 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRISE: Self-Improving Robot Policy with Compositional World Model
Feb 11, 2026Despite the sustained scaling on model capacity and data acquisition, Vision-Language-Action (VLA) models remain brittle in contact-rich and dynamic manipulation tasks, where minor execution deviations can compound into failures. While reinforcement learning (RL) offers a principled path to robustness, on-policy RL in the physical world is constrained by safety risk, hardware cost, and environment reset. To bridge this gap, we present RISE, a scalable framework of robotic reinforcement learning via imagination. At its core is a Compositional World Model that (i) predicts multi-view future via a controllable dynamics model, and (ii) evaluates imagined outcomes with a progress value model, producing informative advantages for the policy improvement. Such compositional design allows state and value to be tailored by best-suited yet distinct architectures and objectives. These components are integrated into a closed-loop self-improving pipeline that continuously generates imaginary rollouts, estimates advantages, and updates the policy in imaginary space without costly physical interaction. Across three challenging real-world tasks, RISE yields significant improvement over prior art, with more than +35% absolute performance increase in dynamic brick sorting, +45% for backpack packing, and +35% for box closing, respectively.
PlannerRFT: Reinforcing Diffusion Planners through Closed-Loop and Sample-Efficient Fine-Tuning
Jan 19, 2026Diffusion-based planners have emerged as a promising approach for human-like trajectory generation in autonomous driving. Recent works incorporate reinforcement fine-tuning to enhance the robustness of diffusion planners through reward-oriented optimization in a generation-evaluation loop. However, they struggle to generate multi-modal, scenario-adaptive trajectories, hindering the exploitation efficiency of informative rewards during fine-tuning. To resolve this, we propose PlannerRFT, a sample-efficient reinforcement fine-tuning framework for diffusion-based planners. PlannerRFT adopts a dual-branch optimization that simultaneously refines the trajectory distribution and adaptively guides the denoising process toward more promising exploration, without altering the original inference pipeline. To support parallel learning at scale, we develop nuMax, an optimized simulator that achieves 10 times faster rollout compared to native nuPlan. Extensive experiments shows that PlannerRFT yields state-of-the-art performance with distinct behaviors emerging during the learning process.
ReSim: Reliable World Simulation for Autonomous Driving
Jun 11, 2025How can we reliably simulate future driving scenarios under a wide range of ego driving behaviors? Recent driving world models, developed exclusively on real-world driving data composed mainly of safe expert trajectories, struggle to follow hazardous or non-expert behaviors, which are rare in such data. This limitation restricts their applicability to tasks such as policy evaluation. In this work, we address this challenge by enriching real-world human demonstrations with diverse non-expert data collected from a driving simulator (e.g., CARLA), and building a controllable world model trained on this heterogeneous corpus. Starting with a video generator featuring a diffusion transformer architecture, we devise several strategies to effectively integrate conditioning signals and improve prediction controllability and fidelity. The resulting model, ReSim, enables Reliable Simulation of diverse open-world driving scenarios under various actions, including hazardous non-expert ones. To close the gap between high-fidelity simulation and applications that require reward signals to judge different actions, we introduce a Video2Reward module that estimates a reward from ReSim's simulated future. Our ReSim paradigm achieves up to 44% higher visual fidelity, improves controllability for both expert and non-expert actions by over 50%, and boosts planning and policy selection performance on NAVSIM by 2% and 25%, respectively.
