 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP: Sequence-to-Sequence Transformer Pre-training for Document Summarization
Apr 04, 2020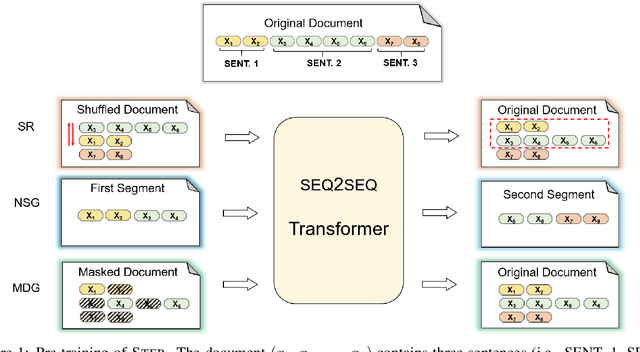
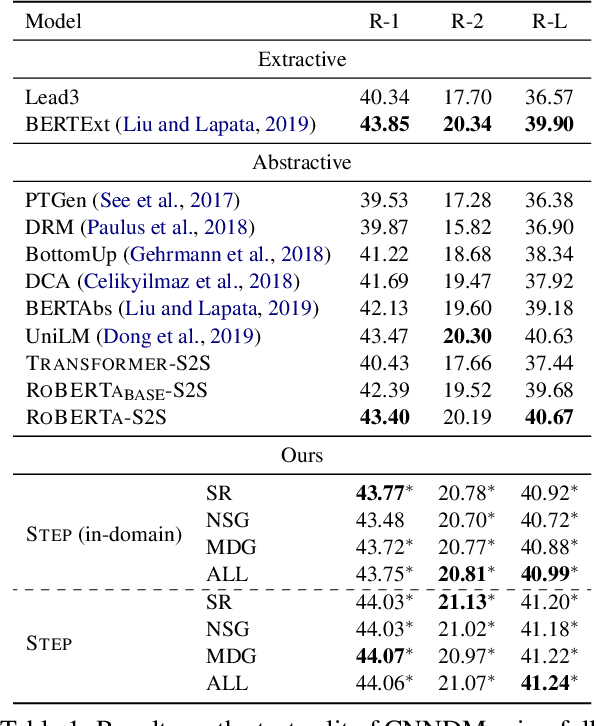
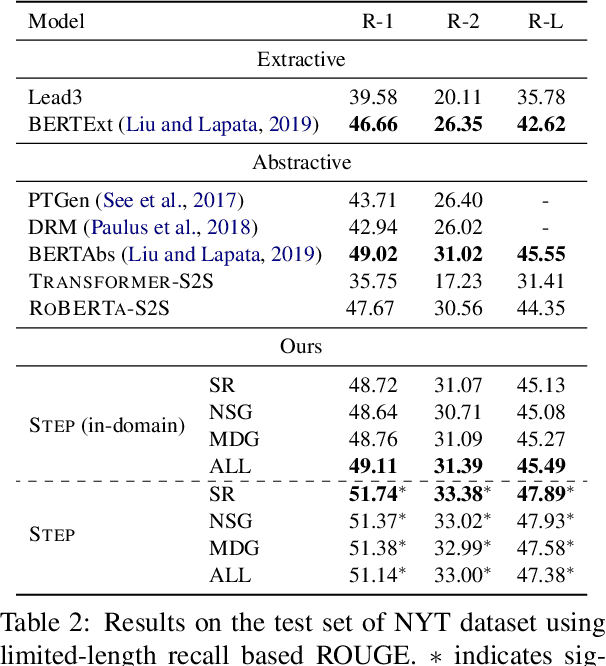
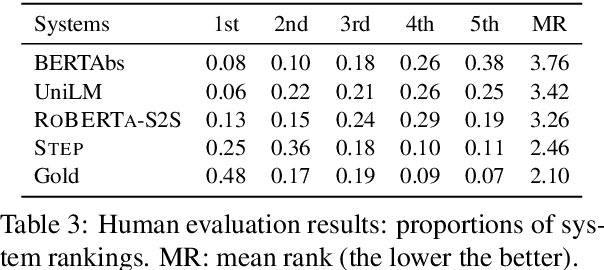
Abstractive summarization aims to rewrite a long document to its shorter form, which is usually modeled as a sequence-to-sequence (Seq2Seq) learning problem. Seq2Seq Transformers are powerful models for this problem. Unfortunately, training large Seq2Seq Transformers on limited supervised summarization data is challenging. We, therefore, propose STEP (as shorthand for Sequence-to-Sequence Transformer Pre-training), which can be trained on large scale unlabeled documents. Specifically, STEP is pre-trained using three different tasks, namely sentence reordering, next sentence generation, and masked document generation. Experiments on two summarization datasets show that all three tasks can improve performance upon a heavily tuned large Seq2Seq Transformer which already includes a strong pre-trained encoder by a large margin. By using our best task to pre-train STEP, we outperform the best published abstractive model on CNN/DailyMail by 0.8 ROUGE-2 and New York Times by 2.4 ROUGE-2.
