 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldMark: A Unified Benchmark Suite for Interactive Video World Models
Apr 23, 2026Interactive video generation models such as Genie, YUME, HY-World, and Matrix-Game are advancing rapidly, yet every model is evaluated on its own benchmark with private scenes and trajectories, making fair cross-model comparison impossible. Existing public benchmarks offer useful metrics such as trajectory error, aesthetic scores, and VLM-based judgments, but none supplies the standardized test conditions -- identical scenes, identical action sequences, and a unified control interface -- needed to make those metrics comparable across models with heterogeneous inputs. We introduce WorldMark, the first benchmark that provides such a common playing field for interactive Image-to-Video world models. WorldMark contributes: (1) a unified action-mapping layer that translates a shared WASD-style action vocabulary into each model's native control format, enabling apples-to-apples comparison across six major models on identical scenes and trajectories; (2) a hierarchical test suite of 500 evaluation cases covering first- and third-person viewpoints, photorealistic and stylized scenes, and three difficulty tiers from Easy to Hard spanning 20-60s; and (3) a modular evaluation toolkit for Visual Quality, Control Alignment, and World Consistency, designed so that researchers can reuse our standardized inputs while plugging in their own metrics as the field evolves. We will release all data, evaluation code, and model outputs to facilitate future research. Beyond offline metrics, we launch World Model Arena (warena.ai), an online platform where anyone can pit leading world models against each other in side-by-side battles and watch the live leaderboard.
Generative Video Matting
Aug 11, 2025Video matting has traditionally been limited by the lack of high-quality ground-truth data. Most existing video matting datasets provide only human-annotated imperfect alpha and foreground annotations, which must be composited to background images or videos during the training stage. Thus, the generalization capability of previous methods in real-world scenarios is typically poor. In this work, we propose to solve the problem from two perspectives. First, we emphasize the importance of large-scale pre-training by pursuing diverse synthetic and pseudo-labeled segmentation datasets. We also develop a scalable synthetic data generation pipeline that can render diverse human bodies and fine-grained hairs, yielding around 200 video clips with a 3-second duration for fine-tuning. Second, we introduce a novel video matting approach that can effectively leverage the rich priors from pre-trained video diffusion models. This architecture offers two key advantages. First, strong priors play a critical role in bridging the domain gap between synthetic and real-world scenes. Second, unlike most existing methods that process video matting frame-by-frame and use an independent decoder to aggregate temporal information, our model is inherently designed for video, ensuring strong temporal consistency. We provide a comprehensive quantitative evaluation across three benchmark datasets, demonstrating our approach's superior performance, and present comprehensive qualitative results in diverse real-world scenes, illustrating the strong generalization capability of our method. The code is available at https://github.com/aim-uofa/GVM.
POMATO: Marrying Pointmap Matching with Temporal Motion for Dynamic 3D Reconstruction
Apr 08, 20253D reconstruction in dynamic scenes primarily relies on the combination of geometry estimation and matching modules where the latter task is pivotal for distinguishing dynamic regions which can help to mitigate the interference introduced by camera and object motion. Furthermore, the matching module explicitly models object motion, enabling the tracking of specific targets and advancing motion understanding in complex scenarios. Recently, the proposed representation of pointmap in DUSt3R suggests a potential solution to unify both geometry estimation and matching in 3D space, but it still struggles with ambiguous matching in dynamic regions, which may hamper further improvement. In this work, we present POMATO, a unified framework for dynamic 3D reconstruction by marrying pointmap matching with temporal motion. Specifically, our method first learns an explicit matching relationship by mapping RGB pixels from both dynamic and static regions across different views to 3D pointmaps within a unified coordinate system. Furthermore, we introduce a temporal motion module for dynamic motions that ensures scale consistency across different frames and enhances performance in tasks requiring both precise geometry and reliable matching, most notably 3D point tracking. We show the effectiveness of the proposed pointmap matching and temporal fusion paradigm by demonstrating the remarkable performance across multiple downstream tasks, including video depth estimation, 3D point tracking, and pose estimation. Code and models are publicly available at https://github.com/wyddmw/POMATO.
