 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2Q-DETR: Decoupling and Dynamic Queries for Oriented Object Detection with Transformers
Mar 01, 2023Despite the promising results, existing oriented object detection methods usually involve heuristically designed rules, e.g., RRoI generation, rotated NMS. In this paper, we propose an end-to-end framework for oriented object detection, which simplifies the model pipeline and obtains superior performance. Our framework is based on DETR, with the box regression head replaced with a points prediction head. The learning of points is more flexible, and the distribution of points can reflect the angle and size of the target rotated box. We further propose to decouple the query features into classification and regression features, which significantly improves the model precision. Aerial images usually contain thousands of instances. To better balance model precision and efficiency, we propose a novel dynamic query design, which reduces the number of object queries in stacked decoder layers without sacrificing model performance. Finally, we rethink the label assignment strategy of existing DETR-like detectors and propose an effective label re-assignment strategy for improved performance. We name our method D2Q-DETR. Experiments on the largest and challenging DOTA-v1.0 and DOTA-v1.5 datasets show that D2Q-DETR outperforms existing NMS-based and NMS-free oriented object detection methods and achieves the new state-of-the-art.
* 5 figures
Foundation Model Drives Weakly Incremental Learning for Semantic Segmentation
Feb 28, 2023



Modern incremental learning for semantic segmentation methods usually learn new categories based on dense annotations. Although achieve promising results, pixel-by-pixel labeling is costly and time-consuming. Weakly incremental learning for semantic segmentation (WILSS) is a novel and attractive task, which aims at learning to segment new classes from cheap and widely available image-level labels. Despite the comparable results, the image-level labels can not provide details to locate each segment, which limits the performance of WILSS. This inspires us to think how to improve and effectively utilize the supervision of new classes given image-level labels while avoiding forgetting old ones. In this work, we propose a novel and data-efficient framework for WILSS, named FMWISS. Specifically, we propose pre-training based co-segmentation to distill the knowledge of complementary foundation models for generating dense pseudo labels. We further optimize the noisy pseudo masks with a teacher-student architecture, where a plug-in teacher is optimized with a proposed dense contrastive loss. Moreover, we introduce memory-based copy-paste augmentation to improve the catastrophic forgetting problem of old classes. Extensive experiments on Pascal VOC and COCO datasets demonstrate the superior performance of our framework, e.g., FMWISS achieves 70.7% and 73.3% in the 15-5 VOC setting, outperforming the state-of-the-art method by 3.4% and 6.1%, respectively.
LMSeg: Language-guided Multi-dataset Segmentation
Feb 27, 2023



It's a meaningful and attractive topic to build a general and inclusive segmentation model that can recognize more categories in various scenarios. A straightforward way is to combine the existing fragmented segmentation datasets and train a multi-dataset network. However, there are two major issues with multi-dataset segmentation: (1) the inconsistent taxonomy demands manual reconciliation to construct a unified taxonomy; (2) the inflexible one-hot common taxonomy causes time-consuming model retraining and defective supervision of unlabeled categories. In this paper, we investigate the multi-dataset segmentation and propose a scalable Language-guided Multi-dataset Segmentation framework, dubbed LMSeg, which supports both semantic and panoptic segmentation. Specifically, we introduce a pre-trained text encoder to map the category names to a text embedding space as a unified taxonomy, instead of using inflexible one-hot label. The model dynamically aligns the segment queries with the category embeddings. Instead of relabeling each dataset with the unified taxonomy, a category-guided decoding module is designed to dynamically guide predictions to each datasets taxonomy. Furthermore, we adopt a dataset-aware augmentation strategy that assigns each dataset a specific image augmentation pipeline, which can suit the properties of images from different datasets. Extensive experiments demonstrate that our method achieves significant improvements on four semantic and three panoptic segmentation datasets, and the ablation study evaluates the effectiveness of each component.