XGPT: Cross-modal Generative Pre-Training for Image Captioning
Mar 04, 2020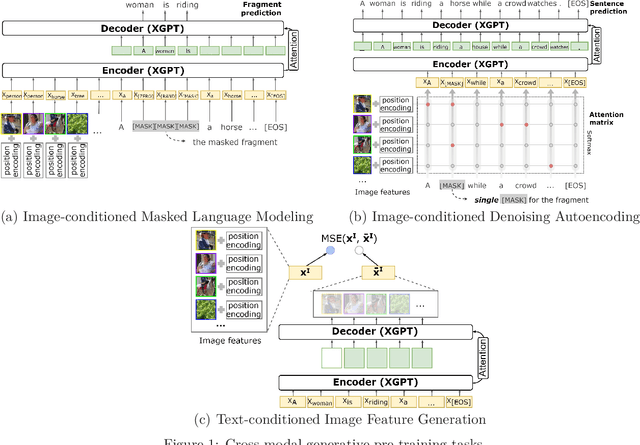
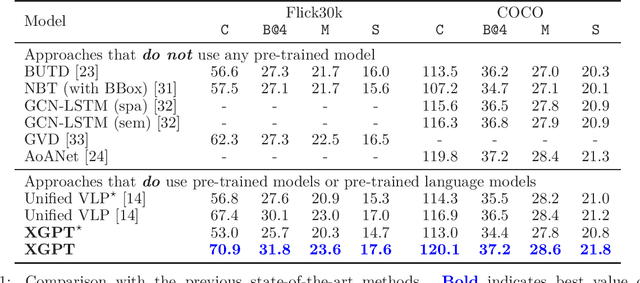
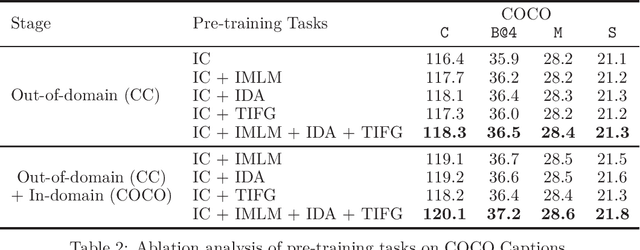
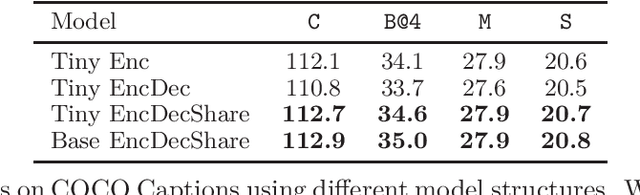
While many BERT-based cross-modal pre-trained models produce excellent results on downstream understanding tasks like image-text retrieval and VQA, they cannot be applied to generation tasks directly. In this paper, we propose XGPT, a new method of Cross-modal Generative Pre-Training for Image Captioning that is designed to pre-train text-to-image caption generators through three novel generation tasks, including Image-conditioned Masked Language Modeling (IMLM), Image-conditioned Denoising Autoencoding (IDA), and Text-conditioned Image Feature Generation (TIFG). As a result, the pre-trained XGPT can be fine-tuned without any task-specific architecture modifications to create state-of-the-art models for image captioning. Experiments show that XGPT obtains new state-of-the-art results on the benchmark datasets, including COCO Captions and Flickr30k Captions. We also use XGPT to generate new image captions as data augmentation for the image retrieval task and achieve significant improvement on all recall metrics.
UniLMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training
Feb 28, 2020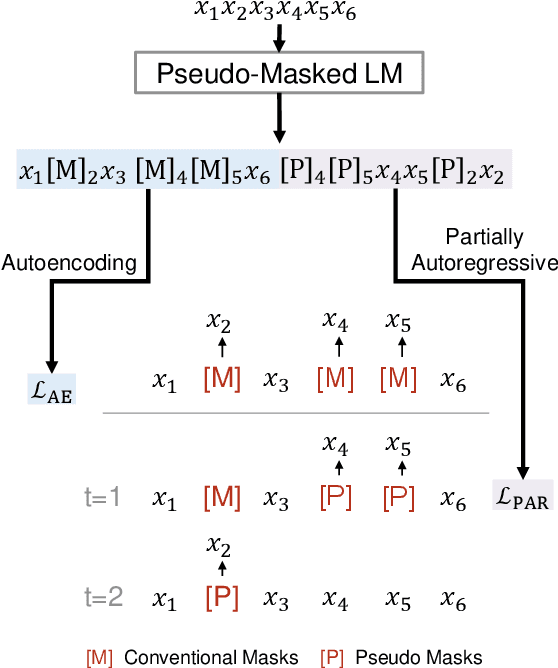

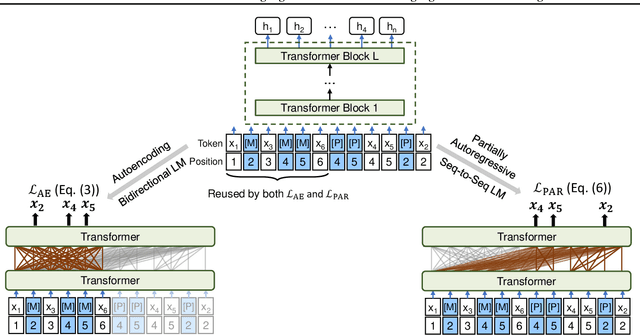
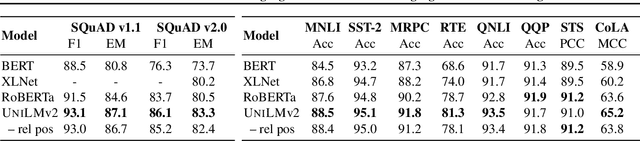
We propose to pre-train a unified language model for both autoencoding and partially autoregressive language modeling tasks using a novel training procedure, referred to as a pseudo-masked language model (PMLM). Given an input text with masked tokens, we rely on conventional masks to learn inter-relations between corrupted tokens and context via autoencoding, and pseudo masks to learn intra-relations between masked spans via partially autoregressive modeling. With well-designed position embeddings and self-attention masks, the context encodings are reused to avoid redundant computation. Moreover, conventional masks used for autoencoding provide global masking information, so that all the position embeddings are accessible in partially autoregressive language modeling. In addition, the two tasks pre-train a unified language model as a bidirectional encoder and a sequence-to-sequence decoder, respectively. Our experiments show that the unified language models pre-trained using PMLM achieve new state-of-the-art results on a wide range of natural language understanding and generation tasks across several widely used benchmarks.