Decoupled Diffusion Sparks Adaptive Scene Generation
Apr 14, 2025Controllable scene generation could reduce the cost of diverse data collection substantially for autonomous driving. Prior works formulate the traffic layout generation as predictive progress, either by denoising entire sequences at once or by iteratively predicting the next frame. However, full sequence denoising hinders online reaction, while the latter's short-sighted next-frame prediction lacks precise goal-state guidance. Further, the learned model struggles to generate complex or challenging scenarios due to a large number of safe and ordinal driving behaviors from open datasets. To overcome these, we introduce Nexus, a decoupled scene generation framework that improves reactivity and goal conditioning by simulating both ordinal and challenging scenarios from fine-grained tokens with independent noise states. At the core of the decoupled pipeline is the integration of a partial noise-masking training strategy and a noise-aware schedule that ensures timely environmental updates throughout the denoising process. To complement challenging scenario generation, we collect a dataset consisting of complex corner cases. It covers 540 hours of simulated data, including high-risk interactions such as cut-in, sudden braking, and collision. Nexus achieves superior generation realism while preserving reactivity and goal orientation, with a 40% reduction in displacement error. We further demonstrate that Nexus improves closed-loop planning by 20% through data augmentation and showcase its capability in safety-critical data generation.
Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability
May 27, 2024



World models can foresee the outcomes of different actions, which is of paramount importance for autonomous driving. Nevertheless, existing driving world models still have limitations in generalization to unseen environments, prediction fidelity of critical details, and action controllability for flexible application. In this paper, we present Vista, a generalizable driving world model with high fidelity and versatile controllability. Based on a systematic diagnosis of existing methods, we introduce several key ingredients to address these limitations. To accurately predict real-world dynamics at high resolution, we propose two novel losses to promote the learning of moving instances and structural information. We also devise an effective latent replacement approach to inject historical frames as priors for coherent long-horizon rollouts. For action controllability, we incorporate a versatile set of controls from high-level intentions (command, goal point) to low-level maneuvers (trajectory, angle, and speed) through an efficient learning strategy. After large-scale training, the capabilities of Vista can seamlessly generalize to different scenarios. Extensive experiments on multiple datasets show that Vista outperforms the most advanced general-purpose video generator in over 70% of comparisons and surpasses the best-performing driving world model by 55% in FID and 27% in FVD. Moreover, for the first time, we utilize the capacity of Vista itself to establish a generalizable reward for real-world action evaluation without accessing the ground truth actions.
Generalized Predictive Model for Autonomous Driving
Mar 14, 2024



In this paper, we introduce the first large-scale video prediction model in the autonomous driving discipline. To eliminate the restriction of high-cost data collection and empower the generalization ability of our model, we acquire massive data from the web and pair it with diverse and high-quality text descriptions. The resultant dataset accumulates over 2000 hours of driving videos, spanning areas all over the world with diverse weather conditions and traffic scenarios. Inheriting the merits from recent latent diffusion models, our model, dubbed GenAD, handles the challenging dynamics in driving scenes with novel temporal reasoning blocks. We showcase that it can generalize to various unseen driving datasets in a zero-shot manner, surpassing general or driving-specific video prediction counterparts. Furthermore, GenAD can be adapted into an action-conditioned prediction model or a motion planner, holding great potential for real-world driving applications.
Goal-oriented Autonomous Driving
Dec 20, 2022



Modern autonomous driving system is characterized as modular tasks in sequential order, i.e., perception, prediction and planning. As sensors and hardware get improved, there is trending popularity to devise a system that can perform a wide diversity of tasks to fulfill higher-level intelligence. Contemporary approaches resort to either deploying standalone models for individual tasks, or designing a multi-task paradigm with separate heads. These might suffer from accumulative error or negative transfer effect. Instead, we argue that a favorable algorithm framework should be devised and optimized in pursuit of the ultimate goal, i.e. planning of the self-driving-car. Oriented at this goal, we revisit the key components within perception and prediction. We analyze each module and prioritize the tasks hierarchically, such that all these tasks contribute to planning (the goal). To this end, we introduce Unified Autonomous Driving (UniAD), the first comprehensive framework up-to-date that incorporates full-stack driving tasks in one network. It is exquisitely devised to leverage advantages of each module, and provide complementary feature abstractions for agent interaction from a global perspective. Tasks are communicated with unified query design to facilitate each other toward planning. We instantiate UniAD on the challenging nuScenes benchmark. With extensive ablations, the effectiveness of using such a philosophy is proven to surpass previous state-of-the-arts by a large margin in all aspects. The full suite of codebase and models would be available to facilitate future research in the community.
