 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiang Liu
Efficient Transformer-based 3D Object Detection with Dynamic Token Halting
Mar 09, 2023
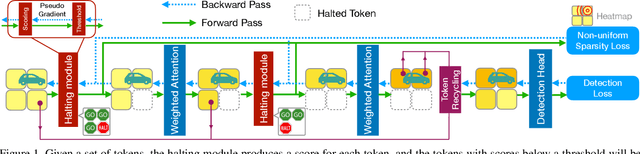
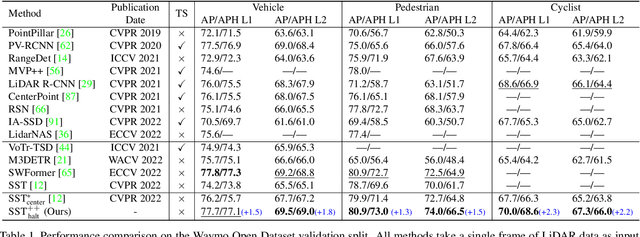
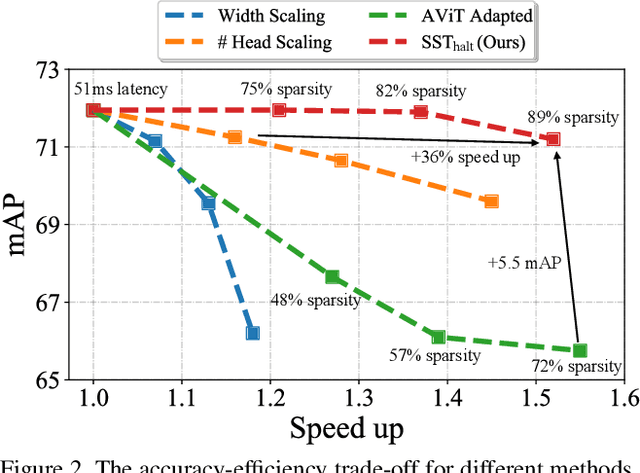

Balancing efficiency and accuracy is a long-standing problem for deploying deep learning models. The trade-off is even more important for real-time safety-critical systems like autonomous vehicles. In this paper, we propose an effective approach for accelerating transformer-based 3D object detectors by dynamically halting tokens at different layers depending on their contribution to the detection task. Although halting a token is a non-differentiable operation, our method allows for differentiable end-to-end learning by leveraging an equivalent differentiable forward-pass. Furthermore, our framework allows halted tokens to be reused to inform the model's predictions through a straightforward token recycling mechanism. Our method significantly improves the Pareto frontier of efficiency versus accuracy when compared with the existing approaches. By halting tokens and increasing model capacity, we are able to improve the baseline model's performance without increasing the model's latency on the Waymo Open Dataset.
Language Is Not All You Need: Aligning Perception with Language Models
Mar 01, 2023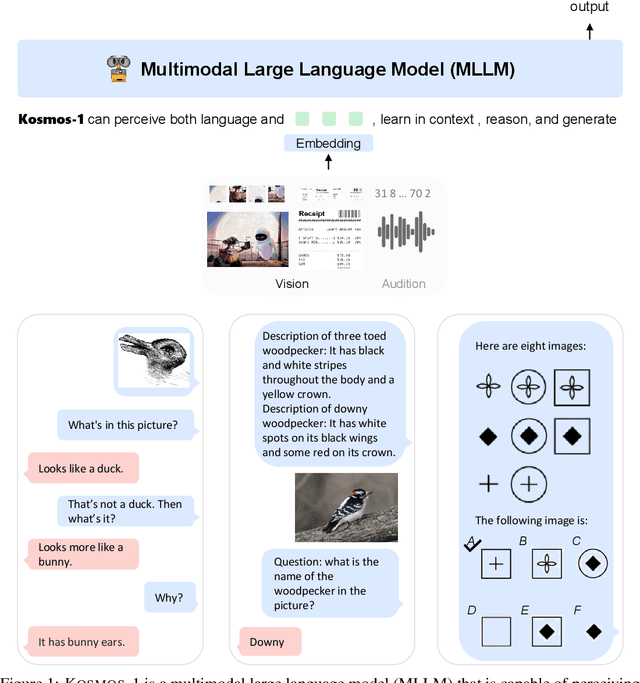

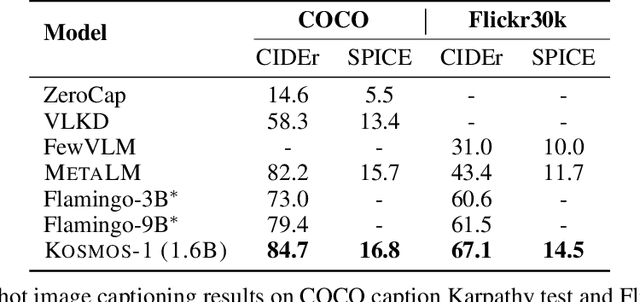
A big convergence of language, multimodal perception, action, and world modeling is a key step toward artificial general intelligence. In this work, we introduce Kosmos-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot). Specifically, we train Kosmos-1 from scratch on web-scale multimodal corpora, including arbitrarily interleaved text and images, image-caption