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers
Feb 25, 2020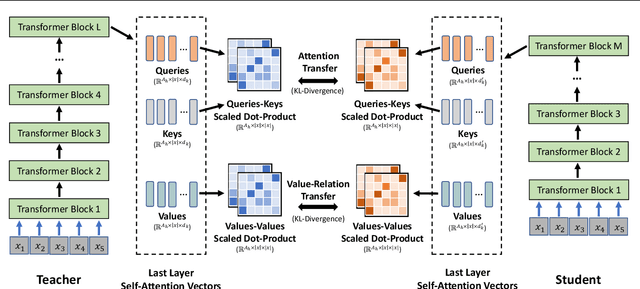
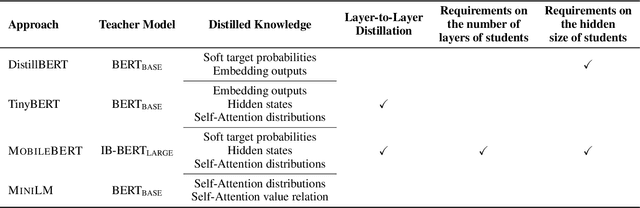

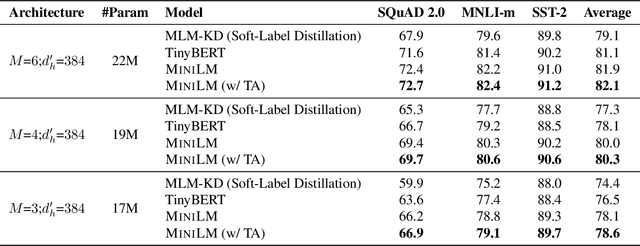
Pre-trained language models (e.g., BERT (Devlin et al., 2018) and its variants) have achieved remarkable success in varieties of NLP tasks. However, these models usually consist of hundreds of millions of parameters which brings challenges for fine-tuning and online serving in real-life applications due to latency and capacity constraints. In this work, we present a simple and effective approach to compress large Transformer (Vaswani et al., 2017) based pre-trained models, termed as deep self-attention distillation. The small model (student) is trained by deeply mimicking the self-attention module, which plays a vital role in Transformer networks, of the large model (teacher). Specifically, we propose distilling the self-attention module of the last Transformer layer of the teacher, which is effective and flexible for the student. Furthermore, we introduce the scaled dot-product between values in the self-attention module as the new deep self-attention knowledge, in addition to the attention distributions (i.e., the scaled dot-product of queries and keys) that have been used in existing works. Moreover, we show that introducing a teacher assistant (Mirzadeh et al., 2019) also helps the distillation of large pre-trained Transformer models. Experimental results demonstrate that our model outperforms state-of-the-art baselines in different parameter size of student models. In particular, it retains more than 99% accuracy on SQuAD 2.0 and several GLUE benchmark tasks using 50% of the Transformer parameters and computations of the teacher model. The code and models are publicly available at https://github.com/microsoft/unilm/tree/master/minilm
ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training
Feb 22, 2020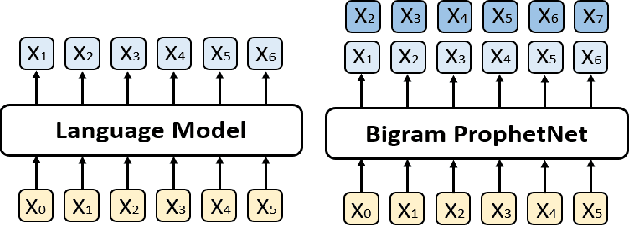
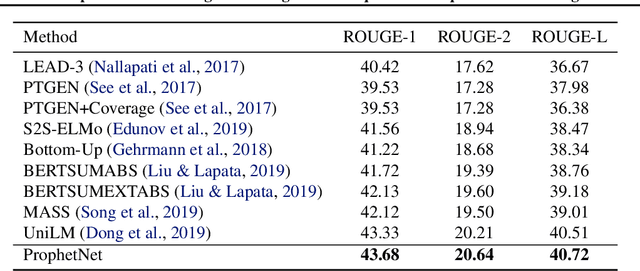
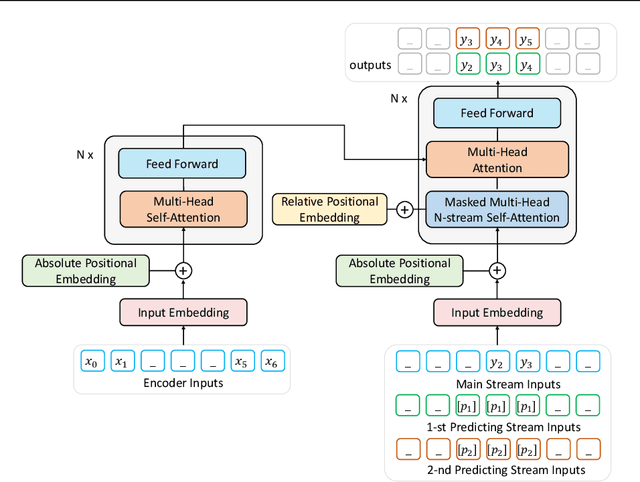
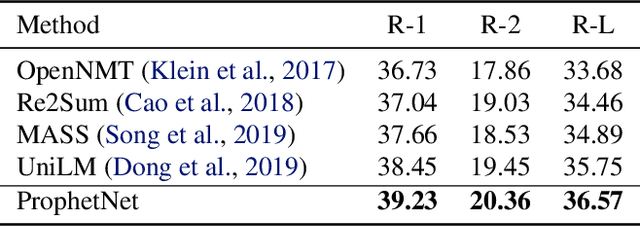
