 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
Next-Scale Prediction: A Self-Supervised Approach for Real-World Image Denoising
Dec 24, 2025Self-supervised real-world image denoising remains a fundamental challenge, arising from the antagonistic trade-off between decorrelating spatially structured noise and preserving high-frequency details. Existing blind-spot network (BSN) methods rely on pixel-shuffle downsampling (PD) to decorrelate noise, but aggressive downsampling fragments fine structures, while milder downsampling fails to remove correlated noise. To address this, we introduce Next-Scale Prediction (NSP), a novel self-supervised paradigm that decouples noise decorrelation from detail preservation. NSP constructs cross-scale training pairs, where BSN takes low-resolution, fully decorrelated sub-images as input to predict high-resolution targets that retain fine details. As a by-product, NSP naturally supports super-resolution of noisy images without retraining or modification. Extensive experiments demonstrate that NSP achieves state-of-the-art self-supervised denoising performance on real-world benchmarks, significantly alleviating the long-standing conflict between noise decorrelation and detail preservation.
LaverNet: Lightweight All-in-one Video Restoration via Selective Propagation
Dec 18, 2025



Recent studies have explored all-in-one video restoration, which handles multiple degradations with a unified model. However, these approaches still face two challenges when dealing with time-varying degradations. First, the degradation can dominate temporal modeling, confusing the model to focus on artifacts rather than the video content. Second, current methods typically rely on large models to handle all-in-one restoration, concealing those underlying difficulties. To address these challenges, we propose a lightweight all-in-one video restoration network, LaverNet, with only 362K parameters. To mitigate the impact of degradations on temporal modeling, we introduce a novel propagation mechanism that selectively transmits only degradation-agnostic features across frames. Through LaverNet, we demonstrate that strong all-in-one restoration can be achieved with a compact network. Despite its small size, less than 1\% of the parameters of existing models, LaverNet achieves comparable, even superior performance across benchmarks.
MaIR: A Locality- and Continuity-Preserving Mamba for Image Restoration
Dec 28, 2024



Recent advancements in Mamba have shown promising results in image restoration. These methods typically flatten 2D images into multiple distinct 1D sequences along rows and columns, process each sequence independently using selective scan operation, and recombine them to form the outputs. However, such a paradigm overlooks two vital aspects: i) the local relationships and spatial continuity inherent in natural images, and ii) the discrepancies among sequences unfolded through totally different ways. To overcome the drawbacks, we explore two problems in Mamba-based restoration methods: i) how to design a scanning strategy preserving both locality and continuity while facilitating restoration, and ii) how to aggregate the distinct sequences unfolded in totally different ways. To address these problems, we propose a novel Mamba-based Image Restoration model (MaIR), which consists of Nested S-shaped Scanning strategy (NSS) and Sequence Shuffle Attention block (SSA). Specifically, NSS preserves locality and continuity of the input images through the stripe-based scanning region and the S-shaped scanning path, respectively. SSA aggregates sequences through calculating attention weights within the corresponding channels of different sequences. Thanks to NSS and SSA, MaIR surpasses 40 baselines across 14 challenging datasets, achieving state-of-the-art performance on the tasks of image super-resolution, denoising, deblurring and dehazing. Our codes will be available after acceptance.
Exploiting Diffusion Priors for All-in-One Image Restoration
Dec 02, 2023



All-in-one aims to solve various tasks of image restoration in a single model. To this end, we present a feasible way of exploiting the image priors captured by the pretrained diffusion model, through addressing the two challenges, i.e., degradation modeling and diffusion guidance. The former aims to simulate the process of the clean image degenerated by certain degradations, and the latter aims at guiding the diffusion model to generate the corresponding clean image. With the motivations, we propose a zero-shot framework for all-in-one image restoration, termed ZeroAIR, which alternatively performs the test-time degradation modeling (TDM) and the three-stage diffusion guidance (TDG) at each timestep of the reverse sampling. To be specific, TDM exploits the diffusion priors to learn a degradation model from a given degraded image, and TDG divides the timesteps into three stages for taking full advantage of the varying diffusion priors. Thanks to their degradation-agnostic property, the all-in-one image restoration could be achieved in a zero-shot way by ZeroAIR. Through extensive experiments, we show that our ZeroAIR achieves comparable even better performance than those task-specific methods. The code will be available on Github.
