 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
DUBLIN -- Document Understanding By Language-Image Network
May 24, 2023



Visual document understanding is a complex task that involves analyzing both the text and the visual elements in document images. Existing models often rely on manual feature engineering or domain-specific pipelines, which limit their generalization ability across different document types and languages. In this paper, we propose DUBLIN, which is pretrained on web pages using three novel objectives: Masked Document Content Generation Task, Bounding Box Task, and Rendered Question Answering Task, that leverage both the spatial and semantic information in the document images. Our model achieves competitive or state-of-the-art results on several benchmarks, such as Web-Based Structural Reading Comprehension, Document Visual Question Answering, Key Information Extraction, Diagram Understanding, and Table Question Answering. In particular, we show that DUBLIN is the first pixel-based model to achieve an EM of 77.75 and F1 of 84.25 on the WebSRC dataset. We also show that our model outperforms the current pixel-based SoTA models on DocVQA and AI2D datasets by 2% and 21%, respectively. Also, DUBLIN is the first ever pixel-based model which achieves comparable performance to text-based SoTA methods on XFUND dataset for Semantic Entity Recognition showcasing its multilingual capability. Moreover, we create new baselines for text-based datasets by rendering them as document images to promote research in this direction.
ArK: Augmented Reality with Knowledge Interactive Emergent Ability
May 01, 2023



Despite the growing adoption of mixed reality and interactive AI agents, it remains challenging for these systems to generate high quality 2D/3D scenes in unseen environments. The common practice requires deploying an AI agent to collect large amounts of data for model training for every new task. This process is costly, or even impossible, for many domains. In this study, we develop an infinite agent that learns to transfer knowledge memory from general foundation models (e.g. GPT4, DALLE) to novel domains or scenarios for scene understanding and generation in the physical or virtual world. The heart of our approach is an emerging mechanism, dubbed Augmented Reality with Knowledge Inference Interaction (ArK), which leverages knowledge-memory to generate scenes in unseen physical world and virtual reality environments. The knowledge interactive emergent ability (Figure 1) is demonstrated as the observation learns i) micro-action of cross-modality: in multi-modality models to collect a large amount of relevant knowledge memory data for each interaction task (e.g., unseen scene understanding) from the physical reality; and ii) macro-behavior of reality-agnostic: in mix-reality environments to improve interactions that tailor to different characterized roles, target variables, collaborative information, and so on. We validate the effectiveness of ArK on the scene generation and editing tasks. We show that our ArK approach, combined with large foundation models, significantly improves the quality of generated 2D/3D scenes, compared to baselines, demonstrating the potential benefit of incorporating ArK in generative AI for applications such as metaverse and gaming simulation.
Language Is Not All You Need: Aligning Perception with Language Models
Mar 01, 2023



A big convergence of language, multimodal perception, action, and world modeling is a key step toward artificial general intelligence. In this work, we introduce Kosmos-1, a Multimodal Large Language Model (MLLM) that can perceive general modalities, learn in context (i.e., few-shot), and follow instructions (i.e., zero-shot). Specifically, we train Kosmos-1 from scratch on web-scale multimodal corpora, including arbitrarily interleaved text and images, image-caption pairs, and text data. We evaluate various settings, including zero-shot, few-shot, and multimodal chain-of-thought prompting, on a wide range of tasks without any gradient updates or finetuning. Experimental results show that Kosmos-1 achieves impressive performance on (i) language understanding, generation, and even OCR-free NLP (directly fed with document images), (ii) perception-language tasks, including multimodal dialogue, image captioning, visual question answering, and (iii) vision tasks, such as image recognition with descriptions (specifying classification via text instructions). We also show that MLLMs can benefit from cross-modal transfer, i.e., transfer knowledge from language to multimodal, and from multimodal to language. In addition, we introduce a dataset of Raven IQ test, which diagnoses the nonverbal reasoning capability of MLLMs.
Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
Aug 31, 2022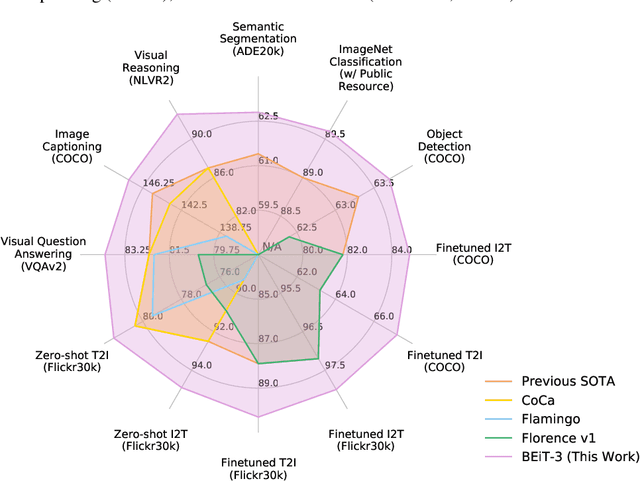
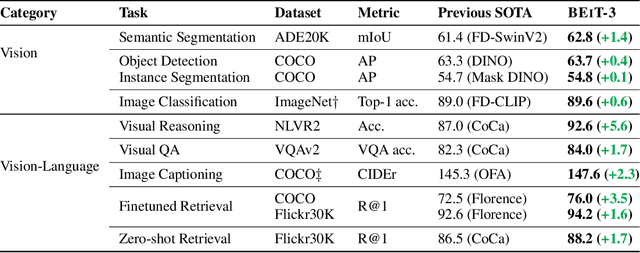
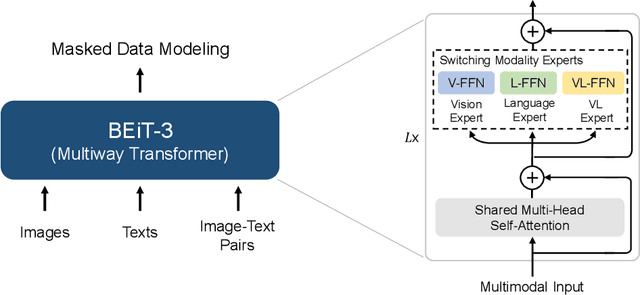

