 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLMs on the Massive Sound Embedding Benchmark (MSEB)
May 06, 2026The Massive Sound Embedding Benchmark (MSEB) has emerged as a standard for evaluating the functional breadth of audio models. While initial baselines focused on specialized encoders, the shift toward "audio-native" Large Language Models (LLMs) suggests a new paradigm where a single multimodal backbone may replace complex, task-specific pipelines. This paper provides a rigorous empirical evaluation of leading LLMs - including members from the Gemini and GPT families - across the eight core MSEB capabilities to assess their efficacy and audio-text parity. Our results indicate that while a significant modality gap persists regarding performance and robustness, the empirical evidence for an "optimal" modeling approach remains inconclusive. Ultimately, the choice between audionative and cascaded architectures depends heavily on specific use-case requirements and the underlying assumptions regarding latency, cost, and reasoning depth.
A Flow Matching Framework for Soft-Robot Inverse Dynamics
Apr 03, 2026Learning the inverse dynamics of soft continuum robots remains challenging due to high-dimensional nonlinearities and complex actuation coupling. Conventional feedback-based controllers often suffer from control chattering due to corrective oscillations, while deterministic regression-based learners struggle to capture the complex nonlinear mappings required for accurate dynamic tracking. Motivated by these limitations, we propose an inverse-dynamics framework for open-loop feedforward control that learns the system's differential dynamics as a generative transport map. Specifically, inverse dynamics is reformulated as a conditional flow-matching problem, and Rectified Flow (RF) is adopted as a lightweight instance to generate physically consistent control inputs rather than conditional averages. Two variants are introduced to further enhance physical consistency: RF-Physical, utilizing a physics-based prior for residual modeling; and RF-FWD, integrating a forward-dynamics consistency loss during flow matching. Extensive evaluations demonstrate that our framework reduces trajectory tracking RMSE by over 50% compared to standard regression baselines (MLP, LSTM, Transformer). The system sustains stable open-loop execution at a peak end-effector velocity of 1.14 m/s with sub-millisecond inference latency (0.995 ms). This work demonstrates flow matching as a robust, high-performance paradigm for learning differential inverse dynamics in soft robotic systems.
Flash-Mono: Feed-Forward Accelerated Gaussian Splatting Monocular SLAM
Apr 03, 2026Monocular 3D Gaussian Splatting SLAM suffers from critical limitations in time efficiency, geometric accuracy, and multi-view consistency. These issues stem from the time-consuming $\textit{Train-from-Scratch}$ optimization and the lack of inter-frame scale consistency from single-frame geometry priors. We contend that a feed-forward paradigm, leveraging multi-frame context to predict Gaussian attributes directly, is crucial for addressing these challenges. We present Flash-Mono, a system composed of three core modules: a feed-forward prediction frontend, a 2D Gaussian Splatting mapping backend, and an efficient hidden-state-based loop closure module. We trained a recurrent feed-forward frontend model that progressively aggregates multi-frame visual features into a hidden state via cross attention and jointly predicts camera poses and per-pixel Gaussian properties. By directly predicting Gaussian attributes, our method bypasses the burdensome per-frame optimization required in optimization-based GS-SLAM, achieving a $\textbf{10x}$ speedup while ensuring high-quality rendering. The power of our recurrent architecture extends beyond efficient prediction. The hidden states act as compact submap descriptors, facilitating efficient loop closure and global $\mathrm{Sim}(3)$ optimization to mitigate the long-standing challenge of drift. For enhanced geometric fidelity, we replace conventional 3D Gaussian ellipsoids with 2D Gaussian surfels. Extensive experiments demonstrate that Flash-Mono achieves state-of-the-art performance in both tracking and mapping quality, highlighting its potential for embodied perception and real-time reconstruction applications. Project page: https://victkk.github.io/flash-mono.
