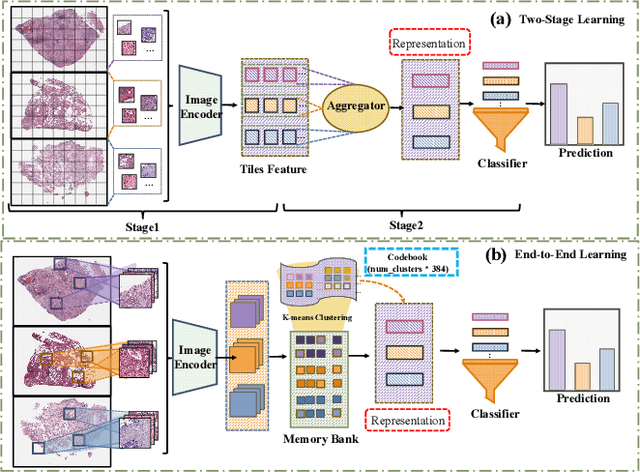

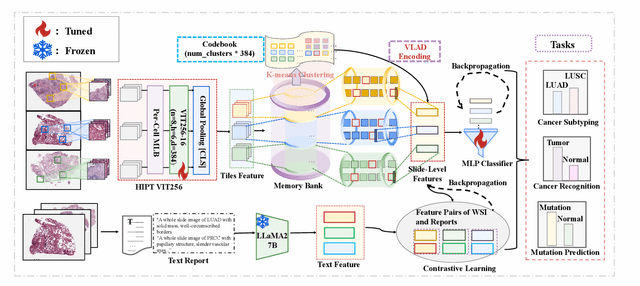
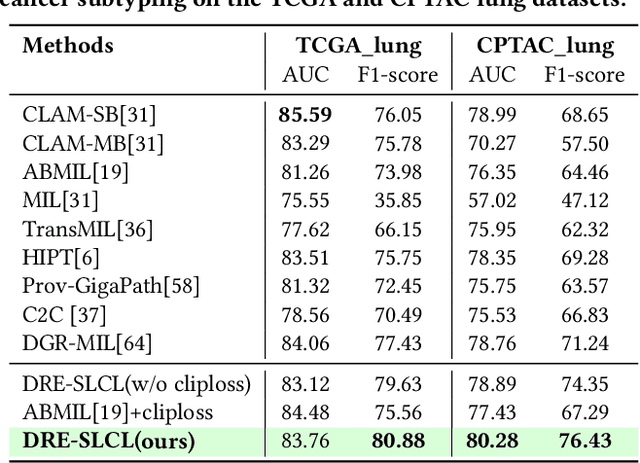
Whole Slide Image (WSI) representation is critical for cancer subtyping, cancer recognition and mutation prediction.Training an end-to-end WSI representation model poses significant challenges, as a standard gigapixel slide can contain tens of thousands of image tiles, making it difficult to compute gradients of all tiles in a single mini-batch due to current GPU limitations. To address this challenge, we propose a method of dynamic residual encoding with slide-level contrastive learning (DRE-SLCL) for end-to-end WSI representation. Our approach utilizes a memory bank to store the features of tiles across all WSIs in the dataset. During training, a mini-batch usually contains multiple WSIs. For each WSI in the batch, a subset of tiles is randomly sampled and their features are computed using a tile encoder. Then, additional tile features from the same WSI are selected from the memory bank. The representation of each individual WSI is generated using a residual encoding technique that incorporates both the sampled features and those retrieved from the memory bank. Finally, the slide-level contrastive loss is computed based on the representations and histopathology reports ofthe WSIs within the mini-batch. Experiments conducted over cancer subtyping, cancer recognition, and mutation prediction tasks proved the effectiveness of the proposed DRE-SLCL method.
* 8pages, 3figures, published to ACM Digital Library
GateFuseNet: An Adaptive 3D Multimodal Neuroimaging Fusion Network for Parkinson's Disease Diagnosis
Oct 26, 2025Accurate diagnosis of Parkinson's disease (PD) from MRI remains challenging due to symptom variability and pathological heterogeneity. Most existing methods rely on conventional magnitude-based MRI modalities, such as T1-weighted images (T1w), which are less sensitive to PD pathology than Quantitative Susceptibility Mapping (QSM), a phase-based MRI technique that quantifies iron deposition in deep gray matter nuclei. In this study, we propose GateFuseNet, an adaptive 3D multimodal fusion network that integrates QSM and T1w images for PD diagnosis. The core innovation lies in a gated fusion module that learns modality-specific attention weights and channel-wise gating vectors for selective feature modulation. This hierarchical gating mechanism enhances ROI-aware features while suppressing irrelevant signals. Experimental results show that our method outperforms three existing state-of-the-art approaches, achieving 85.00% accuracy and 92.06% AUC. Ablation studies further validate the contributions of ROI guidance, multimodal integration, and fusion positioning. Grad-CAM visualizations confirm the model's focus on clinically relevant pathological regions. The source codes and pretrained models can be found at https://github.com/YangGaoUQ/GateFuseNet
PychoBench: Evaluating the Psychology Intelligence of Large Language Models
Oct 02, 2025



