 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data
Mar 16, 2022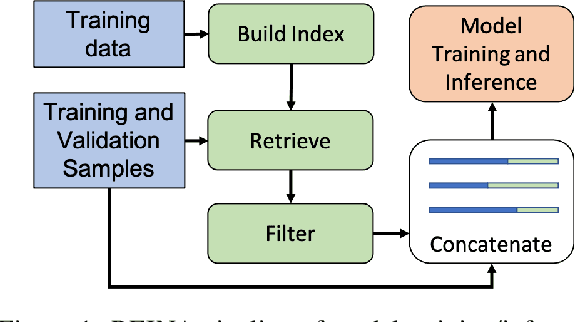
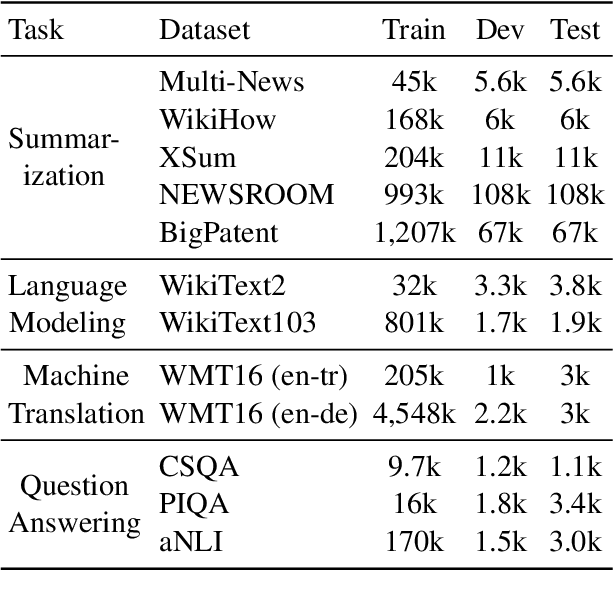
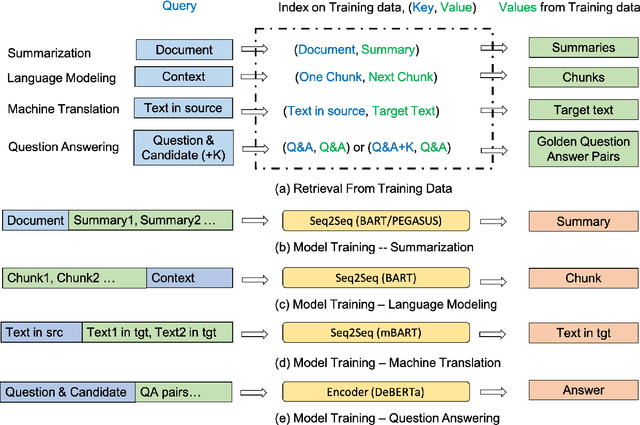
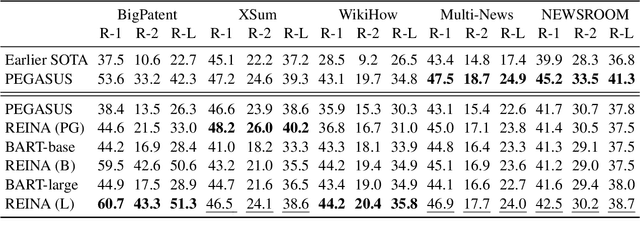
Retrieval-based methods have been shown to be effective in NLP tasks via introducing external knowledge. However, the indexing and retrieving of large-scale corpora bring considerable computational cost. Surprisingly, we found that REtrieving from the traINing datA (REINA) only can lead to significant gains on multiple NLG and NLU tasks. We retrieve the labeled training instances most similar to the input text and then concatenate them with the input to feed into the model to generate the output. Experimental results show that this simple method can achieve significantly better performance on a variety of NLU and NLG tasks, including summarization, machine translation, language modeling, and question answering tasks. For instance, our proposed method achieved state-of-the-art results on XSum, BigPatent, and CommonsenseQA. Our code is released, https://github.com/microsoft/REINA .