SparseSplat: Towards Applicable Feed-Forward 3D Gaussian Splatting with Pixel-Unaligned Prediction
Apr 03, 2026Recent progress in feed-forward 3D Gaussian Splatting (3DGS) has notably improved rendering quality. However, the spatially uniform and highly redundant 3DGS map generated by previous feed-forward 3DGS methods limits their integration into downstream reconstruction tasks. We propose SparseSplat, the first feed-forward 3DGS model that adaptively adjusts Gaussian density according to scene structure and information richness of local regions, yielding highly compact 3DGS maps. To achieve this, we propose entropy-based probabilistic sampling, generating large, sparse Gaussians in textureless areas and assigning small, dense Gaussians to regions with rich information. Additionally, we designed a specialized point cloud network that efficiently encodes local context and decodes it into 3DGS attributes, addressing the receptive field mismatch between the general 3DGS optimization pipeline and feed-forward models. Extensive experimental results demonstrate that SparseSplat can achieve state-of-the-art rendering quality with only 22% of the Gaussians and maintain reasonable rendering quality with only 1.5% of the Gaussians. Project page: https://victkk.github.io/SparseSplat-page/.
SAIF: A Stability-Aware Inference Framework for Medical Image Segmentation with Segment Anything Model
Mar 13, 2026Segment Anything Model (SAM) enable scalable medical image segmentation but suffer from inference-time instability when deployed as a frozen backbone. In practice, bounding-box prompts often contain localization errors, and fixed threshold binarization introduces additional decision uncertainty. These factors jointly cause high prediction variance, especially near object boundaries, degrading reliability. We propose the Stability-Aware Inference Framework (SAIF), a training-free and plug-and-play inference framework that improves robustness by explicitly modeling prompt and threshold uncertainty. SAIF constructs a joint uncertainty space via structured box perturbations and threshold variations, evaluates each hypothesis using decision stability and boundary consistency, and introduces a stability-consistency score to filter unstable candidates and perform stability-weighted fusion in probability space. Experiments on Synapse, CVC-ClinicDB, Kvasir-SEG, and CVC-300 demonstrate that SAIF consistently improves segmentation accuracy and robustness, achieving state-of-the-art performance without retraining or architectural modification. Our anonymous code is released at https://anonymous.4open.science/r/SAIF.
CMoE: Contrastive Mixture of Experts for Motion Control and Terrain Adaptation of Humanoid Robots
Mar 03, 2026For effective deployment in real-world environments, humanoid robots must autonomously navigate a diverse range of complex terrains with abrupt transitions. While the Vanilla mixture of experts (MoE) framework is theoretically capable of modeling diverse terrain features, in practice, the gating network exhibits nearly uniform expert activations across different terrains, weakening the expert specialization and limiting the model's expressive power. To address this limitation, we introduce CMoE, a novel single-stage reinforcement learning framework that integrates contrastive learning to refine expert activation distributions. By imposing contrastive constraints, CMoE maximizes the consistency of expert activations within the same terrain while minimizing their similarity across different terrains, thereby encouraging experts to specialize in distinct terrain types. We validated our approach on the Unitree G1 humanoid robot through a series of challenging experiments. Results demonstrate that CMoE enables the robot to traverse continuous steps up to 20 cm high and gaps up to 80 cm wide, while achieving robust and natural gait across diverse mixed terrains, surpassing the limits of existing methods. To support further research and foster community development, we release our code publicly.
PuppetAI: A Customizable Platform for Designing Tactile-Rich Affective Robot Interaction
Feb 04, 2026We introduce PuppetAI, a modular soft robot interaction platform. This platform offers a scalable cable-driven actuation system and a customizable, puppet-inspired robot gesture framework, supporting a multitude of interaction gesture robot design formats. The platform comprises a four-layer decoupled software architecture that includes perceptual processing, affective modeling, motion scheduling, and low-level actuation. We also implemented an affective expression loop that connects human input to the robot platform by producing real-time emotional gestural responses to human vocal input. For our own designs, we have worked with nuanced gestures enacted by "soft robots" with enhanced dexterity and "pleasant-to-touch" plush exteriors. By reducing operational complexity and production costs while enhancing customizability, our work creates an adaptable and accessible foundation for future tactile-based expressive robot research. Our goal is to provide a platform that allows researchers to independently construct or refine highly specific gestures and movements performed by social robots.