Variational Relational Point Completion Network for Robust 3D Classification
Apr 18, 2023Real-scanned point clouds are often incomplete due to viewpoint, occlusion, and noise, which hampers 3D geometric modeling and perception. Existing point cloud completion methods tend to generate global shape skeletons and hence lack fine local details. Furthermore, they mostly learn a deterministic partial-to-complete mapping, but overlook structural relations in man-made objects. To tackle these challenges, this paper proposes a variational framework, Variational Relational point Completion Network (VRCNet) with two appealing properties: 1) Probabilistic Modeling. In particular, we propose a dual-path architecture to enable principled probabilistic modeling across partial and complete clouds. One path consumes complete point clouds for reconstruction by learning a point VAE. The other path generates complete shapes for partial point clouds, whose embedded distribution is guided by distribution obtained from the reconstruction path during training. 2) Relational Enhancement. Specifically, we carefully design point self-attention kernel and point selective kernel module to exploit relational point features, which refines local shape details conditioned on the coarse completion. In addition, we contribute multi-view partial point cloud datasets (MVP and MVP-40 dataset) containing over 200,000 high-quality scans, which render partial 3D shapes from 26 uniformly distributed camera poses for each 3D CAD model. Extensive experiments demonstrate that VRCNet outperforms state-of-the-art methods on all standard point cloud completion benchmarks. Notably, VRCNet shows great generalizability and robustness on real-world point cloud scans. Moreover, we can achieve robust 3D classification for partial point clouds with the help of VRCNet, which can highly increase classification accuracy.
ABLE-NeRF: Attention-Based Rendering with Learnable Embeddings for Neural Radiance Field
Mar 24, 2023



Neural Radiance Field (NeRF) is a popular method in representing 3D scenes by optimising a continuous volumetric scene function. Its large success which lies in applying volumetric rendering (VR) is also its Achilles' heel in producing view-dependent effects. As a consequence, glossy and transparent surfaces often appear murky. A remedy to reduce these artefacts is to constrain this VR equation by excluding volumes with back-facing normal. While this approach has some success in rendering glossy surfaces, translucent objects are still poorly represented. In this paper, we present an alternative to the physics-based VR approach by introducing a self-attention-based framework on volumes along a ray. In addition, inspired by modern game engines which utilise Light Probes to store local lighting passing through the scene, we incorporate Learnable Embeddings to capture view dependent effects within the scene. Our method, which we call ABLE-NeRF, significantly reduces `blurry' glossy surfaces in rendering and produces realistic translucent surfaces which lack in prior art. In the Blender dataset, ABLE-NeRF achieves SOTA results and surpasses Ref-NeRF in all 3 image quality metrics PSNR, SSIM, LPIPS.
IntegratedPIFu: Integrated Pixel Aligned Implicit Function for Single-view Human Reconstruction
Nov 15, 2022We propose IntegratedPIFu, a new pixel aligned implicit model that builds on the foundation set by PIFuHD. IntegratedPIFu shows how depth and human parsing information can be predicted and capitalised upon in a pixel-aligned implicit model. In addition, IntegratedPIFu introduces depth oriented sampling, a novel training scheme that improve any pixel aligned implicit model ability to reconstruct important human features without noisy artefacts. Lastly, IntegratedPIFu presents a new architecture that, despite using less model parameters than PIFuHD, is able to improves the structural correctness of reconstructed meshes. Our results show that IntegratedPIFu significantly outperforms existing state of the arts methods on single view human reconstruction. Our code has been made available online.
Exploring Point-BEV Fusion for 3D Point Cloud Object Tracking with Transformer
Aug 10, 2022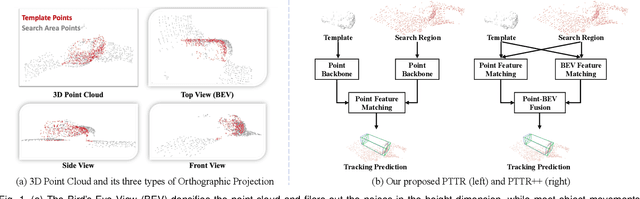
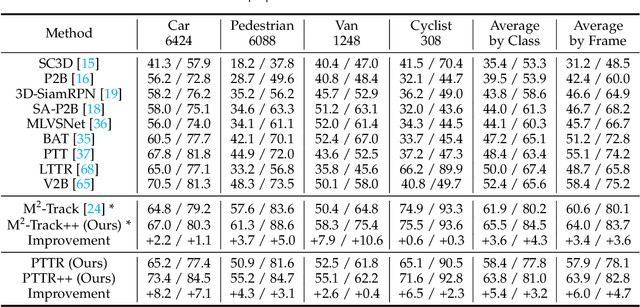
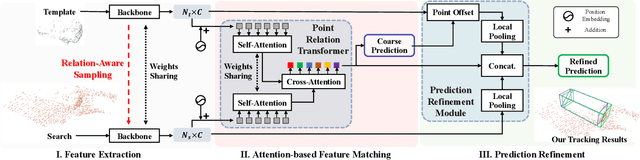
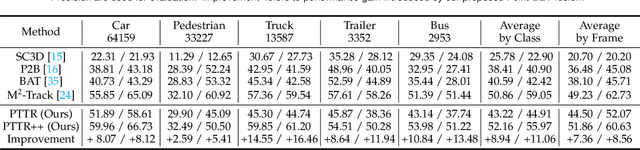
With the prevalence of LiDAR sensors in autonomous driving, 3D object tracking has received increasing attention. In a point cloud sequence, 3D object tracking aims to predict the location and orientation of an object in consecutive frames given an object template. Motivated by the success of transformers, we propose Point Tracking TRansformer (PTTR), which efficiently predicts high-quality 3D tracking results in a coarse-to-fine manner with the help of transformer operations. PTTR consists of three novel designs. 1) Instead of random sampling, we design Relation-Aware Sampling to preserve relevant points to the given template during subsampling. 2) We propose a Point Relation Transformer for effective feature aggregation and feature matching between the template and search region. 3) Based on the coarse tracking results, we employ a novel Prediction Refinement Module to obtain the final refined prediction through local feature pooling. In addition, motivated by the favorable properties of the Bird's-Eye View (BEV) of point clouds in capturing object motion, we further design a more advanced framework named PTTR++, which incorporates both the point-wise view and BEV representation to exploit their complementary effect in generating high-quality tracking results. PTTR++ substantially boosts the tracking performance on top of PTTR with low computational overhead. Extensive experiments over multiple datasets show that our proposed approaches achieve superior 3D tracking accuracy and efficiency.