Delving into the Devils of Bird's-eye-view Perception: A Review, Evaluation and Recipe
Sep 12, 2022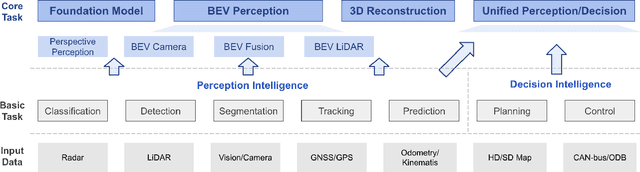
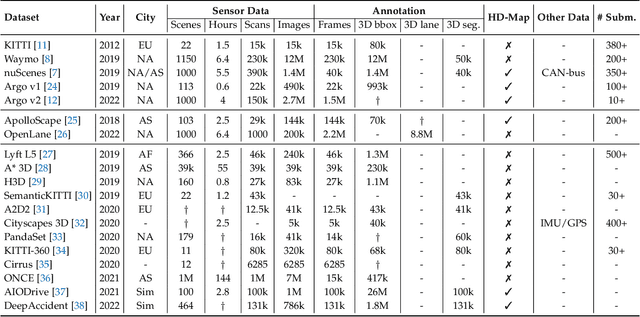
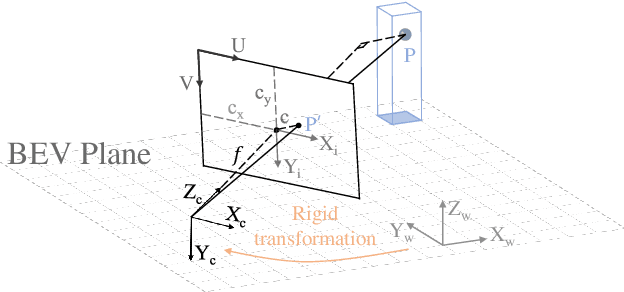
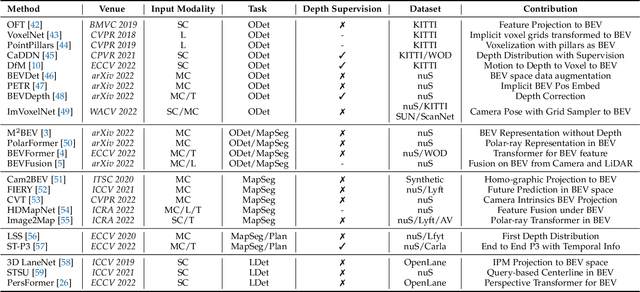
Learning powerful representations in bird's-eye-view (BEV) for perception tasks is trending and drawing extensive attention both from industry and academia. Conventional approaches for most autonomous driving algorithms perform detection, segmentation, tracking, etc., in a front or perspective view. As sensor configurations get more complex, integrating multi-source information from different sensors and representing features in a unified view come of vital importance. BEV perception inherits several advantages, as representing surrounding scenes in BEV is intuitive and fusion-friendly; and representing objects in BEV is most desirable for subsequent modules as in planning and/or control. The core problems for BEV perception lie in (a) how to reconstruct the lost 3D information via view transformation from perspective view to BEV; (b) how to acquire ground truth annotations in BEV grid; (c) how to formulate the pipeline to incorporate features from different sources and views; and (d) how to adapt and generalize algorithms as sensor configurations vary across different scenarios. In this survey, we review the most recent work on BEV perception and provide an in-depth analysis of different solutions. Moreover, several systematic designs of BEV approach from the industry are depicted as well. Furthermore, we introduce a full suite of practical guidebook to improve the performance of BEV perception tasks, including camera, LiDAR and fusion inputs. At last, we point out the future research directions in this area. We hope this report would shed some light on the community and encourage more research effort on BEV perception. We keep an active repository to collect the most recent work and provide a toolbox for bag of tricks at https://github.com/OpenPerceptionX/BEVPerception-Survey-Recipe.