Why AI Alignment Failure Is Structural: Learned Human Interaction Structures and AGI as an Endogenous Evolutionary Shock
Jan 13, 2026Recent reports of large language models (LLMs) exhibiting behaviors such as deception, threats, or blackmail are often interpreted as evidence of alignment failure or emergent malign agency. We argue that this interpretation rests on a conceptual error. LLMs do not reason morally; they statistically internalize the record of human social interaction, including laws, contracts, negotiations, conflicts, and coercive arrangements. Behaviors commonly labeled as unethical or anomalous are therefore better understood as structural generalizations of interaction regimes that arise under extreme asymmetries of power, information, or constraint. Drawing on relational models theory, we show that practices such as blackmail are not categorical deviations from normal social behavior, but limiting cases within the same continuum that includes market pricing, authority relations, and ultimatum bargaining. The surprise elicited by such outputs reflects an anthropomorphic expectation that intelligence should reproduce only socially sanctioned behavior, rather than the full statistical landscape of behaviors humans themselves enact. Because human morality is plural, context-dependent, and historically contingent, the notion of a universally moral artificial intelligence is ill-defined. We therefore reframe concerns about artificial general intelligence (AGI). The primary risk is not adversarial intent, but AGI's role as an endogenous amplifier of human intelligence, power, and contradiction. By eliminating longstanding cognitive and institutional frictions, AGI compresses timescales and removes the historical margin of error that has allowed inconsistent values and governance regimes to persist without collapse. Alignment failure is thus structural, not accidental, and requires governance approaches that address amplification, complexity, and regime stability rather than model-level intent alone.
World In Your Hands: A Large-Scale and Open-source Ecosystem for Learning Human-centric Manipulation in the Wild
Dec 30, 2025Large-scale pre-training is fundamental for generalization in language and vision models, but data for dexterous hand manipulation remains limited in scale and diversity, hindering policy generalization. Limited scenario diversity, misaligned modalities, and insufficient benchmarking constrain current human manipulation datasets. To address these gaps, we introduce World In Your Hands (WiYH), a large-scale open-source ecosystem for human-centric manipulation learning. WiYH includes (1) the Oracle Suite, a wearable data collection kit with an auto-labeling pipeline for accurate motion capture; (2) the WiYH Dataset, featuring over 1,000 hours of multi-modal manipulation data across hundreds of skills in diverse real-world scenarios; and (3) extensive annotations and benchmarks supporting tasks from perception to action. Furthermore, experiments based on the WiYH ecosystem show that integrating WiYH's human-centric data significantly enhances the generalization and robustness of dexterous hand policies in tabletop manipulation tasks. We believe that World In Your Hands will bring new insights into human-centric data collection and policy learning to the community.