MimCo: Masked Image Modeling Pre-training with Contrastive Teacher
Sep 07, 2022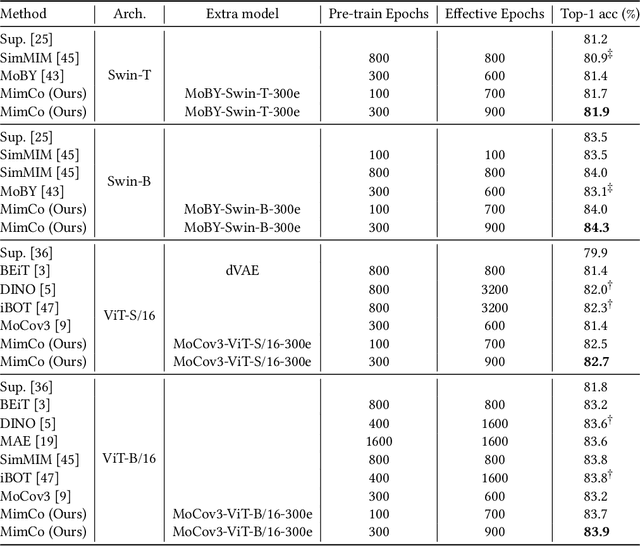
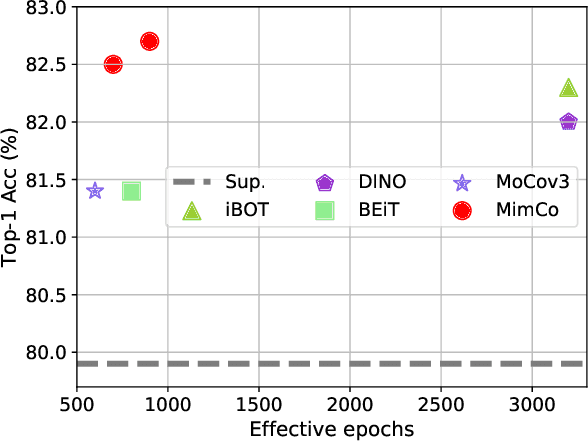
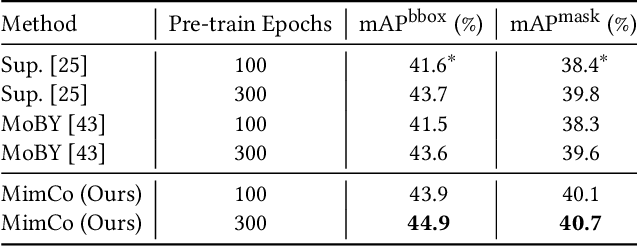
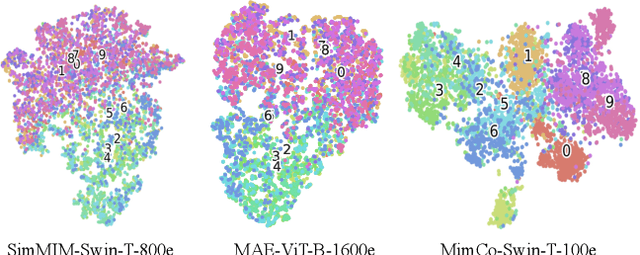
Recent masked image modeling (MIM) has received much attention in self-supervised learning (SSL), which requires the target model to recover the masked part of the input image. Although MIM-based pre-training methods achieve new state-of-the-art performance when transferred to many downstream tasks, the visualizations show that the learned representations are less separable, especially compared to those based on contrastive learning pre-training. This inspires us to think whether the linear separability of MIM pre-trained representation can be further improved, thereby improving the pre-training performance. Since MIM and contrastive learning tend to utilize different data augmentations and training strategies, combining these two pretext tasks is not trivial. In this work, we propose a novel and flexible pre-training framework, named MimCo, which combines MIM and contrastive learning through two-stage pre-training. Specifically, MimCo takes a pre-trained contrastive learning model as the teacher model and is pre-trained with two types of learning targets: patch-level and image-level reconstruction losses. Extensive transfer experiments on downstream tasks demonstrate the superior performance of our MimCo pre-training framework. Taking ViT-S as an example, when using the pre-trained MoCov3-ViT-S as the teacher model, MimCo only needs 100 epochs of pre-training to achieve 82.53% top-1 finetuning accuracy on Imagenet-1K, which outperforms the state-of-the-art self-supervised learning counterparts.
