 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Treatment Effect Estimation with Unmeasured Confounders
May 14, 2025This paper studies the cumulative causal effects of sequential treatments in the presence of unmeasured confounders. It is a critical issue in sequential decision-making scenarios where treatment decisions and outcomes dynamically evolve over time. Advanced causal methods apply transformer as a backbone to model such time sequences, which shows superiority in capturing long time dependence and periodic patterns via attention mechanism. However, even they control the observed confounding, these estimators still suffer from unmeasured confounders, which influence both treatment assignments and outcomes. How to adjust the latent confounding bias in sequential treatment effect estimation remains an open challenge. Therefore, we propose a novel Decomposing Sequential Instrumental Variable framework for CounterFactual Regression (DSIV-CFR), relying on a common negative control assumption. Specifically, an instrumental variable (IV) is a special negative control exposure, while the previous outcome serves as a negative control outcome. This allows us to recover the IVs latent in observation variables and estimate sequential treatment effects via a generalized moment condition. We conducted experiments on 4 datasets and achieved significant performance in one- and multi-step prediction, supported by which we can identify optimal treatments for dynamic systems.
Towards Stepwise Domain Knowledge-Driven Reasoning Optimization and Reflection Improvement
Apr 12, 2025
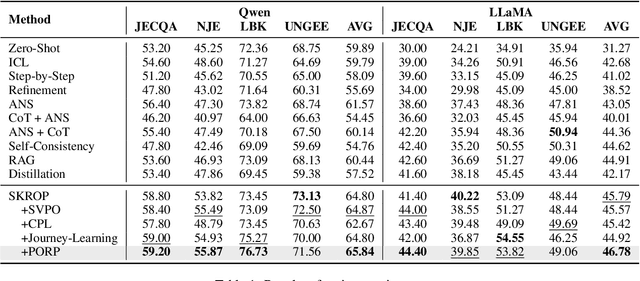
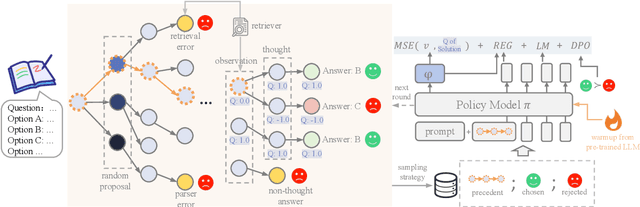
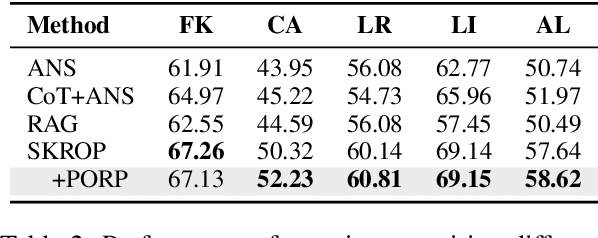
Recently, stepwise supervision on Chain of Thoughts (CoTs) presents an enhancement on the logical reasoning tasks such as coding and math, with the help of Monte Carlo Tree Search (MCTS). However, its contribution to tasks requiring domain-specific expertise and knowledge remains unexplored. Motivated by the interest, we identify several potential challenges of vanilla MCTS within this context, and propose the framework of Stepwise Domain Knowledge-Driven Reasoning Optimization, employing the MCTS algorithm to develop step-level supervision for problems that require essential comprehension, reasoning, and specialized knowledge. Additionally, we also introduce the Preference Optimization towards Reflection Paths, which iteratively learns self-reflection on the reasoning thoughts from better perspectives. We have conducted extensive experiments to evaluate the advantage of the methodologies. Empirical results demonstrate the effectiveness on various legal-domain problems. We also report a diverse set of valuable findings, hoping to encourage the enthusiasm to the research of domain-specific LLMs and MCTS.