AdaPrompt: Adaptive Model Training for Prompt-based NLP
Feb 10, 2022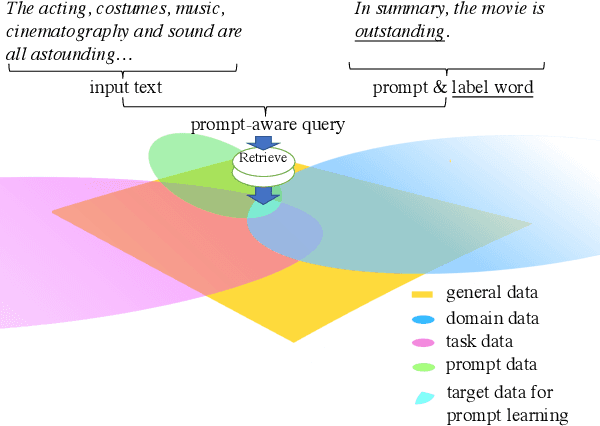

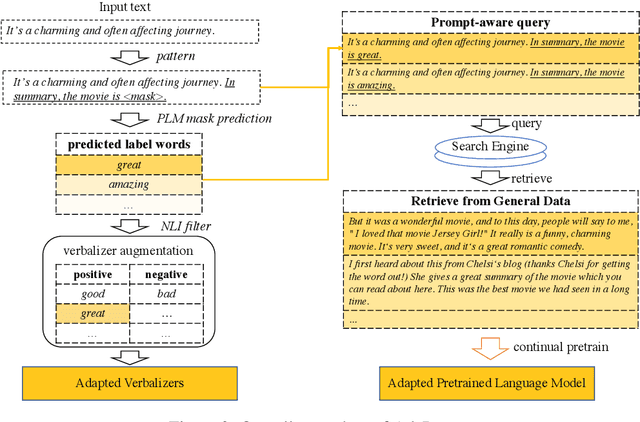
Prompt-based learning, with its capability to tackle zero-shot and few-shot NLP tasks, has gained much attention in community. The main idea is to bridge the gap between NLP downstream tasks and language modeling (LM), by mapping these tasks into natural language prompts, which are then filled by pre-trained language models (PLMs). However, for prompt learning, there are still two salient gaps between NLP tasks and pretraining. First, prompt information is not necessarily sufficiently present during LM pretraining. Second, task-specific data are not necessarily well represented during pretraining. We address these two issues by proposing AdaPrompt, adaptively retrieving external data for continual pretraining of PLMs by making use of both task and prompt characteristics. In addition, we make use of knowledge in Natural Language Inference models for deriving adaptive verbalizers. Experimental results on five NLP benchmarks show that AdaPrompt can improve over standard PLMs in few-shot settings. In addition, in zero-shot settings, our method outperforms standard prompt-based methods by up to 26.35\% relative error reduction.
Unsupervised Summarization with Customized Granularities
Jan 29, 2022
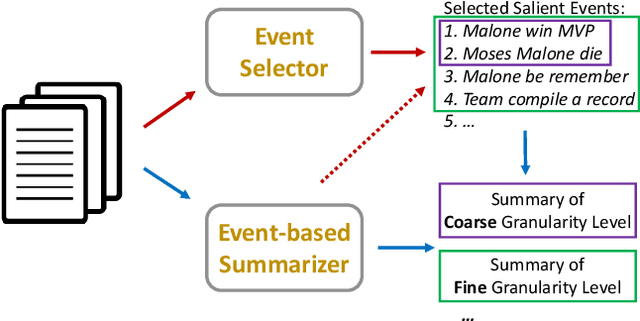


Text summarization is a personalized and customized task, i.e., for one document, users often have different preferences for the summary. As a key aspect of customization in summarization, granularity is used to measure the semantic coverage between summary and source document. Coarse-grained summaries can only contain the most central event in the original text, while fine-grained summaries cover more sub-events and corresponding details. However, previous studies mostly develop systems in the single-granularity scenario. And models that can generate summaries with customizable semantic coverage still remain an under-explored topic. In this paper, we propose the first unsupervised multi-granularity summarization framework, GranuSum. We take events as the basic semantic units of the source documents and propose to rank these events by their salience. We also develop a model to summarize input documents with given events as anchors and hints. By inputting different numbers of events, GranuSum is capable of producing multi-granular summaries in an unsupervised manner. Meanwhile, to evaluate multi-granularity summarization models, we annotate a new benchmark GranuDUC, in which we write multiple summaries of different granularities for each document cluster. Experimental results confirm the substantial superiority of GranuSum on multi-granularity summarization over several baseline systems. Furthermore, by experimenting on conventional unsupervised abstractive summarization tasks, we find that GranuSum, by exploiting the event information, can also achieve new state-of-the-art results under this scenario, outperforming strong baselines.