In this paper, we present a new sequence-to-sequence pre-training model called ProphetNet, which introduces a novel self-supervised objective named future n-gram prediction and the proposed n-stream self-attention mechanism. Instead of the optimization of one-step ahead prediction in traditional sequence-to-sequence model, the ProphetNet is optimized by n-step ahead prediction which predicts the next n tokens simultaneously based on previous context tokens at each time step. The future n-gram prediction explicitly encourages the model to plan for the future tokens and prevent overfitting on strong local correlations. We pre-train ProphetNet using a base scale dataset (16GB) and a large scale dataset (160GB) respectively. Then we conduct experiments on CNN/DailyMail, Gigaword, and SQuAD 1.1 benchmarks for abstractive summarization and question generation tasks. Experimental results show that ProphetNet achieves new state-of-the-art results on all these datasets compared to the models using the same scale pre-training corpus.
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
Feb 19, 2020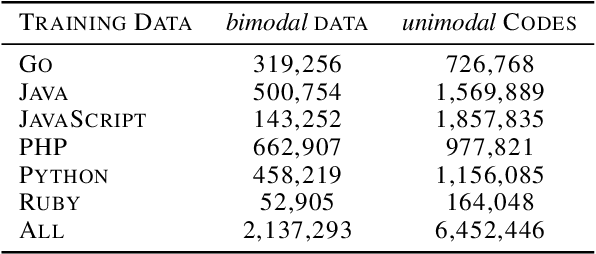

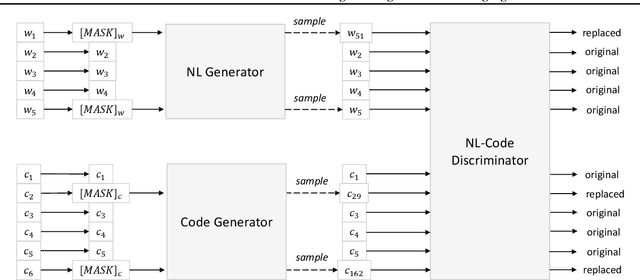
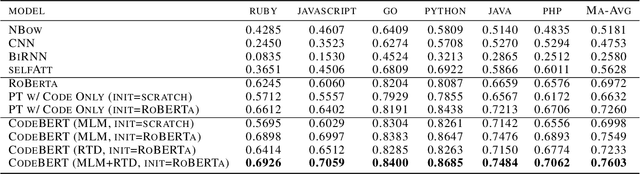
We present CodeBERT, a bimodal pre-trained model for programming language (PL) and nat-ural language (NL). CodeBERT learns general-purpose representations that support downstream NL-PL applications such as natural language codesearch, code documentation generation, etc. We develop CodeBERT with Transformer-based neural architecture, and train it with a hybrid objective function that incorporates the pre-training task of replaced token detection, which is to detect plausible alternatives sampled from generators. This enables us to utilize both bimodal data of NL-PL pairs and unimodal data, where the former provides input tokens for model training while the latter helps to learn better generators. We evaluate CodeBERT on two NL-PL applications by fine-tuning model parameters. Results show that CodeBERT achieves state-of-the-art performance on both natural language code search and code documentation generation tasks. Furthermore, to investigate what type of knowledge is learned in CodeBERT, we construct a dataset for NL-PL probing, and evaluate in a zero-shot setting where parameters of pre-trained models are fixed. Results show that CodeBERT performs better than previous pre-trained models on NL-PL probing.