Evaluating Test-Time Scaling LLMs for Legal Reasoning: OpenAI o1, DeepSeek-R1, and Beyond
Mar 20, 2025



Recently, Test-Time Scaling Large Language Models (LLMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated exceptional capabilities across various domains and tasks, particularly in reasoning. While these models have shown impressive performance on general language tasks, their effectiveness in specialized fields like legal remains unclear. To address this, we present a preliminary evaluation of LLMs in various legal scenarios, covering both Chinese and English legal tasks. Our analysis includes 9 LLMs and 17 legal tasks, with a focus on newly published and more complex challenges such as multi-defendant legal judgments and legal argument reasoning. Our findings indicate that, despite DeepSeek-R1 and OpenAI o1 being among the most powerful models, their legal reasoning capabilities are still lacking. Specifically, these models score below 80\% on seven Chinese legal reasoning tasks and below 80\% on two English legal reasoning tasks. This suggests that, even among the most advanced reasoning models, legal reasoning abilities remain underdeveloped.
Towards Better Alignment: Training Diffusion Models with Reinforcement Learning Against Sparse Rewards
Mar 14, 2025Diffusion models have achieved remarkable success in text-to-image generation. However, their practical applications are hindered by the misalignment between generated images and corresponding text prompts. To tackle this issue, reinforcement learning (RL) has been considered for diffusion model fine-tuning. Yet, RL's effectiveness is limited by the challenge of sparse reward, where feedback is only available at the end of the generation process. This makes it difficult to identify which actions during the denoising process contribute positively to the final generated image, potentially leading to ineffective or unnecessary denoising policies. To this end, this paper presents a novel RL-based framework that addresses the sparse reward problem when training diffusion models. Our framework, named $\text{B}^2\text{-DiffuRL}$, employs two strategies: \textbf{B}ackward progressive training and \textbf{B}ranch-based sampling. For one thing, backward progressive training focuses initially on the final timesteps of denoising process and gradually extends the training interval to earlier timesteps, easing the learning difficulty from sparse rewards. For another, we perform branch-based sampling for each training interval. By comparing the samples within the same branch, we can identify how much the policies of the current training interval contribute to the final image, which helps to learn effective policies instead of unnecessary ones. $\text{B}^2\text{-DiffuRL}$ is compatible with existing optimization algorithms. Extensive experiments demonstrate the effectiveness of $\text{B}^2\text{-DiffuRL}$ in improving prompt-image alignment and maintaining diversity in generated images. The code for this work is available.
Mix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging
Feb 13, 2025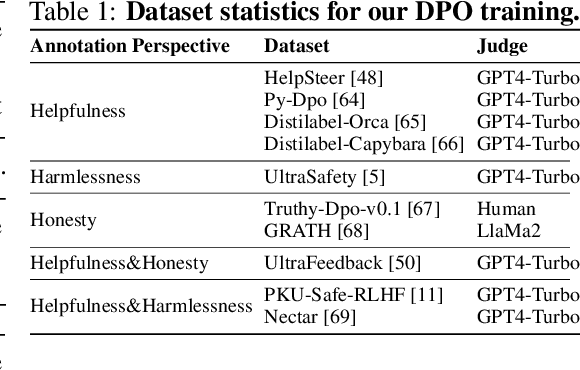
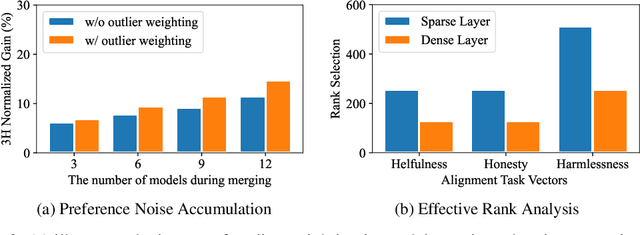
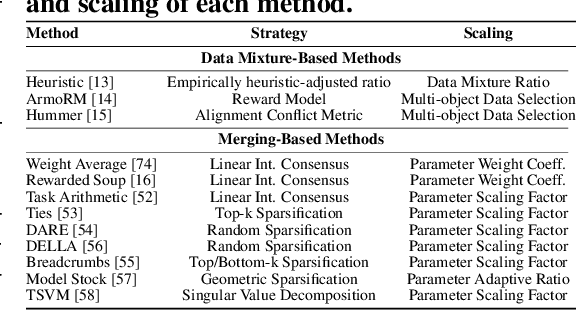
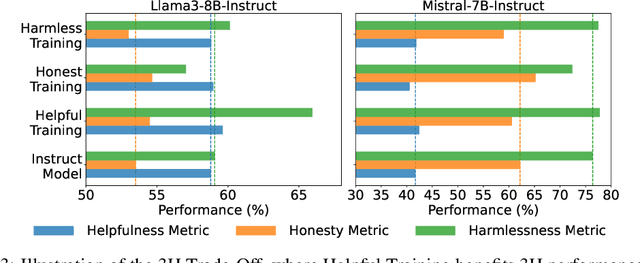
Achieving balanced alignment of large language models (LLMs) in terms of Helpfulness, Honesty, and Harmlessness (3H optimization) constitutes a cornerstone of responsible AI, with existing methods like data mixture strategies facing limitations including reliance on expert knowledge and conflicting optimization signals. While model merging offers a promising alternative by integrating specialized models, its potential for 3H optimization remains underexplored. This paper establishes the first comprehensive benchmark for model merging in 3H-aligned LLMs, systematically evaluating 15 methods (12 training-free merging and 3 data mixture techniques) across 10 datasets associated with 5 annotation dimensions, 2 LLM families, and 2 training paradigms. Our