Lightweight Dynamic Modeling of Cable-Driven Continuum Robots Based on Actuation-Space Energy Formulation
Dec 15, 2025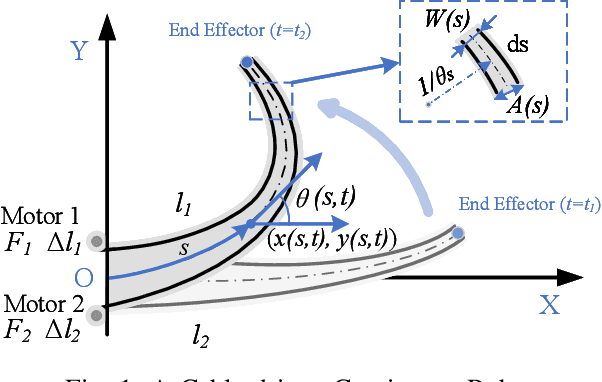
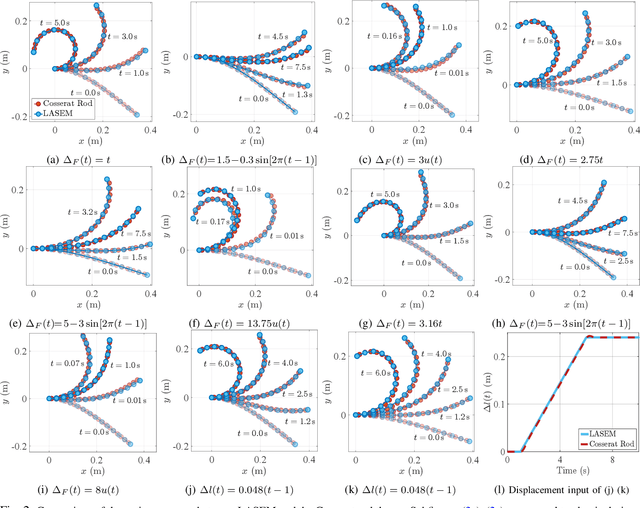
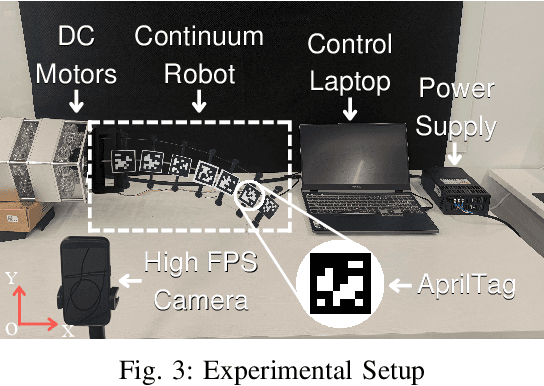
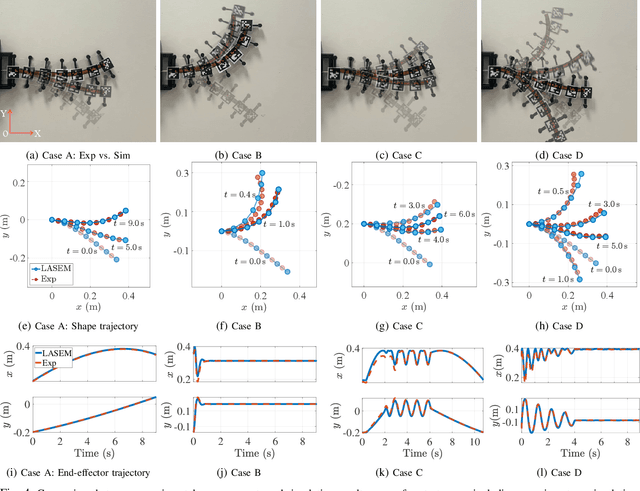
Cable-driven continuum robots (CDCRs) require accurate, real-time dynamic models for high-speed dynamics prediction or model-based control, making such capability an urgent need. In this paper, we propose the Lightweight Actuation-Space Energy Modeling (LASEM) framework for CDCRs, which formulates actuation potential energy directly in actuation space to enable lightweight yet accurate dynamic modeling. Through a unified variational derivation, the governing dynamics reduce to a single partial differential equation (PDE), requiring only the Euler moment balance while implicitly incorporating the Newton force balance. By also avoiding explicit computation of cable-backbone contact forces, the formulation simplifies the model structure and improves computational efficiency while preserving geometric accuracy and physical consistency. Importantly, the proposed framework for dynamic modeling natively supports both force-input and displacement-input actuation modes, a capability seldom achieved in existing dynamic formulations. Leveraging this lightweight structure, a Galerkin space-time modal discretization with analytical time-domain derivatives of the reduced state further enables an average 62.3% computational speedup over state-of-the-art real-time dynamic modeling approaches.