CLIP-Event: Connecting Text and Images with Event Structures
Jan 13, 2022
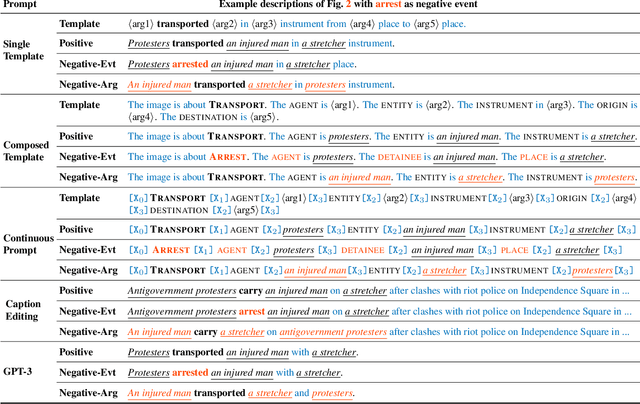
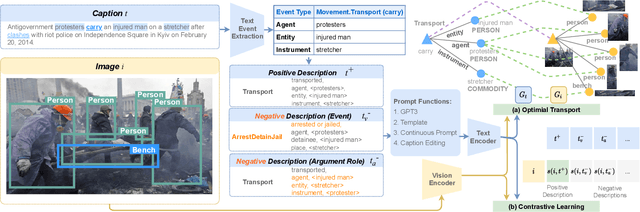

Vision-language (V+L) pretraining models have achieved great success in supporting multimedia applications by understanding the alignments between images and text. While existing vision-language pretraining models primarily focus on understanding objects in images or entities in text, they often ignore the alignment at the level of events and their argument structures. % In this work, we propose a contrastive learning framework to enforce vision-language pretraining models to comprehend events and associated argument (participant) roles. To achieve this, we take advantage of text information extraction technologies to obtain event structural knowledge, and utilize multiple prompt functions to contrast difficult negative descriptions by manipulating event structures. We also design an event graph alignment loss based on optimal transport to capture event argument structures. In addition, we collect a large event-rich dataset (106,875 images) for pretraining, which provides a more challenging image retrieval benchmark to assess the understanding of complicated lengthy sentences. Experiments show that our zero-shot CLIP-Event outperforms the state-of-the-art supervised model in argument extraction on Multimedia Event Extraction, achieving more than 5\% absolute F-score gain in event extraction, as well as significant improvements on a variety of downstream tasks under zero-shot settings.
Human Parity on CommonsenseQA: Augmenting Self-Attention with External Attention
Dec 14, 2021
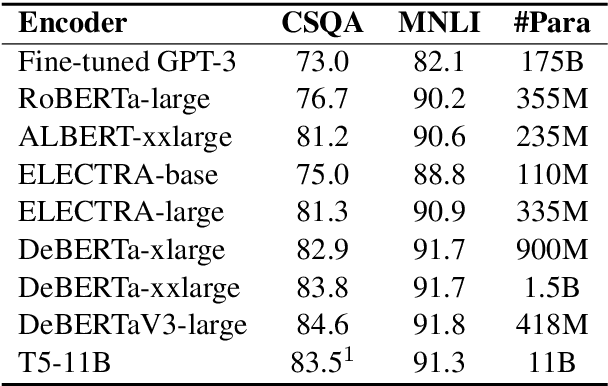
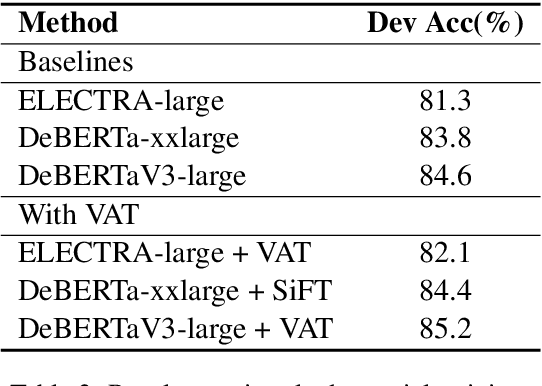

Most of today's AI systems focus on using self-attention mechanisms and transformer architectures on large amounts of diverse data to achieve impressive performance gains. In this paper, we propose to augment the transformer architecture with an external attention mechanism to bring external knowledge and context to bear. By integrating external information into the prediction process, we hope to reduce the need for ever-larger models and increase the democratization of AI systems. We find that the proposed external attention mechanism can significantly improve the performance of existing AI systems, allowing practitioners to easily customize foundation AI models to many diverse downstream applications. In particular, we focus on the task of Commonsense Reasoning, demonstrating that the proposed external attention mechanism can augment existing transformer models and significantly improve the model's reasoning capabilities. The proposed system, Knowledgeable External Attention for commonsense Reasoning (KEAR), reaches human parity on the open CommonsenseQA research benchmark with an accuracy of 89.4\% in comparison to the human accuracy of 88.9\%.