Point RCNN: An Angle-Free Framework for Rotated Object Detection
Jun 08, 2022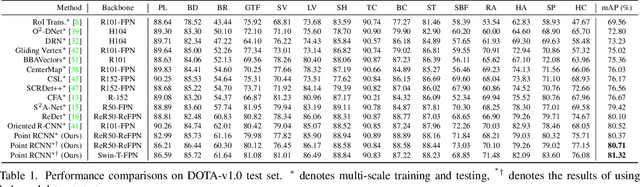
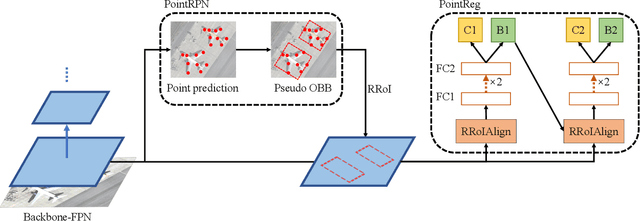
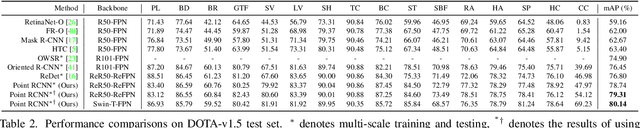
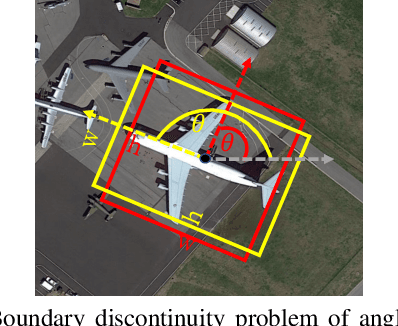
Rotated object detection in aerial images is still challenging due to arbitrary orientations, large scale and aspect ratio variations, and extreme density of objects. Existing state-of-the-art rotated object detection methods mainly rely on angle-based detectors. However, angle regression can easily suffer from the long-standing boundary problem. To tackle this problem, we propose a purely angle-free framework for rotated object detection, called Point RCNN, which mainly consists of PointRPN and PointReg. In particular, PointRPN generates accurate rotated RoIs (RRoIs) by converting the learned representative points with a coarse-to-fine manner, which is motivated by RepPoints. Based on the learned RRoIs, PointReg performs corner points refinement for more accurate detection. In addition, aerial images are often severely unbalanced in categories, and existing methods almost ignore this issue. In this paper, we also experimentally verify that re-sampling the images of the rare categories will stabilize training and further improve the detection performance. Experiments demonstrate that our Point RCNN achieves the new state-of-the-art detection performance on commonly used aerial datasets, including DOTA-v1.0, DOTA-v1.5, and HRSC2016.