GeoBench: Benchmarking and Analyzing Monocular Geometry Estimation Models
Jun 18, 2024



Recent advances in discriminative and generative pretraining have yielded geometry estimation models with strong generalization capabilities. While discriminative monocular geometry estimation methods rely on large-scale fine-tuning data to achieve zero-shot generalization, several generative-based paradigms show the potential of achieving impressive generalization performance on unseen scenes by leveraging pre-trained diffusion models and fine-tuning on even a small scale of synthetic training data. Frustratingly, these models are trained with different recipes on different datasets, making it hard to find out the critical factors that determine the evaluation performance. Besides, current geometry evaluation benchmarks have two main drawbacks that may prevent the development of the field, i.e., limited scene diversity and unfavorable label quality. To resolve the above issues, (1) we build fair and strong baselines in a unified codebase for evaluating and analyzing the geometry estimation models; (2) we evaluate monocular geometry estimators on more challenging benchmarks for geometry estimation task with diverse scenes and high-quality annotations. Our results reveal that pre-trained using large data, discriminative models such as DINOv2, can outperform generative counterparts with a small amount of high-quality synthetic data under the same training configuration, which suggests that fine-tuning data quality is a more important factor than the data scale and model architecture. Our observation also raises a question: if simply fine-tuning a general vision model such as DINOv2 using a small amount of synthetic depth data produces SOTA results, do we really need complex generative models for depth estimation? We believe this work can propel advancements in geometry estimation tasks as well as a wide range of downstream applications.
3D Human Reconstruction in the Wild with Synthetic Data Using Generative Models
Mar 17, 2024In this work, we show that synthetic data created by generative models is complementary to computer graphics (CG) rendered data for achieving remarkable generalization performance on diverse real-world scenes for 3D human pose and shape estimation (HPS). Specifically, we propose an effective approach based on recent diffusion models, termed HumanWild, which can effortlessly generate human images and corresponding 3D mesh annotations. We first collect a large-scale human-centric dataset with comprehensive annotations, e.g., text captions and surface normal images. Then, we train a customized ControlNet model upon this dataset to generate diverse human images and initial ground-truth labels. At the core of this step is that we can easily obtain numerous surface normal images from a 3D human parametric model, e.g., SMPL-X, by rendering the 3D mesh onto the image plane. As there exists inevitable noise in the initial labels, we then apply an off-the-shelf foundation segmentation model, i.e., SAM, to filter negative data samples. Our data generation pipeline is flexible and customizable to facilitate different real-world tasks, e.g., ego-centric scenes and perspective-distortion scenes. The generated dataset comprises 0.79M images with corresponding 3D annotations, covering versatile viewpoints, scenes, and human identities. We train various HPS regressors on top of the generated data and evaluate them on a wide range of benchmarks (3DPW, RICH, EgoBody, AGORA, SSP-3D) to verify the effectiveness of the generated data. By exclusively employing generative models, we generate large-scale in-the-wild human images and high-quality annotations, eliminating the need for real-world data collection.
Diffusion Models Trained with Large Data Are Transferable Visual Models
Mar 15, 2024



We show that, simply initializing image understanding models using a pre-trained UNet (or transformer) of diffusion models, it is possible to achieve remarkable transferable performance on fundamental vision perception tasks using a moderate amount of target data (even synthetic data only), including monocular depth, surface normal, image segmentation, matting, human pose estimation, among virtually many others. Previous works have adapted diffusion models for various perception tasks, often reformulating these tasks as generation processes to align with the diffusion process. In sharp contrast, we demonstrate that fine-tuning these models with minimal adjustments can be a more effective alternative, offering the advantages of being embarrassingly simple and significantly faster. As the backbone network of Stable Diffusion models is trained on giant datasets comprising billions of images, we observe very robust generalization capabilities of the diffusion backbone. Experimental results showcase the remarkable transferability of the backbone of diffusion models across diverse tasks and real-world datasets.
Zolly: Zoom Focal Length Correctly for Perspective-Distorted Human Mesh Reconstruction
Mar 24, 2023



As it is hard to calibrate single-view RGB images in the wild, existing 3D human mesh reconstruction (3DHMR) methods either use a constant large focal length or estimate one based on the background environment context, which can not tackle the problem of the torso, limb, hand or face distortion caused by perspective camera projection when the camera is close to the human body. The naive focal length assumptions can harm this task with the incorrectly formulated projection matrices. To solve this, we propose Zolly, the first 3DHMR method focusing on perspective-distorted images. Our approach begins with analysing the reason for perspective distortion, which we find is mainly caused by the relative location of the human body to the camera center. We propose a new camera model and a novel 2D representation, termed distortion image, which describes the 2D dense distortion scale of the human body. We then estimate the distance from distortion scale features rather than environment context features. Afterwards, we integrate the distortion feature with image features to reconstruct the body mesh. To formulate the correct projection matrix and locate the human body position, we simultaneously use perspective and weak-perspective projection loss. Since existing datasets could not handle this task, we propose the first synthetic dataset PDHuman and extend two real-world datasets tailored for this task, all containing perspective-distorted human images. Extensive experiments show that Zolly outperforms existing state-of-the-art methods on both perspective-distorted datasets and the standard benchmark (3DPW).