A big convergence of language, vision, and multimodal pretraining is emerging. In this work, we introduce a general-purpose multimodal foundation model BEiT-3, which achieves state-of-the-art transfer performance on both vision and vision-language tasks. Specifically, we advance the big convergence from three aspects: backbone architecture, pretraining task, and model scaling up. We introduce Multiway Transformers for general-purpose modeling, where the modular architecture enables both deep fusion and modality-specific encoding. Based on the shared backbone, we perform masked "language" modeling on images (Imglish), texts (English), and image-text pairs ("parallel sentences") in a unified manner. Experimental results show that BEiT-3 obtains state-of-the-art performance on object detection (COCO), semantic segmentation (ADE20K), image classification (ImageNet), visual reasoning (NLVR2), visual question answering (VQAv2), image captioning (COCO), and cross-modal retrieval (Flickr30K, COCO).
Compressive Imaging using Approximate Message Passing and a Markov-Tree Prior
Aug 12, 2011
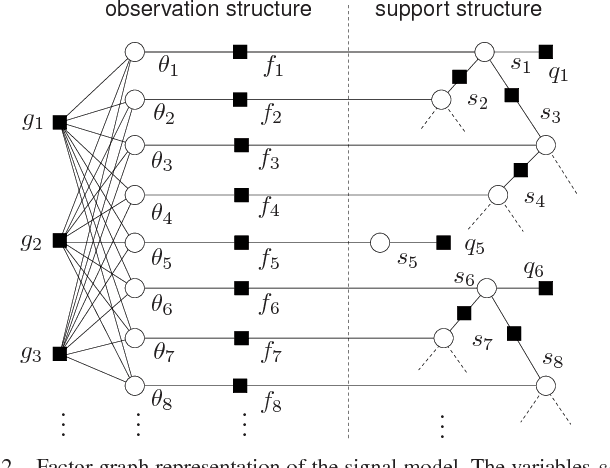
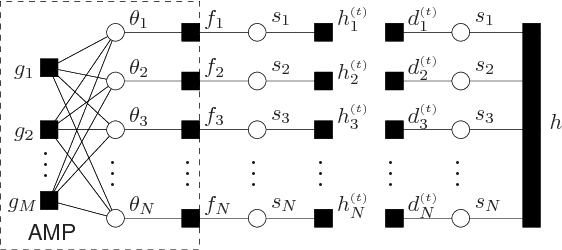

We propose a novel algorithm for compressive imaging that exploits both the sparsity and persistence across scales found in the 2D wavelet transform coefficients of natural images. Like other recent works, we model wavelet structure using a hidden Markov tree (HMT) but, unlike other works, ours is based on loopy belief propagation (LBP). For LBP, we adopt a recently proposed "turbo" message passing schedule that alternates between exploitation of HMT structure and exploitation of compressive-measurement structure. For the latter, we leverage Donoho, Maleki, and Montanari's recently proposed approximate message passing (AMP) algorithm. Experiments with a large image database suggest that, relative to existing schemes, our turbo LBP approach yields state-of-the-art reconstruction performance with substantial reduction in complexity.