Point-Teaching: Weakly Semi-Supervised Object Detection with Point Annotations
Jun 01, 2022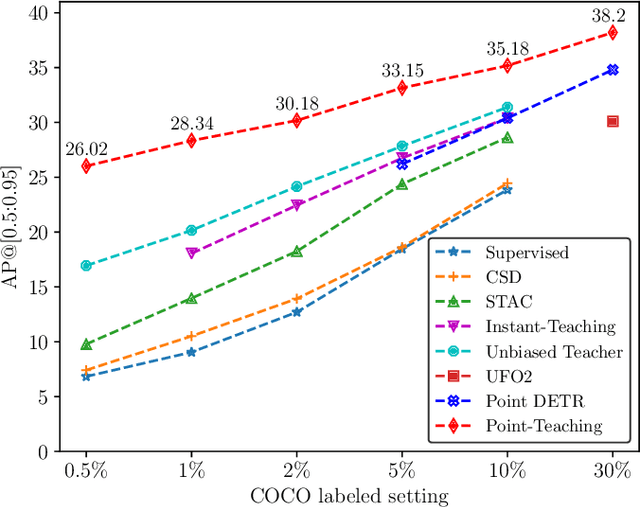
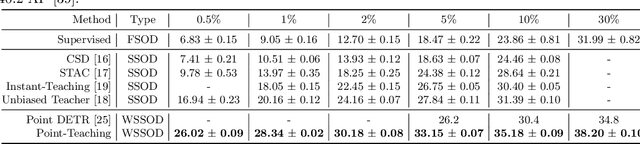
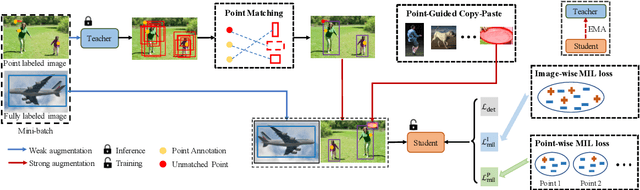

Point annotations are considerably more time-efficient than bounding box annotations. However, how to use cheap point annotations to boost the performance of semi-supervised object detection remains largely unsolved. In this work, we present Point-Teaching, a weakly semi-supervised object detection framework to fully exploit the point annotations. Specifically, we propose a Hungarian-based point matching method to generate pseudo labels for point annotated images. We further propose multiple instance learning (MIL) approaches at the level of images and points to supervise the object detector with point annotations. Finally, we propose a simple-yet-effective data augmentation, termed point-guided copy-paste, to reduce the impact of the unmatched points. Experiments demonstrate the effectiveness of our method on a few datasets and various data regimes.
UnrealNAS: Can We Search Neural Architectures with Unreal Data?
May 19, 2022
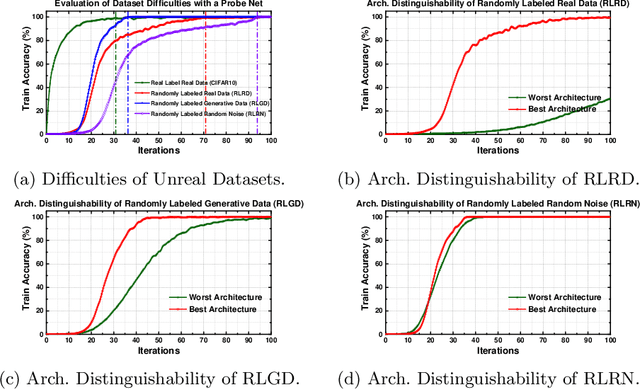
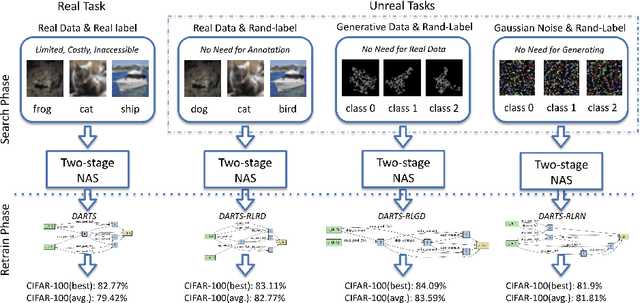
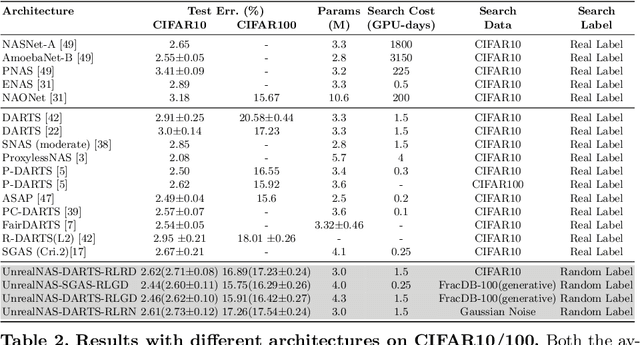
Neural architecture search (NAS) has shown great success in the automatic design of deep neural networks (DNNs). However, the best way to use data to search network architectures is still unclear and under exploration. Previous work has analyzed the necessity of having ground-truth labels in NAS and inspired broad interest. In this work, we take a further step to question whether real data is necessary for NAS to be effective. The answer to this question is important for applications with limited amount of accessible data, and can help people improve NAS by leveraging the extra