Point-Teaching: Weakly Semi-Supervised Object Detection with Point Annotations
Jun 01, 2022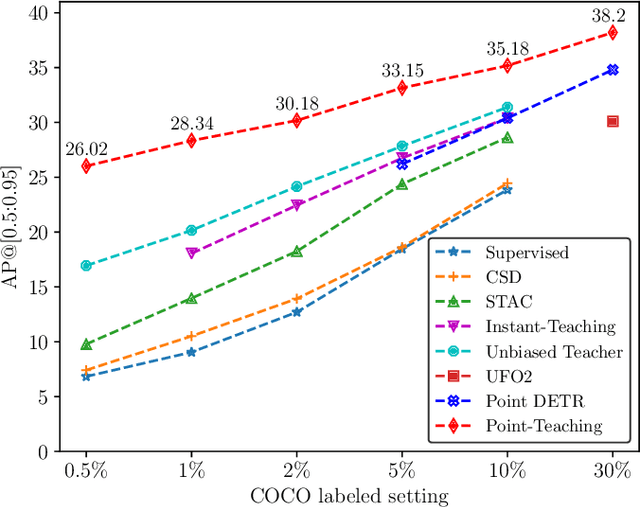
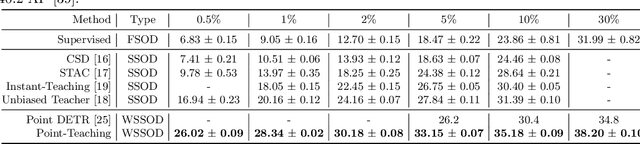
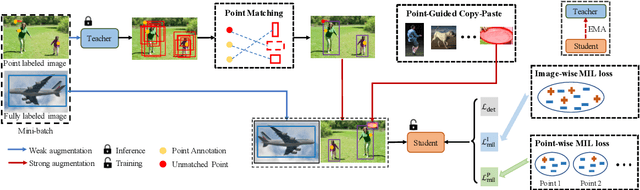

Point annotations are considerably more time-efficient than bounding box annotations. However, how to use cheap point annotations to boost the performance of semi-supervised object detection remains largely unsolved. In this work, we present Point-Teaching, a weakly semi-supervised object detection framework to fully exploit the point annotations. Specifically, we propose a Hungarian-based point matching method to generate pseudo labels for point annotated images. We further propose multiple instance learning (MIL) approaches at the level of images and points to supervise the object detector with point annotations. Finally, we propose a simple-yet-effective data augmentation, termed point-guided copy-paste, to reduce the impact of the unmatched points. Experiments demonstrate the effectiveness of our method on a few datasets and various data regimes.