pairs, and text data. We evaluate various settings, including zero-shot, few-shot, and multimodal chain-of-thought prompting, on a wide range of tasks without any gradient updates or finetuning. Experimental results show that Kosmos-1 achieves impressive performance on (i) language understanding, generation, and even OCR-free NLP (directly fed with document images), (ii) perception-language tasks, including multimodal dialogue, image captioning, visual question answering, and (iii) vision tasks, such as image recognition with descriptions (specifying classification via text instructions). We also show that MLLMs can benefit from cross-modal transfer, i.e., transfer knowledge from language to multimodal, and from multimodal to language. In addition, we introduce a dataset of Raven IQ test, which diagnoses the nonverbal reasoning capability of MLLMs.
Friend Recall in Online Games via Pre-training Edge Transformers
Feb 20, 2023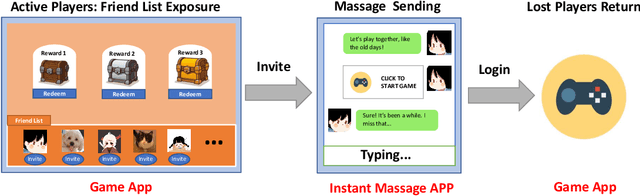
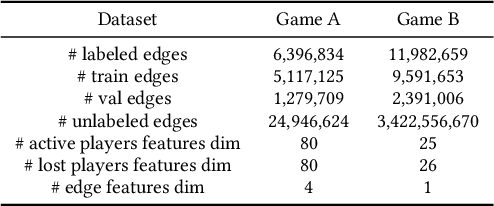
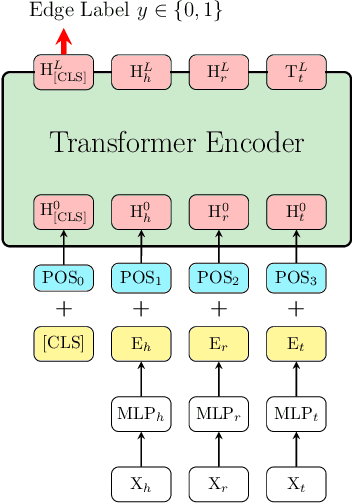
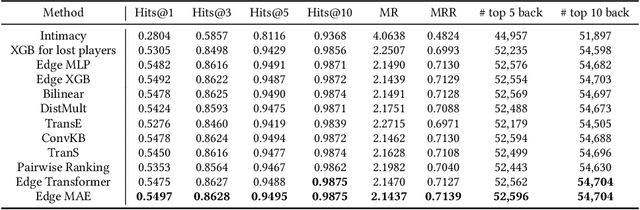
Friend recall is an important way to improve Daily Active Users (DAU) in Tencent games. Traditional friend recall methods focus on rules like friend intimacy or training a classifier for predicting lost players' return probability, but ignore feature information of (active) players and historical friend recall events. In this work, we treat friend recall as a link prediction problem and explore several link prediction methods which can use features of both active and lost players, as well as historical events. Furthermore, we propose a novel Edge Transformer model and pre-train the model via masked auto-encoders. Our method achieves state-of-the-art results in the offline experiments and online A/B Tests of three Tencent games.