PTTR: Relational 3D Point Cloud Object Tracking with Transformer
Dec 07, 2021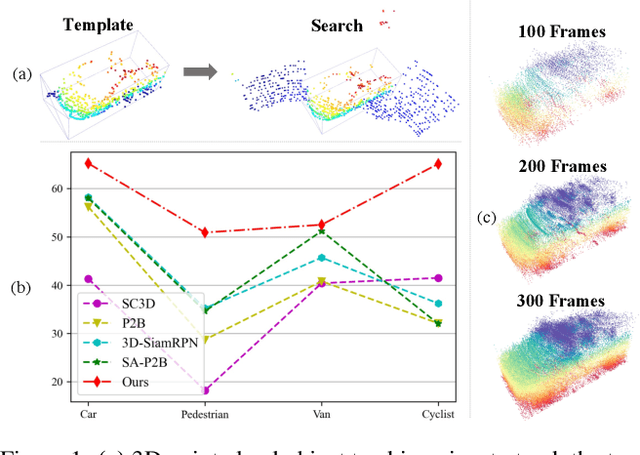
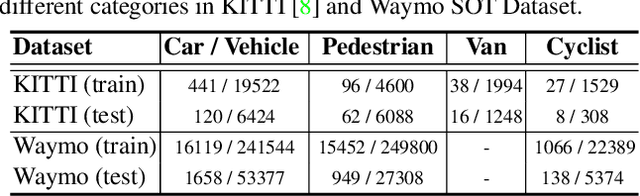
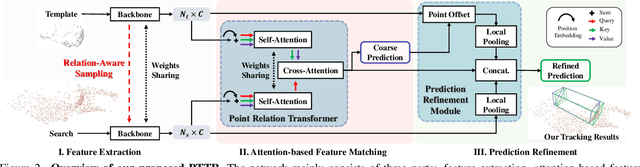
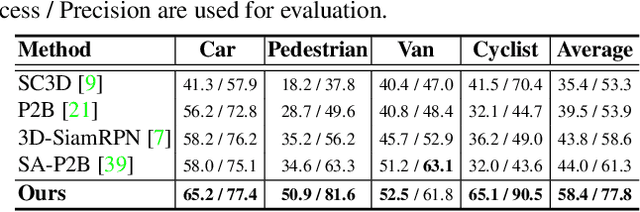
In a point cloud sequence, 3D object tracking aims to predict the location and orientation of an object in the current search point cloud given a template point cloud. Motivated by the success of transformers, we propose Point Tracking TRansformer (PTTR), which efficiently predicts high-quality 3D tracking results in a coarse-to-fine manner with the help of transformer operations. PTTR consists of three novel designs. 1) Instead of random sampling, we design Relation-Aware Sampling to preserve relevant points to given templates during subsampling. 2) Furthermore, we propose a Point Relation Transformer (PRT) consisting of a self-attention and a cross-attention module. The global self-attention operation captures long-range dependencies to enhance encoded point features for the search area and the template, respectively. Subsequently, we generate the coarse tracking results by matching the two sets of point features via cross-attention. 3) Based on the coarse tracking results, we employ a novel Prediction Refinement Module to obtain the final refined prediction. In addition, we create a large-scale point cloud single object tracking benchmark based on the Waymo Open Dataset. Extensive experiments show that PTTR achieves superior point cloud tracking in both accuracy and efficiency.