analysis reveals three pivotal insights: (i) previously overlooked collaborative/conflicting relationships among 3H dimensions, (ii) the consistent superiority of model merging over data mixture approaches in balancing alignment trade-offs, and (iii) the critical role of parameter-level conflict resolution through redundant component pruning and outlier mitigation. Building on these findings, we propose R-TSVM, a Reweighting-enhanced Task Singular Vector Merging method that incorporates outlier-aware parameter weighting and sparsity-adaptive rank selection strategies adapted to the heavy-tailed parameter distribution and sparsity for LLMs, further improving LLM alignment across multiple evaluations. We release our trained models for further exploration.
Each Rank Could be an Expert: Single-Ranked Mixture of Experts LoRA for Multi-Task Learning
Jan 25, 2025



Low-Rank Adaptation (LoRA) is widely used for adapting large language models (LLMs) to specific domains due to its efficiency and modularity. Meanwhile, vanilla LoRA struggles with task conflicts in multi-task scenarios. Recent works adopt Mixture of Experts (MoE) by treating each LoRA module as an expert, thereby mitigating task interference through multiple specialized LoRA modules. While effective, these methods often isolate knowledge within individual tasks, failing to fully exploit the shared knowledge across related tasks. In this paper, we establish a connection between single LoRA and multi-LoRA MoE, integrating them into a unified framework. We demonstrate that the dynamic routing of multiple LoRAs is functionally equivalent to rank partitioning and block-level activation within a single LoRA. We further empirically demonstrate that finer-grained LoRA partitioning, within the same total and activated parameter constraints, leads to better performance gains across heterogeneous tasks. Building on these findings, we propose Single-ranked Mixture of Experts LoRA (\textbf{SMoRA}), which embeds MoE into LoRA by \textit{treating each rank as an independent expert}. With a \textit{dynamic rank-wise activation} mechanism, SMoRA promotes finer-grained knowledge sharing while mitigating task conflicts. Experiments demonstrate that SMoRA activates fewer parameters yet achieves better performance in multi-task scenarios.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
Optimize Incompatible Parameters through Compatibility-aware Knowledge Integration
Jan 10, 2025



Deep neural networks have become foundational to advancements in multiple domains, including recommendation systems, natural language processing, and so on. Despite their successes, these models often contain incompatible parameters that can be underutilized or detrimental to model performance, particularly when faced with specific, varying data distributions. Existing research excels in removing such parameters or merging the outputs of multiple different pretrained models. However, the former focuses on efficiency rather than performance, while the latter requires several times more computing and storage resources to support inference. In this paper, we set the goal to explicitly improve these incompatible parameters by leveraging the complementary strengths of different models, thereby directly enhancing the models without any additional parameters. Specifically, we propose Compatibility-aware Knowledge Integration (CKI), which consists of Parameter Compatibility Assessment and Parameter Splicing, which are used to evaluate the knowledge content of multiple models and integrate the knowledge into one model, respectively. The integrated model can be used directly for inference or for further fine-tuning. We conduct extensive experiments on various datasets for recommendation and language tasks, and the results show that Compatibility-aware Knowledge Integration can effectively optimize incompatible parameters under multiple tasks and settings to break through the training limit of the original model without increasing the inference cost.