RoNet: Toward Robust Neural Assisted Mobile Network Configuration
Feb 07, 2023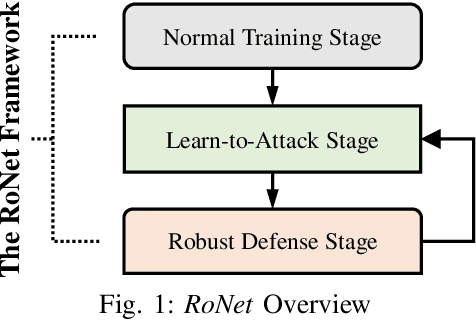
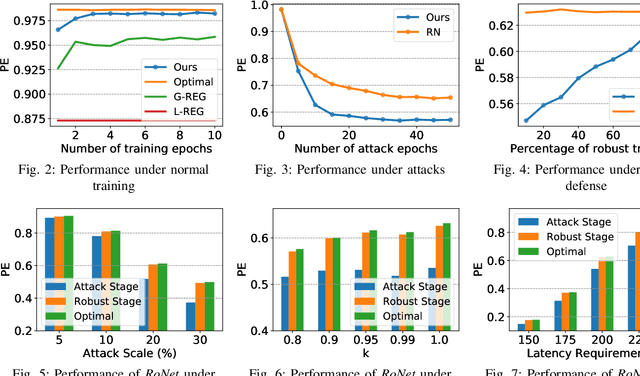
Automating configuration is the key path to achieving zero-touch network management in ever-complicating mobile networks. Deep learning techniques show great potential to automatically learn and tackle high-dimensional networking problems. The vulnerability of deep learning to deviated input space, however, raises increasing deployment concerns under unpredictable variabilities and simulation-to-reality discrepancy in real-world networks. In this paper, we propose a novel RoNet framework to improve the robustness of neural-assisted configuration policies. We formulate the network configuration problem to maximize performance efficiency when serving diverse user applications. We design three integrated stages with novel normal training, learn-to-attack, and robust defense method for balancing the robustness and performance of policies. We evaluate RoNet via the NS-3 simulator extensively and the simulation results show that RoNet outperforms existing solutions in terms of robustness, adaptability, and scalability.
CoMap: Proactive Provision for Crowdsourcing Map in Automotive Edge Computing
Feb 07, 2023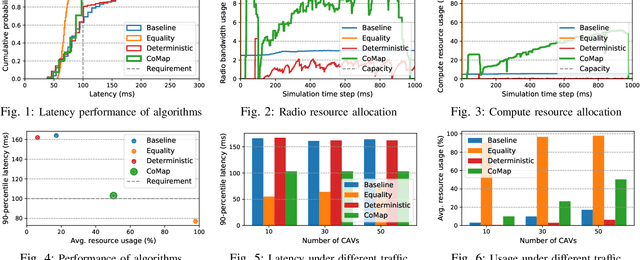
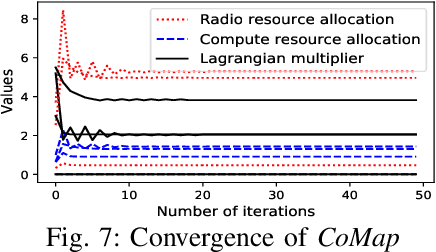
Crowdsourcing data from connected and automated vehicles (CAVs) is a cost-efficient way to achieve high-definition maps with up-to-date transient road information. Achieving the map with deterministic latency performance is, however, challenging due to the unpredictable resource competition and distributional resource demands. In this paper, we propose CoMap, a new crowdsourcing high definition (HD) map to minimize the monetary cost of network resource usage while satisfying the percentile requirement of end-to-end latency. We design a novel CROP algorithm to learn the resource demands of CAV offloading, optimize offloading decisions, and proactively allocate temporal network resources in a fully distributed manner. In particular, we create a prediction model to estimate the uncertainty of resource demands based on Bayesian neural networks and develop a utilization balancing scheme to resolve the imbalanced resource utilization in individual infrastructures. We evaluate the performance of CoMap with extensive simulations in an automotive edge computing network simulator. The results show that CoMap reduces up to 80.4% average resource usage as compared to existing solutions.