flexibility of data generation. To explore if NAS needs real data, we construct three types of unreal datasets using: 1) randomly labeled real images; 2) generated images and labels; and 3) generated Gaussian noise with random labels. These datasets facilitate to analyze the generalization and expressivity of the searched architectures. We study the performance of architectures searched on these constructed datasets using popular differentiable NAS methods. Extensive experiments on CIFAR, ImageNet and CheXpert show that the searched architectures can achieve promising results compared with those derived from the conventional NAS pipeline with real labeled data, suggesting the feasibility of performing NAS with unreal data.
Fix Bugs with Transformer through a Neural-Symbolic Edit Grammar
Apr 13, 2022

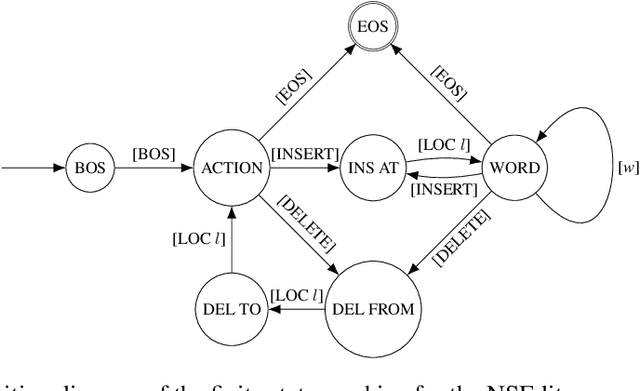
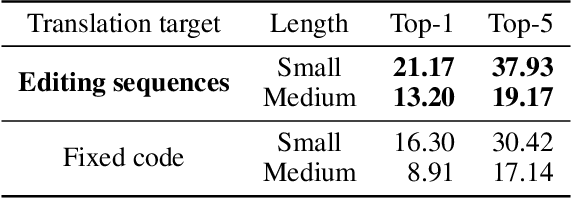
We introduce NSEdit (neural-symbolic edit), a novel Transformer-based code repair method. Given only the source code that contains bugs, NSEdit predicts an editing sequence that can fix the bugs. The edit grammar is formulated as a regular language, and the Transformer uses it as a neural-symbolic scripting interface to generate editing programs. We modify the Transformer and add a pointer network to select the edit locations. An ensemble of rerankers are trained to re-rank the editing sequences generated by beam search. We fine-tune the rerankers on the validation set to reduce over-fitting. NSEdit is evaluated on various code repair datasets and achieved a new state-of-the-art accuracy ($24.04\%$) on the Tufano small dataset of the CodeXGLUE benchmark. NSEdit performs robustly when programs vary from packages to packages and when buggy programs are concrete. We conduct detailed analysis on our methods and demonstrate the effectiveness of each component.