LayoutLM: Pre-training of Text and Layout for Document Image Understanding
Feb 19, 2020
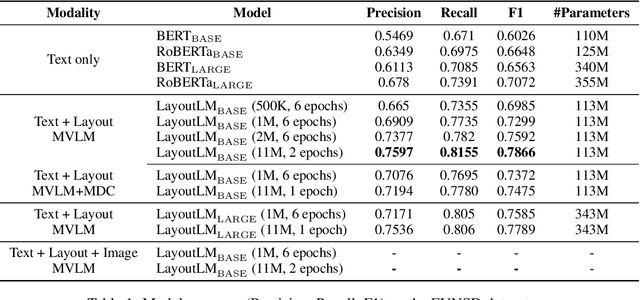
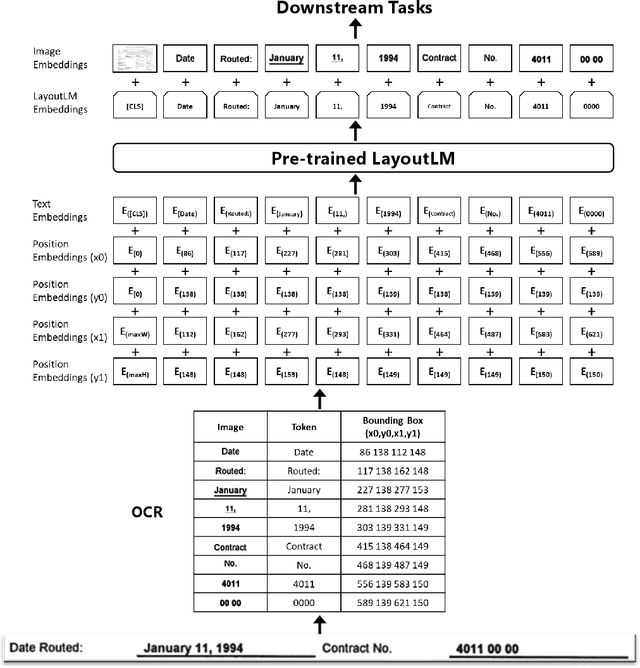
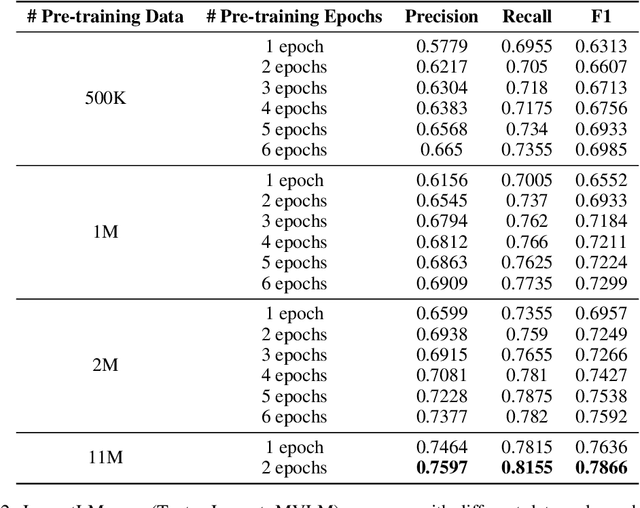
Pre-training techniques have been verified successfully in a variety of NLP tasks in recent years. Despite the widespread of pre-training models for NLP applications, they almost focused on text-level manipulation, while neglecting the layout and style information that is vital for document image understanding. In this paper, we propose the LayoutLM to jointly model the interaction between text and layout information across scanned document images, which is beneficial for a great number of real-world document image understanding tasks such as information extraction from scanned documents. Furthermore, we also leverage the image features to incorporate the visual information of words into LayoutLM. To the best of our knowledge, this is the first time that text and layout are jointly learned in a single framework for document-level pre-training. It achieves new state-of-the-art results in several downstream tasks, including form understanding (from 70.72 to 79.27), receipt understanding (from 94.02 to 95.24) and document image classification (from 93.07 to 94.42). The code and pre-trained LayoutLM models are publicly available at https://github.com/microsoft/unilm/tree/master/layoutlm.