MetaTKG: Learning Evolutionary Meta-Knowledge for Temporal Knowledge Graph Reasoning
Feb 02, 2023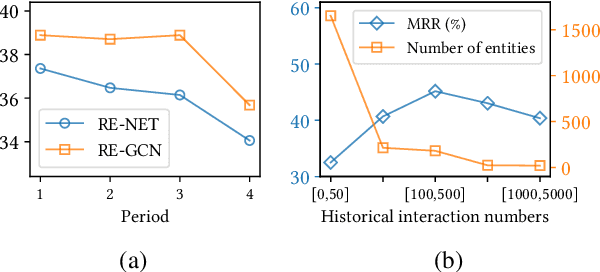
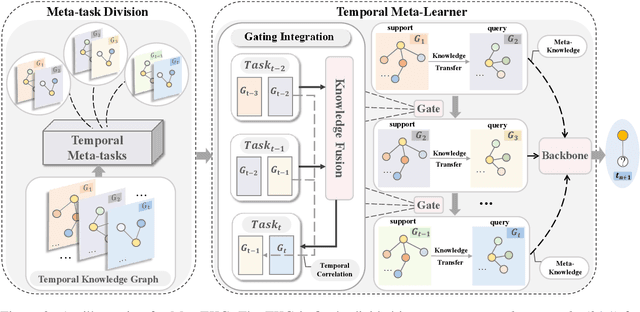

Reasoning over Temporal Knowledge Graphs (TKGs) aims to predict future facts based on given history. One of the key challenges for prediction is to learn the evolution of facts. Most existing works focus on exploring evolutionary information in history to obtain effective temporal embeddings for entities and relations, but they ignore the variation in evolution patterns of facts, which makes them struggle to adapt to future data with different evolution patterns. Moreover, new entities continue to emerge along with the evolution of facts over time. Since existing models highly rely on historical information to learn embeddings for entities, they perform poorly on such entities with little historical information. To tackle these issues, we propose a novel Temporal Meta-learning framework for TKG reasoning, MetaTKG for brevity. Specifically, our method regards TKG prediction as many temporal meta-tasks, and utilizes the designed Temporal Meta-learner to learn evolutionary meta-knowledge from these meta-tasks. The proposed method aims to guide the backbones to learn to adapt quickly to future data and deal with entities with little historical information by the learned meta-knowledge. Specially, in temporal meta-learner, we design a Gating Integration module to adaptively establish temporal correlations between meta-tasks. Extensive experiments on four widely-used datasets and three backbones demonstrate that our method can greatly improve the performance.
Metamobility: Connecting Future Mobility with Metaverse
Jan 17, 2023
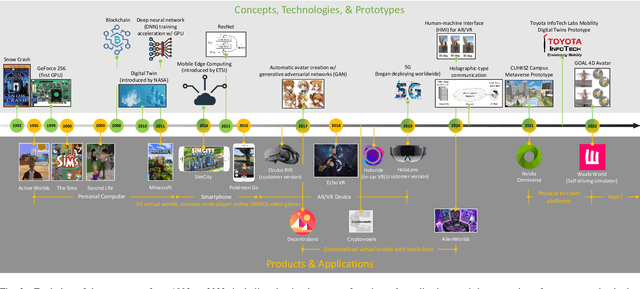
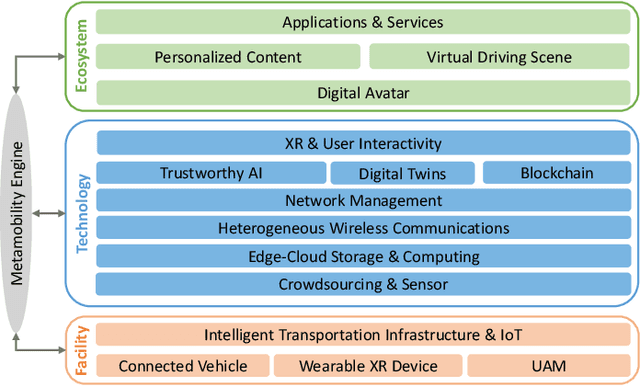
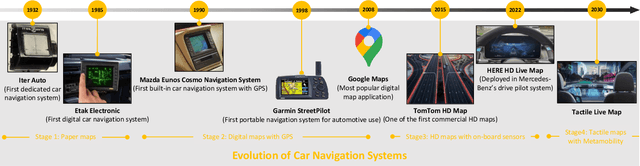
A Metaverse is a perpetual, immersive, and shared digital universe that is linked to but beyond the physical reality, and this emerging technology is attracting enormous attention from different industries. In this article, we define the first holistic realization of the metaverse in the mobility domain, coined as ``metamobility". We present our vision of what metamobility will be and describe its basic architecture. We also propose two use cases, tactile live maps and meta-empowered advanced driver-assistance systems (ADAS), to demonstrate how the metamobility will benefit and reshape future mobility systems. Each use case is discussed from the perspective of the technology evolution, future vision, and critical research challenges, respectively. Finally, we identify multiple concrete open research issues for the development and deployment of the metamobility.