Collaboration of Large Language Models and Small Recommendation Models for Device-Cloud Recommendation
Jan 10, 2025Large Language Models (LLMs) for Recommendation (LLM4Rec) is a promising research direction that has demonstrated exceptional performance in this field. However, its inability to capture real-time user preferences greatly limits the practical application of LLM4Rec because (i) LLMs are costly to train and infer frequently, and (ii) LLMs struggle to access real-time data (its large number of parameters poses an obstacle to deployment on devices). Fortunately, small recommendation models (SRMs) can effectively supplement these shortcomings of LLM4Rec diagrams by consuming minimal resources for frequent training and inference, and by conveniently accessing real-time data on devices. In light of this, we designed the Device-Cloud LLM-SRM Collaborative Recommendation Framework (LSC4Rec) under a device-cloud collaboration setting. LSC4Rec aims to integrate the advantages of both LLMs and SRMs, as well as the benefits of cloud and edge computing, achieving a complementary synergy. We enhance the practicability of LSC4Rec by designing three strategies: collaborative training, collaborative inference, and intelligent request. During training, LLM generates candidate lists to enhance the ranking ability of SRM in collaborative scenarios and enables SRM to update adaptively to capture real-time user interests. During inference, LLM and SRM are deployed on the cloud and on the device, respectively. LLM generates candidate lists and initial ranking results based on user behavior, and SRM get reranking results based on the candidate list, with final results integrating both LLM's and SRM's scores. The device determines whether a new candidate list is needed by comparing the consistency of the LLM's and SRM's sorted lists. Our comprehensive and extensive experimental analysis validates the effectiveness of each strategy in LSC4Rec.
Forward Once for All: Structural Parameterized Adaptation for Efficient Cloud-coordinated On-device Recommendation
Jan 06, 2025



In cloud-centric recommender system, regular data exchanges between user devices and cloud could potentially elevate bandwidth demands and privacy risks. On-device recommendation emerges as a viable solution by performing reranking locally to alleviate these concerns. Existing methods primarily focus on developing local adaptive parameters, while potentially neglecting the critical role of tailor-made model architecture. Insights from broader research domains suggest that varying data distributions might favor distinct architectures for better fitting. In addition, imposing a uniform model structure across heterogeneous devices may result in risking inefficacy on less capable devices or sub-optimal performance on those with sufficient capabilities. In response to these gaps, our paper introduces Forward-OFA, a novel approach for the dynamic construction of device-specific networks (both structure and parameters). Forward-OFA employs a structure controller to selectively determine whether each block needs to be assembled for a given device. However, during the training of the structure controller, these assembled heterogeneous structures are jointly optimized, where the co-adaption among blocks might encounter gradient conflicts. To mitigate this, Forward-OFA is designed to establish a structure-guided mapping of real-time behaviors to the parameters of assembled networks. Structure-related parameters and parallel components within the mapper prevent each part from receiving heterogeneous gradients from others, thus bypassing the gradient conflicts for coupled optimization. Besides, direct mapping enables Forward-OFA to achieve adaptation through only one forward pass, allowing for swift adaptation to changing interests and eliminating the requirement for on-device backpropagation. Experiments on real-world datasets demonstrate the effectiveness and efficiency of Forward-OFA.