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Feb 15, 2020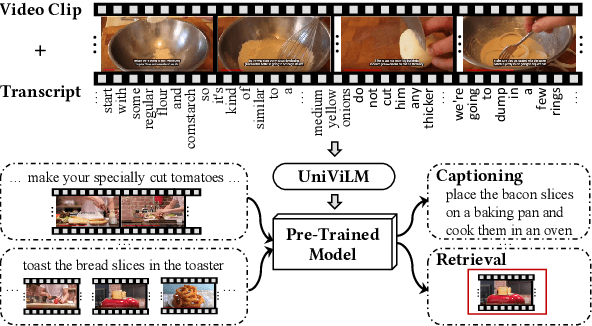
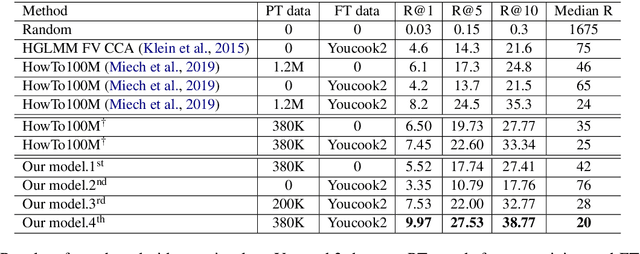
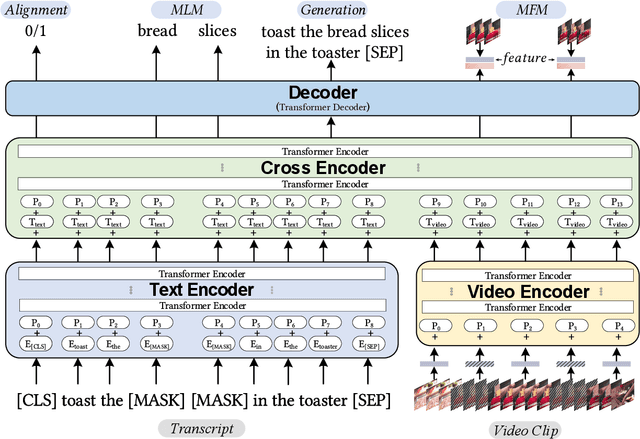
We propose UniViLM: a Unified Video and Language pre-training Model for multimodal understanding and generation. Motivated by the recent success of BERT based pre-training technique for NLP and image-language tasks, VideoBERT and CBT are proposed to exploit BERT model for video and language pre-training using narrated instructional videos. Different from their works which only pre-train understanding task, we propose a unified video-language pre-training model for both understanding and generation tasks. Our model comprises of 4 components including two single-modal encoders, a cross encoder and a decoder with the Transformer backbone. We first pre-train our model to learn the universal representation for both video and language on a large instructional video dataset. Then we fine-tune the model on two multimodal tasks including understanding task (text-based video retrieval) and generation task (multimodal video captioning). Our extensive experiments show that our method can improve the performance of both understanding and generation tasks and achieves the state-of-the art results.