GAMMA Challenge:Glaucoma grAding from Multi-Modality imAges
Feb 16, 2022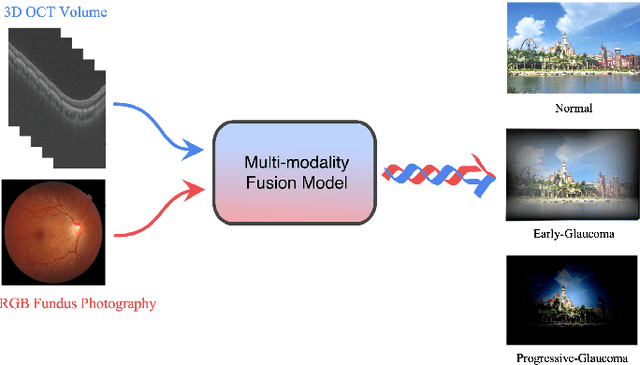
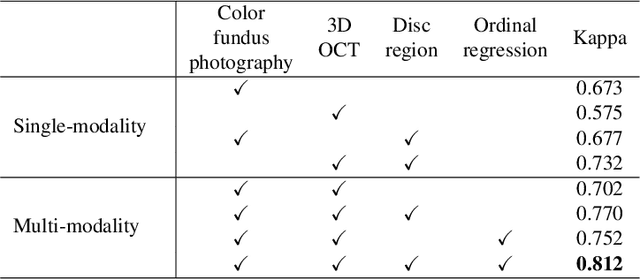
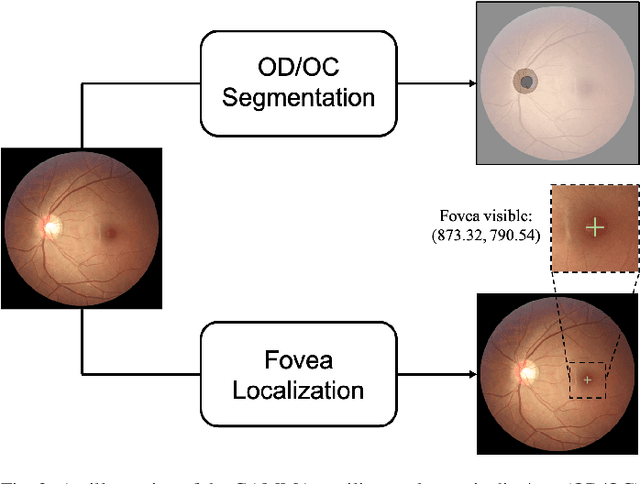
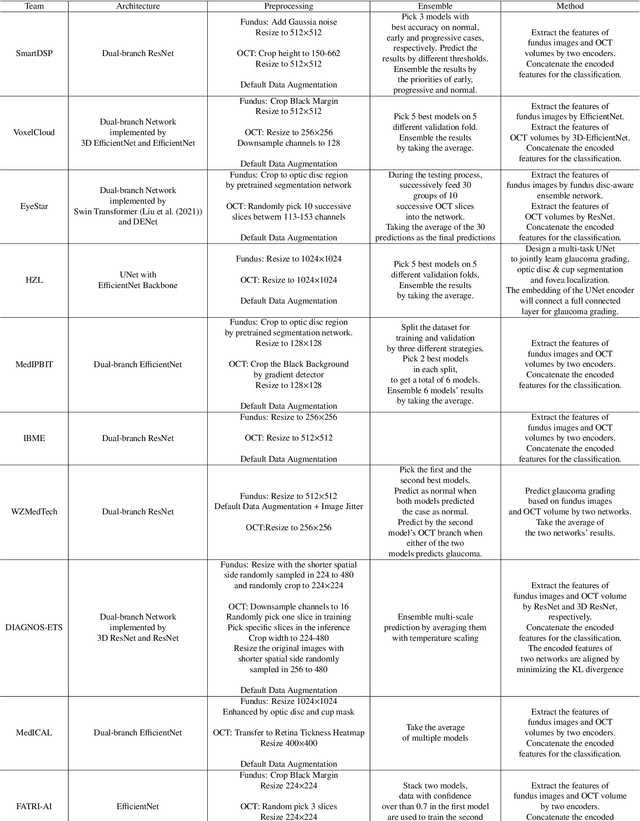
Color fundus photography and Optical Coherence Tomography (OCT) are the two most cost-effective tools for glaucoma screening. Both two modalities of images have prominent biomarkers to indicate glaucoma suspected. Clinically, it is often recommended to take both of the screenings for a more accurate and reliable diagnosis. However, although numerous algorithms are proposed based on fundus images or OCT volumes in computer-aided diagnosis, there are still few methods leveraging both of the modalities for the glaucoma assessment. Inspired by the success of Retinal Fundus Glaucoma Challenge (REFUGE) we held previously, we set up the Glaucoma grAding from Multi-Modality imAges (GAMMA) Challenge to encourage the development of fundus \& OCT-based glaucoma grading. The primary task of the challenge is to grade glaucoma from both the 2D fundus images and 3D OCT scanning volumes. As part of GAMMA, we have publicly released a glaucoma annotated dataset with both 2D fundus color photography and 3D OCT volumes, which is the first multi-modality dataset for glaucoma grading. In addition, an evaluation framework is also established to evaluate the performance of the submitted methods. During