Poseur: Direct Human Pose Regression with Transformers
Jan 19, 2022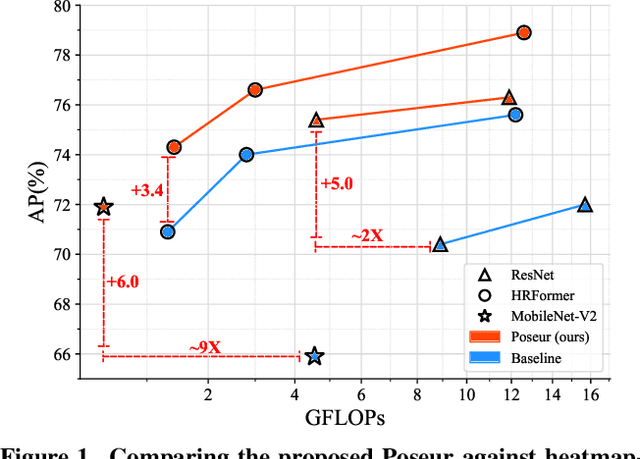
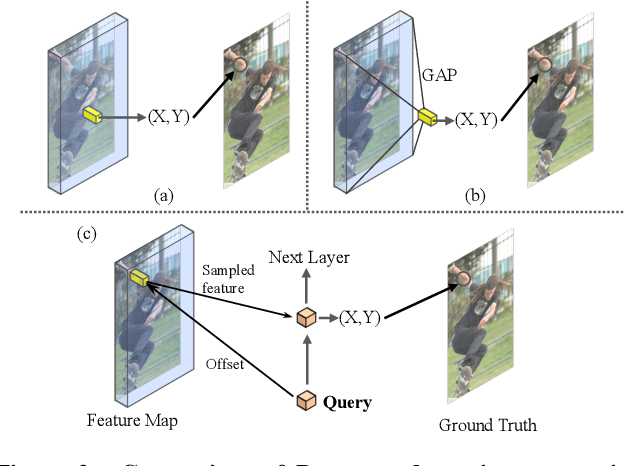

We propose a direct, regression-based approach to 2D human pose estimation from single images. We formulate the problem as a sequence prediction task, which we solve using a Transformer network. This network directly learns a regression mapping from images to the keypoint coordinates, without resorting to intermediate representations such as heatmaps. This approach avoids much of the complexity associated with heatmap-based approaches. To overcome the feature misalignment issues of previous regression-based methods, we propose an attention mechanism that adaptively attends to the features that are most relevant to the target keypoints, considerably improving the accuracy. Importantly, our framework is end-to-end differentiable, and naturally learns to exploit the dependencies between keypoints. Experiments on MS-COCO and MPII, two predominant pose-estimation datasets, demonstrate that our method significantly improves upon the state-of-the-art in regression-based pose estimation. More notably, ours is the first regression-based approach to perform favorably compared to the best heatmap-based pose estimation methods.
TFPose: Direct Human Pose Estimation with Transformers
Mar 29, 2021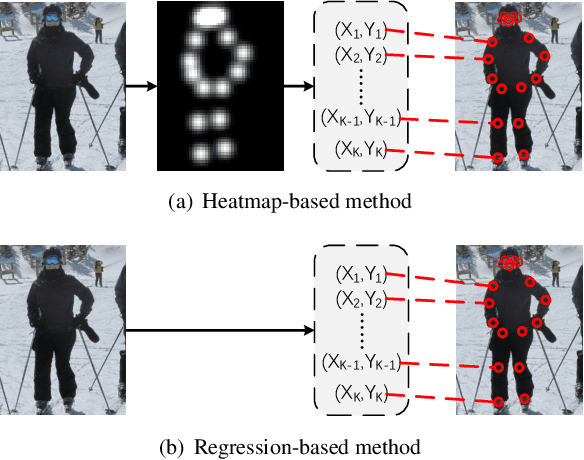

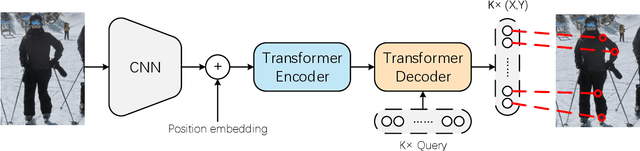
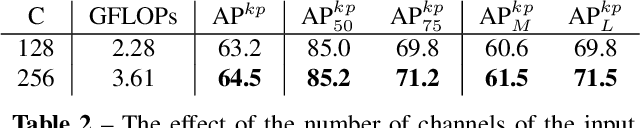
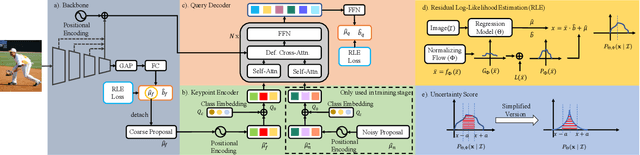
We propose a human pose estimation framework that solves the task in the regression-based fashion. Unlike previous regression-based methods, which often fall behind those state-of-the-art methods, we formulate the pose estimation task into a sequence prediction problem that can effectively be solved by transformers. Our framework is simple and direct, bypassing the drawbacks of the heatmap-based pose estimation. Moreover, with the attention mechanism in transformers, our proposed framework is able to adaptively attend to the features most relevant to the target keypoints, which largely overcomes the feature misalignment issue of previous regression-based methods and considerably improves the performance. Importantly, our framework can inherently take advantages of the structured relationship between keypoints. Experiments on the MS-COCO and MPII datasets demonstrate that our method can significantly improve the state-of-the-art of regression-based pose estimation and perform comparably with the best heatmap-based pose estimation methods.