Network Slicing via Transfer Learning aided Distributed Deep Reinforcement Learning
Jan 09, 2023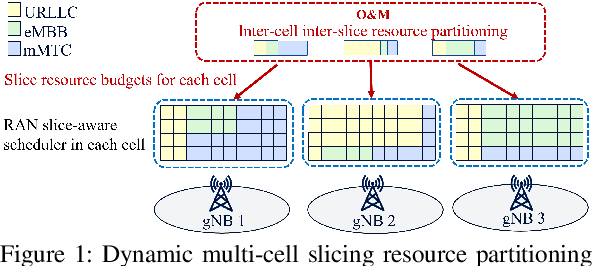
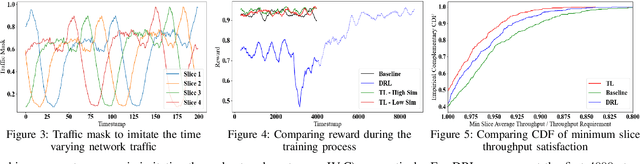
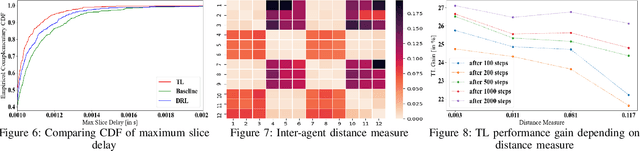
Deep reinforcement learning (DRL) has been increasingly employed to handle the dynamic and complex resource management in network slicing. The deployment of DRL policies in real networks, however, is complicated by heterogeneous cell conditions. In this paper, we propose a novel transfer learning (TL) aided multi-agent deep reinforcement learning (MADRL) approach with inter-agent similarity analysis for inter-cell inter-slice resource partitioning. First, we design a coordinated MADRL method with information sharing to intelligently partition resource to slices and manage inter-cell interference. Second, we propose an integrated TL method to transfer the learned DRL policies among different local agents for accelerating the policy deployment. The method is composed of a new domain and task similarity measurement approach and a new knowledge transfer approach, which resolves the problem of from whom to transfer and how to transfer. We evaluated the proposed solution with extensive simulations in a system-level simulator and show that our approach outperforms the state-of-the-art solutions in terms of performance, convergence speed and sample efficiency. Moreover, by applying TL, we achieve an additional gain over 27% higher than the coordinate MADRL approach without TL.
Goal-oriented Autonomous Driving
Dec 20, 2022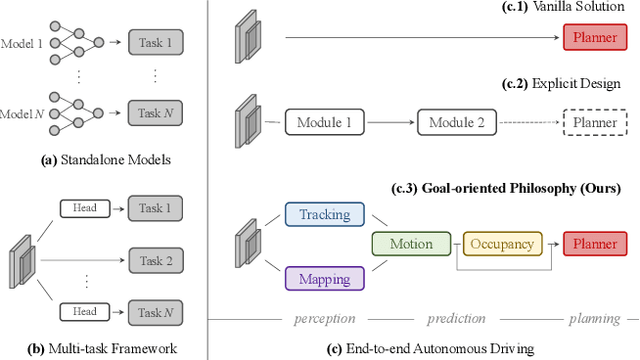
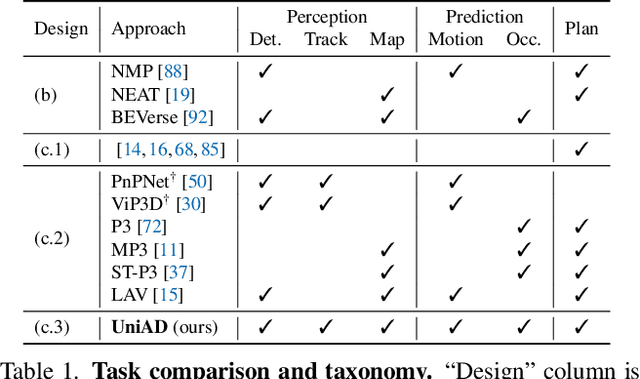
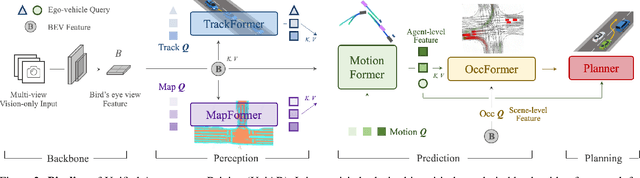
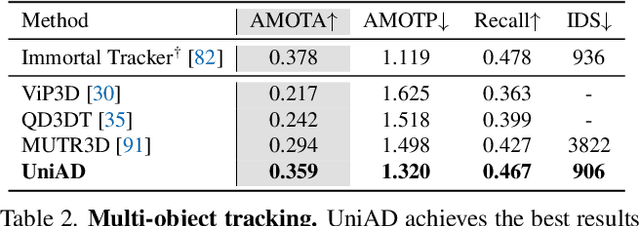
Modern autonomous driving system is characterized as modular tasks in sequential order, i.e., perception, prediction and planning. As sensors and hardware get improved, there is trending popularity to devise a system that can perform a wide diversity of tasks to fulfill higher-level intelligence. Contemporary approaches resort to either deploying standalone models for individual tasks, or designing a multi-task paradigm with separate heads. These might suffer from accumulative error or negative transfer effect. Instead, we argue that a favorable algorithm framework should be devised and optimized in pursuit