Sequence-level self-learning with multiple hypotheses
Dec 10, 2021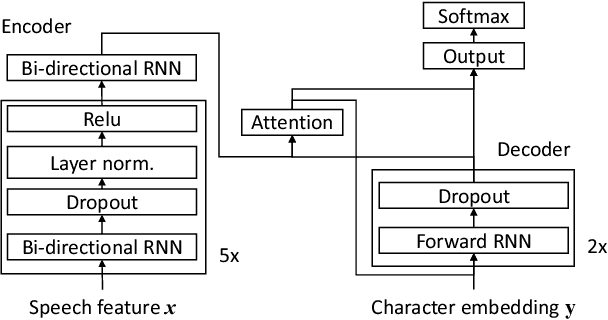
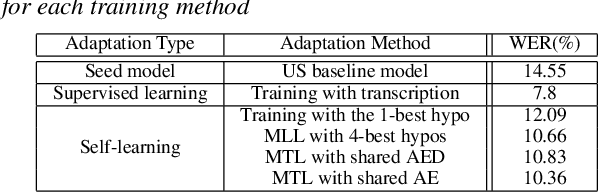
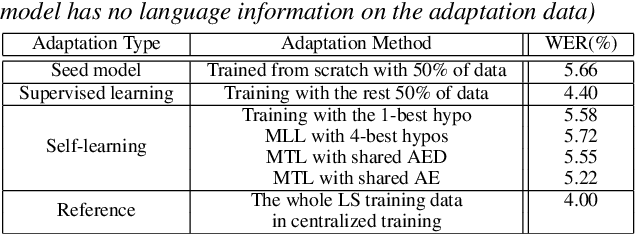
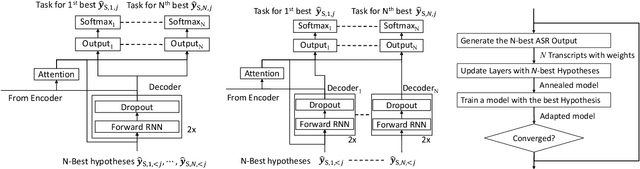
In this work, we develop new self-learning techniques with an attention-based sequence-to-sequence (seq2seq) model for automatic speech recognition (ASR). For untranscribed speech data, the hypothesis from an ASR system must be used as a label. However, the imperfect ASR result makes unsupervised learning difficult to consistently improve recognition performance especially in the case that multiple powerful teacher models are unavailable. In contrast to conventional unsupervised learning approaches, we adopt the \emph{multi-task learning} (MTL) framework where the $n$-th best ASR hypothesis is used as the label of each task. The seq2seq network is updated through the MTL framework so as to find the common representation that can cover multiple hypotheses. By doing so, the effect of the \emph{hard-decision} errors can be alleviated. We first demonstrate the effectiveness of our self-learning methods through ASR experiments in an accent adaptation task between the US and British English speech. Our experiment results show that our method can reduce the WER on the British speech data from 14.55\% to 10.36\% compared to the baseline model trained with the US English data only. Moreover, we investigate the effect of our proposed methods in a federated learning scenario.