the challenge, 1272 results were submitted, and finally, top-10 teams were selected to the final stage. We analysis their results and summarize their methods in the paper. Since all these teams submitted their source code in the challenge, a detailed ablation study is also conducted to verify the effectiveness of the particular modules proposed. We find many of the proposed techniques are practical for the clinical diagnosis of glaucoma. As the first in-depth study of fundus \& OCT multi-modality glaucoma grading, we believe the GAMMA Challenge will be an essential starting point for future research.
LUAI Challenge 2021 on Learning to Understand Aerial Images
Aug 30, 2021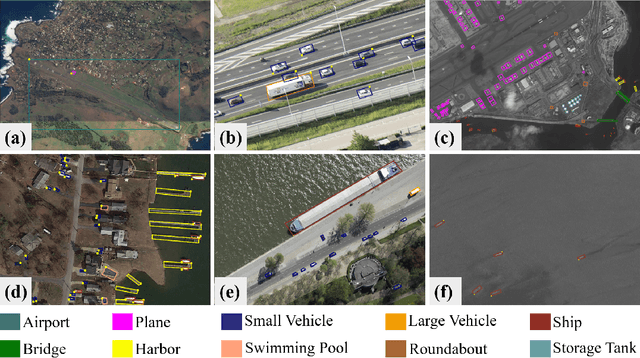

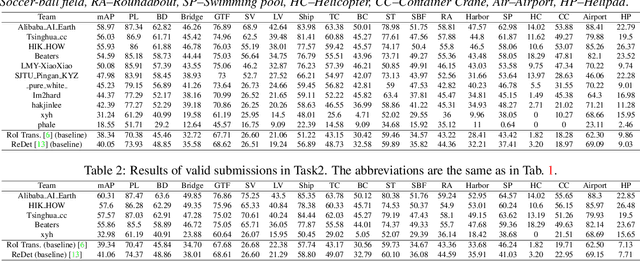
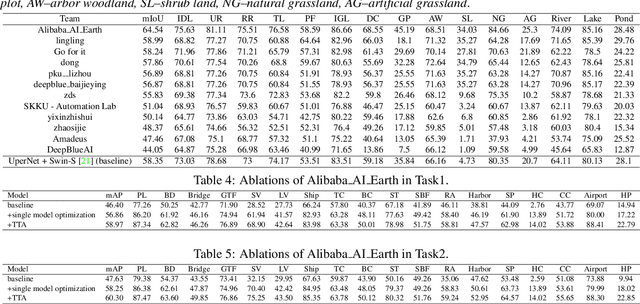
This report summarizes the results of Learning to Understand Aerial Images (LUAI) 2021 challenge held on ICCV 2021, which focuses on object detection and semantic segmentation in aerial images. Using DOTA-v2.0 and GID-15 datasets, this challenge proposes three tasks for oriented object detection, horizontal object detection, and semantic segmentation of common categories in aerial images. This challenge received a total of 146 registrations on the three tasks. Through the challenge, we hope to draw attention from a wide range of communities and call for more efforts on the problems of learning to understand aerial images.