of the ultimate goal, i.e. planning of the self-driving-car. Oriented at this goal, we revisit the key components within perception and prediction. We analyze each module and prioritize the tasks hierarchically, such that all these tasks contribute to planning (the goal). To this end, we introduce Unified Autonomous Driving (UniAD), the first comprehensive framework up-to-date that incorporates full-stack driving tasks in one network. It is exquisitely devised to leverage advantages of each module, and provide complementary feature abstractions for agent interaction from a global perspective. Tasks are communicated with unified query design to facilitate each other toward planning. We instantiate UniAD on the challenging nuScenes benchmark. With extensive ablations, the effectiveness of using such a philosophy is proven to surpass previous state-of-the-arts by a large margin in all aspects. The full suite of codebase and models would be available to facilitate future research in the community.
PathFusion: Path-consistent Lidar-Camera Deep Feature Fusion
Dec 12, 2022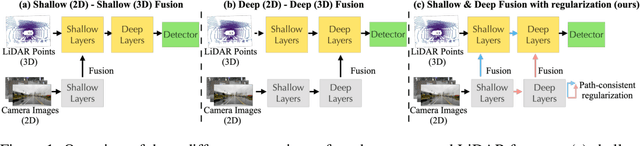
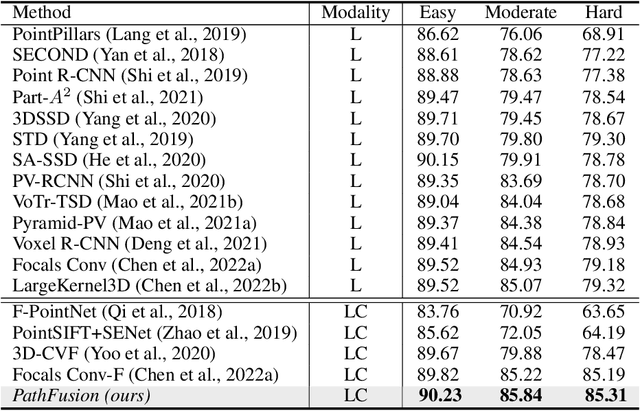
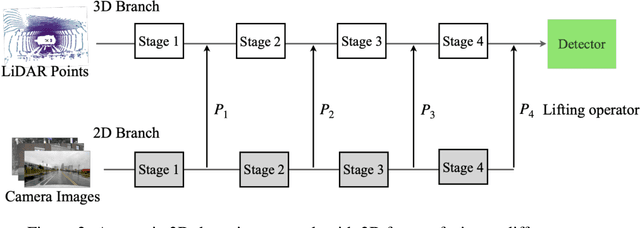

Fusing camera with LiDAR is a promising technique to improve the accuracy of 3D detection due to the complementary physical properties. While most existing methods focus on fusing camera features directly with raw LiDAR point clouds or shallow 3D features, it is observed that direct deep 3D feature fusion achieves inferior accuracy due to feature misalignment. The misalignment that originates from the feature aggregation across large receptive fields becomes increasingly severe for deep network stages. In this paper, we propose PathFusion to enable path-consistent LiDAR-camera deep feature fusion. PathFusion introduces a path consistency loss between shallow and deep features, which encourages the 2D backbone and its fusion path to transform 2D features in a way that is semantically aligned with the transform of the 3D backbone. We apply PathFusion to the prior-art fusion baseline, Focals Conv, and observe more than 1.2\% mAP improvements on the nuScenes test split consistently with and without testing-time augmentations. Moreover, PathFusion also improves KITTI AP3D (R11) by more than 0.6% on moderate level.