Large Language Models (LLMs) have demonstrated remarkable success across a wide range of industries, primarily due to their impressive generative abilities. Yet, their potential in applications requiring cognitive abilities, such as psychological counseling, remains largely untapped. This paper investigates the key question: Can LLMs be effectively applied to psychological counseling? To determine whether an LLM can effectively take on the role of a psychological counselor, the first step is to assess whether it meets the qualifications required for such a role, namely the ability to pass the U.S. National Counselor Certification Exam (NCE). This is because, just as a human counselor must pass a certification exam to practice, an LLM must demonstrate sufficient psychological knowledge to meet the standards required for such a role. To address this, we introduce PsychoBench, a benchmark grounded in U.S.national counselor examinations, a licensure test for professional counselors that requires about 70% accuracy to pass. PsychoBench comprises approximately 2,252 carefully curated single-choice questions, crafted to require deep understanding and broad enough to cover various sub-disciplines of psychology. This benchmark provides a comprehensive assessment of an LLM's ability to function as a counselor. Our evaluation shows that advanced models such as GPT-4o, Llama3.3-70B, and Gemma3-27B achieve well above the passing threshold, while smaller open-source models (e.g., Qwen2.5-7B, Mistral-7B) remain far below it. These results suggest that only frontier LLMs are currently capable of meeting counseling exam standards, highlighting both the promise and the challenges of developing psychology-oriented LLMs.
Data Quality Enhancement on the Basis of Diversity with Large Language Models for Text Classification: Uncovered, Difficult, and Noisy
Dec 10, 2024



In recent years, the use of large language models (LLMs) for text classification has attracted widespread attention. Despite this, the classification accuracy of LLMs has not yet universally surpassed that of smaller models. LLMs can enhance their performance in text classification through fine-tuning. However, existing data quality research based on LLMs is challenging to apply directly to solve text classification problems. To further improve the performance of LLMs in classification tasks, this paper proposes a data quality enhancement (DQE) method for text classification based on LLMs. This method starts by using a greedy algorithm to select data, dividing the dataset into sampled and unsampled subsets, and then performing fine-tuning of the LLMs using the sampled data. Subsequently, this model is used to predict the outcomes for the unsampled data, categorizing incorrectly predicted data into uncovered, difficult, and noisy data. Experimental results demonstrate that our method effectively enhances the performance of LLMs in text classification tasks and significantly improves training efficiency, saving nearly half of the training time. Our method has achieved state-of-the-art performance in several open-source classification tasks.
MolMetaLM: a Physicochemical Knowledge-Guided Molecular Meta Language Model
Nov 23, 2024



Most current molecular language models transfer the masked language model or image-text generation model from natural language processing to molecular field. However, molecules are not solely characterized by atom/bond symbols; they encapsulate important physical/chemical properties. Moreover, normal language models bring grammar rules that are irrelevant for understanding molecules. In this study, we propose a novel physicochemical knowledge-guided molecular meta language framework MolMetaLM. We design a molecule-specialized meta language paradigm, formatted as multiple <S,P,O> (subject, predicate, object) knowledge triples sharing the same S (i.e., molecule) to enhance learning the semantic relationships between physicochemical knowledge and molecules. By introducing different molecular knowledge and noises, the meta language paradigm generates tens of thousands of pretraining tasks. By recovering the token/sequence/order-level noises, MolMetaLM exhibits proficiency in large-scale benchmark evaluations involving property prediction, molecule generation, conformation inference, and molecular optimization. Through MolMetaLM, we offer a new insight for designing language models.
MoChat: Joints-Grouped Spatio-Temporal Grounding LLM for Multi-Turn Motion Comprehension and Description
Oct 15, 2024



Despite continuous advancements in deep learning for understanding human motion, existing models often struggle to accurately identify action timing and specific body parts, typically supporting only single-round interaction. Such limitations in capturing fine-grained motion details reduce their effectiveness in motion understanding tasks. In this paper, we propose MoChat, a multimodal large language model capable of spatio-temporal grounding of human motion and understanding multi-turn dialogue context. To achieve these capabilities, we group the spatial information of each skeleton frame based on human anatomical structure and then apply them with Joints-Grouped Skeleton Encoder, whose outputs are combined with LLM embeddings to create spatio-aware and temporal-aware embeddings separately. Additionally, we develop a pipeline for extracting timestamps from skeleton sequences based on textual annotations, and construct multi-turn dialogues for spatially grounding. Finally, various task instructions are generated for jointly training. Experimental results demonstrate that MoChat achieves state-of-the-art performance across multiple metrics in motion understanding tasks, making it as the first model capable of fine-grained spatio-temporal grounding of human motion.