MLP Architectures for Vision-and-Language Modeling: An Empirical Study
Dec 08, 2021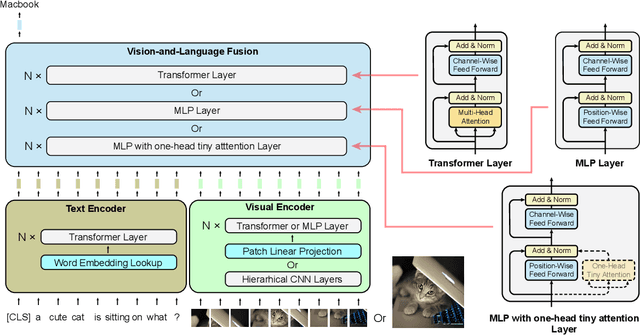
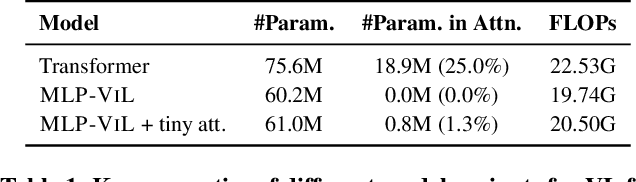
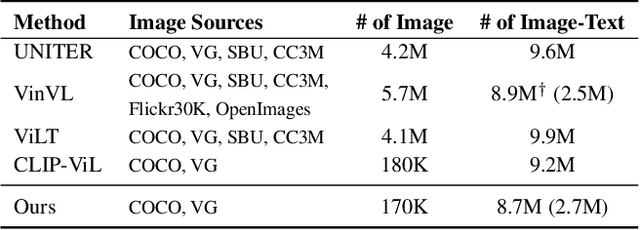
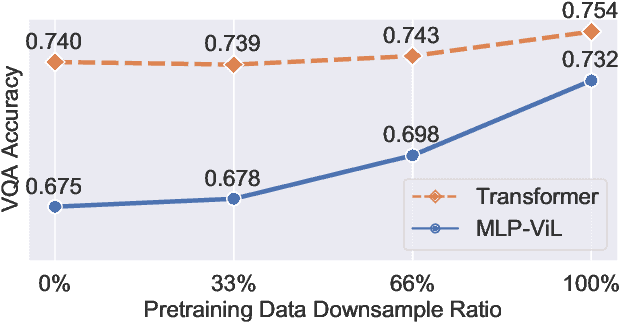
We initiate the first empirical study on the use of MLP architectures for vision-and-language (VL) fusion. Through extensive experiments on 5 VL tasks and 5 robust VQA benchmarks, we find that: (i) Without pre-training, using MLPs for multimodal fusion has a noticeable performance gap compared to transformers; (ii) However, VL pre-training can help close the performance gap; (iii) Instead of heavy multi-head attention, adding tiny one-head attention to MLPs is sufficient to achieve comparable performance to transformers. Moreover, we also find that the performance gap between MLPs and transformers is not widened when being evaluated on the harder robust VQA benchmarks, suggesting using MLPs for VL fusion can generalize roughly to a similar degree as using transformers. These results hint that MLPs can effectively learn to align vision and text features extracted from lower-level encoders without heavy reliance on self-attention. Based on this, we ask an even bolder question: can we have an all-MLP architecture for VL modeling, where both VL fusion and the vision encoder are replaced with MLPs? Our result shows that an all-MLP VL model is sub-optimal compared to state-of-the-art full-featured VL models when both of them get pre-trained. However, pre-training an all-MLP can surprisingly achieve a better average score than full-featured transformer models without pre-training. This indicates the potential of large-scale pre-training of MLP-like architectures for VL modeling and inspires the future research direction on simplifying well-established VL modeling with less inductive design bias. Our code is publicly available at: https://github.com/easonnie/mlp-vil
An Empirical Study of Training End-to-End Vision-and-Language Transformers
Nov 25, 2021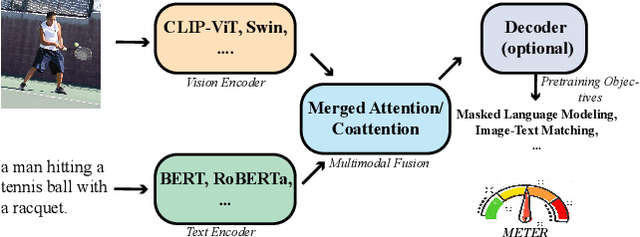

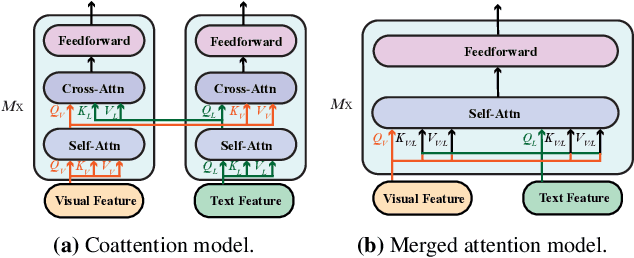

Vision-and-language (VL) pre-training has proven to be highly effective on various VL downstream tasks. While recent work has shown that fully transformer-based VL models can be more efficient than previous region-feature-based methods, their performance on downstream tasks often degrades significantly. In this paper, we present METER, a Multimodal End-to-end TransformER framework, through which we investigate how to design and pre-train a fully transformer-based VL model in an end-to-end manner. Specifically, we dissect the model designs along multiple dimensions: vision encoders (e.g., CLIPViT, Swin transformer), text encoders (e.g., RoBERTa, DeBERTa), multimodal fusion module (e.g., merged attention vs. co-attention), architectural design (e.g., encoder-only vs. encoder-decoder), and pre-training objectives (e.g., masked image modeling). We conduct comprehensive experiments and provide insights on how to train a performant VL transformer while maintaining fast inference speed. Notably, our best model achieves an accuracy of 77.64% on the VQAv2 test-std set using only 4M images for pre-training, surpassing the state-of-the-art region-feature-based model by 1.04%, and outperforming the previous best fully transformer-based model by 1.6%. Code and models are released at https://github.com/zdou0830/METER.