Self-Adversarial Learning with Comparative Discrimination for Text Generation
Feb 12, 2020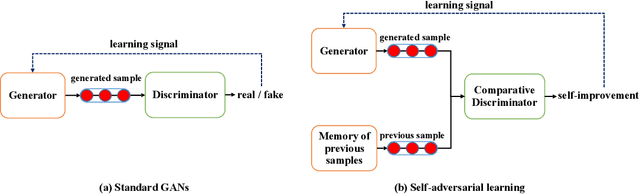
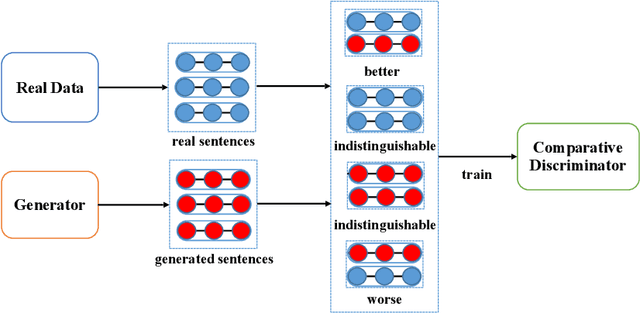
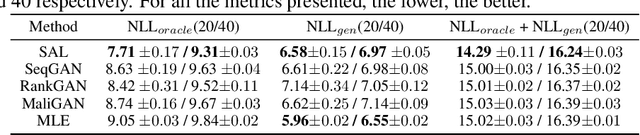
Conventional Generative Adversarial Networks (GANs) for text generation tend to have issues of reward sparsity and mode collapse that affect the quality and diversity of generated samples. To address the issues, we propose a novel self-adversarial learning (SAL) paradigm for improving GANs' performance in text generation. In contrast to standard GANs that use a binary classifier as its discriminator to predict whether a sample is real or generated, SAL employs a comparative discriminator which is a pairwise classifier for comparing the text quality between a pair of samples. During training, SAL rewards the generator when its currently generated sentence is found to be better than its previously generated samples. This self-improvement reward mechanism allows the model to receive credits more easily and avoid collapsing towards the limited number of real samples, which not only helps alleviate the reward sparsity issue but also reduces the risk of mode collapse. Experiments on text generation benchmark datasets show that our proposed approach substantially improves both the quality and the diversity, and yields more stable performance compared to the previous GANs for text generation.
BERT-of-Theseus: Compressing BERT by Progressive Module Replacing
Feb 10, 2020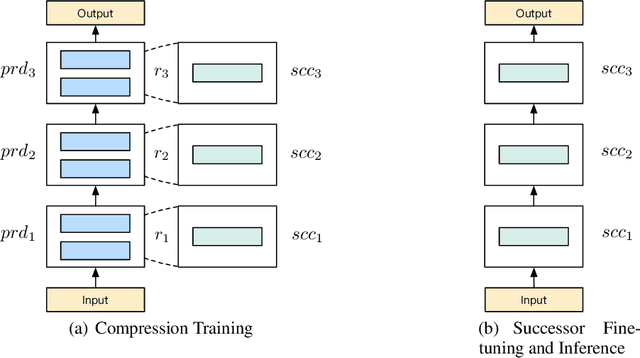

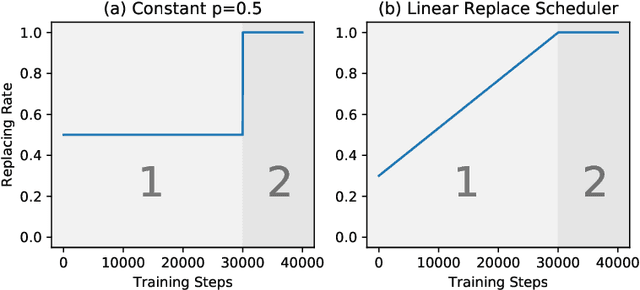
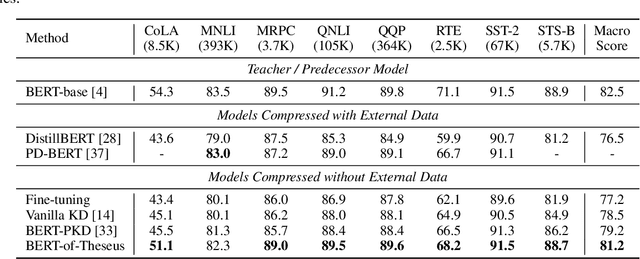
In this paper, we propose a novel model compression approach to effectively compress BERT by progressive module replacing. Our approach first divides the original BERT into several modules and builds their compact substitutes. Then, we randomly replace the original modules with their substitutes to train the compact modules to mimic the behavior of the original modules. We progressively increase the probability of replacement through the training. In this way, our approach brings a deeper level of interaction between the original and compact models, and smooths the training process. Compared to the previous knowledge distillation approaches for BERT compression, our approach leverages only one loss function and one hyper-parameter, liberating human effort from hyper-parameter tuning. Our approach outperforms existing knowledge distillation approaches on GLUE benchmark, showing a new perspective of model compression.