Florence: A New Foundation Model for Computer Vision
Nov 22, 2021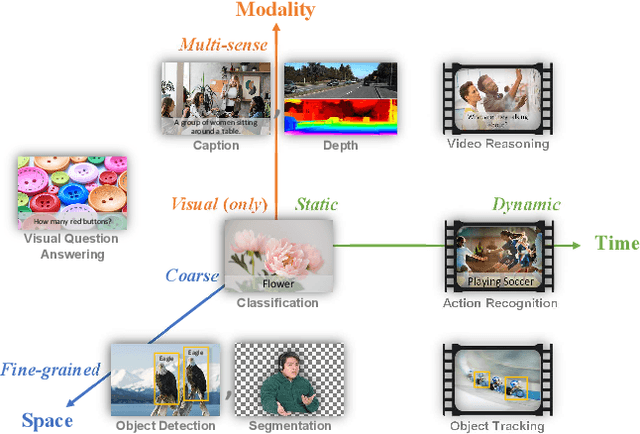
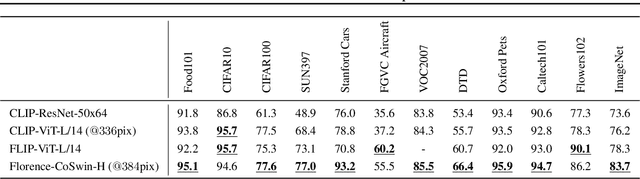
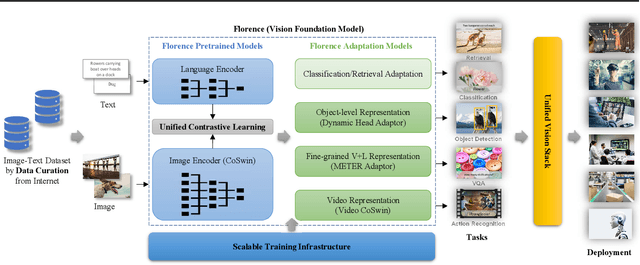
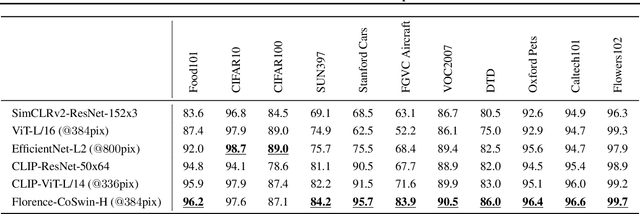
Automated visual understanding of our diverse and open world demands computer vision models to generalize well with minimal customization for specific tasks, similar to human vision. Computer vision foundation models, which are trained on diverse, large-scale dataset and can be adapted to a wide range of downstream tasks, are critical for this mission to solve real-world computer vision applications. While existing vision foundation models such as CLIP, ALIGN, and Wu Dao 2.0 focus mainly on mapping images and textual representations to a cross-modal shared representation, we introduce a new computer vision foundation model, Florence, to expand the representations from coarse (scene) to fine (object), from static (images) to dynamic (videos), and from RGB to multiple modalities (caption, depth). By incorporating universal visual-language representations from Web-scale image-text data, our Florence model can be easily adapted for various computer vision tasks, such as classification, retrieval, object detection, VQA, image caption, video retrieval and action recognition. Moreover, Florence demonstrates outstanding performance in many types of transfer learning: fully sampled fine-tuning, linear probing, few-shot transfer and zero-shot transfer for novel images and objects. All of these properties are critical for our vision foundation model to serve general purpose vision tasks. Florence achieves new state-of-the-art results in majority of 44 representative benchmarks, e.g., ImageNet-1K zero-shot classification with top-1 accuracy of 83.74 and the top-5 accuracy of 97.18, 62.4 mAP on COCO fine tuning, 80.36 on VQA, and 87.8 on Kinetics-600.
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing
Oct 29, 2021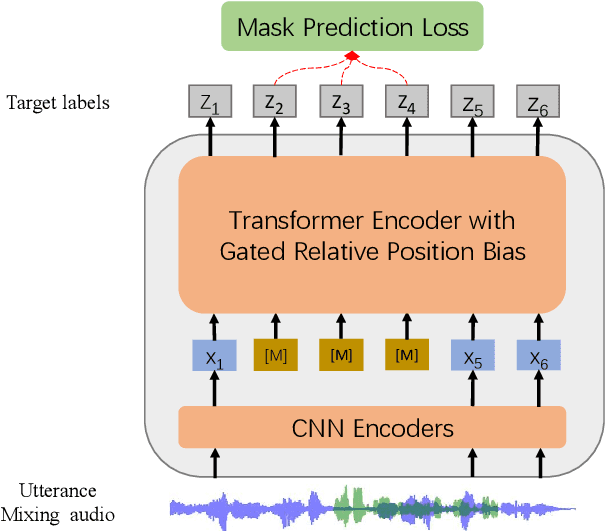
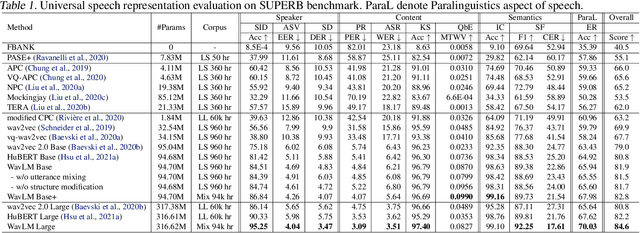
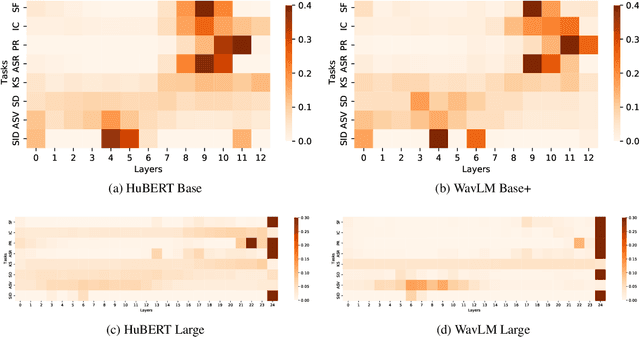
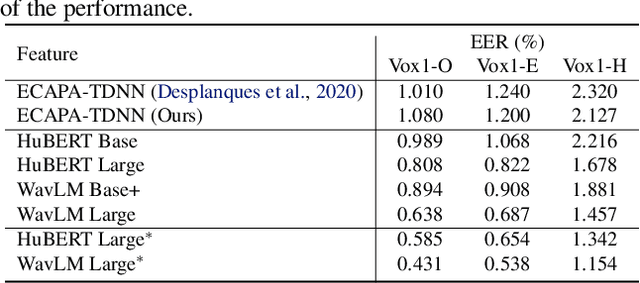
Self-supervised learning (SSL) achieves great success in speech recognition, while limited exploration has been attempted for other speech processing tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, spoken content, etc., learning universal representations for all speech tasks is challenging. In this paper, we propose a new pre-trained model, WavLM, to solve full-stack downstream speech tasks. WavLM is built based on the HuBERT framework, with an emphasis on both spoken content modeling and speaker identity preservation. We first equip the Transformer structure with gated relative position bias to improve its capability on recognition tasks. For better speaker discrimination, we propose an utterance mixing training strategy, where additional overlapped utterances are created unsupervisely and incorporated during model training. Lastly, we scale up the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks. The code and pretrained models are available at https://aka.ms/wavlm.