 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-Brain-0: Spatial Intelligence as a Shared Scaffold for Universal Embodiments
Mar 03, 2026Universal embodied intelligence demands robust generalization across heterogeneous embodiments, such as autonomous driving, robotics, and unmanned aerial vehicles (UAVs). However, existing embodied brain in training a unified model over diverse embodiments frequently triggers long-tail data, gradient interference, and catastrophic forgetting, making it notoriously difficult to balance universal generalization with domain-specific proficiency. In this report, we introduce ACE-Brain-0, a generalist foundation brain that unifies spatial reasoning, autonomous driving, and embodied manipulation within a single multimodal large language model~(MLLM). Our key insight is that spatial intelligence serves as a universal scaffold across diverse physical embodiments: although vehicles, robots, and UAVs differ drastically in morphology, they share a common need for modeling 3D mental space, making spatial cognition a natural, domain-agnostic foundation for cross-embodiment transfer. Building on this insight, we propose the Scaffold-Specialize-Reconcile~(SSR) paradigm, which first establishes a shared spatial foundation, then cultivates domain-specialized experts, and finally harmonizes them through data-free model merging. Furthermore, we adopt Group Relative Policy Optimization~(GRPO) to strengthen the model's comprehensive capability. Extensive experiments demonstrate that ACE-Brain-0 achieves competitive and even state-of-the-art performance across 24 spatial and embodiment-related benchmarks.
Understanding Model Merging: A Unified Generalization Framework for Heterogeneous Experts
Jan 29, 2026Model merging efficiently aggregates capabilities from multiple fine-tuned models into a single one, operating purely in parameter space without original data or expensive re-computation. Despite empirical successes, a unified theory for its effectiveness under heterogeneous finetuning hyperparameters (e.g., varying learning rates, batch sizes) remains missing. Moreover, the lack of hyperparameter transparency in open-source fine-tuned models makes it difficult to predict merged-model performance, leaving practitioners without guidance on how to fine-tune merge-friendly experts. To address those two challenges, we employ $L_2$-Stability theory under heterogeneous hyperparameter environments to analyze the generalization of the merged model $\boldsymbol{x}_{avg}$. This pioneering analysis yields two key contributions: (i) \textit{A unified theoretical framework} is provided to explain existing merging algorithms, revealing how they optimize specific terms in our bound, thus offering a strong theoretical foundation for empirical observations. (ii) \textit{Actionable recommendations} are proposed for practitioners to strategically fine-tune expert models, enabling the construction of merge-friendly models within the pretraining-to-finetuning pipeline. Extensive experiments on the ResNet/Vit family across 20/8 visual classification tasks, involving thousands of finetuning models, robustly confirm the impact of different hyperparameters on the generalization of $\boldsymbol{x}_{avg}$ predicted by our theoretical results.
Mix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging
Feb 13, 2025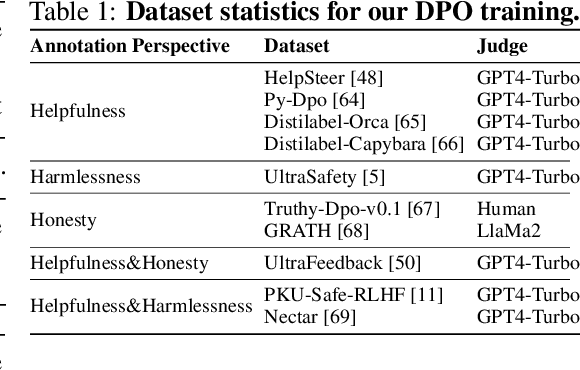
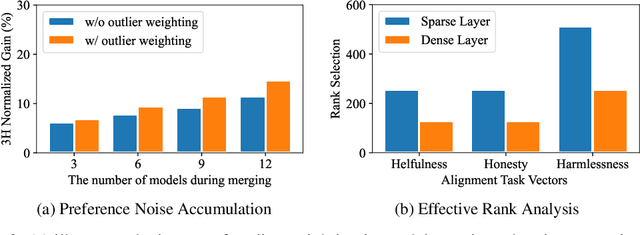
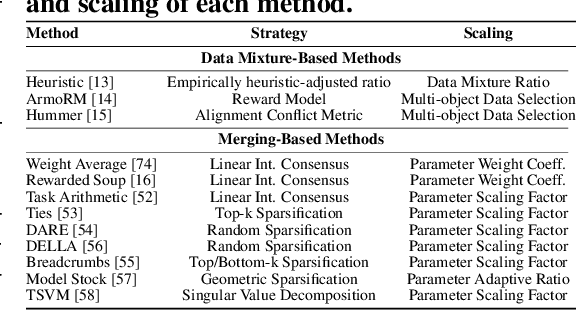
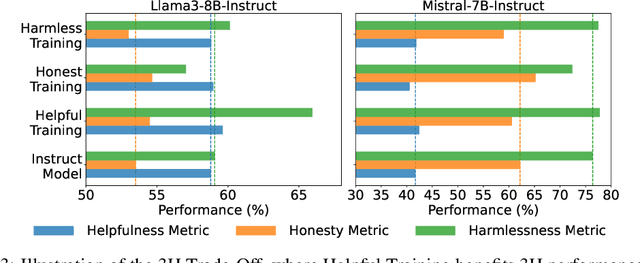
Achieving balanced alignment of large language models (LLMs) in terms of Helpfulness, Honesty, and Harmlessness (3H optimization) constitutes a cornerstone of responsible AI, with existing methods like data mixture strategies facing limitations including reliance on expert knowledge and conflicting optimization signals. While model merging offers a promising alternative by integrating specialized models, its potential for 3H optimization remains underexplored. This paper establishes the first comprehensive benchmark for model merging in 3H-aligned LLMs, systematically evaluating 15 methods (12 training-free merging and 3 data mixture techniques) across 10 datasets associated with 5 annotation dimensions, 2 LLM families, and 2 training paradigms. Our analysis reveals three pivotal insights: (i) previously overlooked collaborative/conflicting relationships among 3H dimensions, (ii) the consistent superiority of model merging over data mixture approaches in balancing alignment trade-offs, and (iii) the critical role of parameter-level conflict resolution through redundant component pruning and outlier mitigation. Building on these findings, we propose R-TSVM, a Reweighting-enhanced Task Singular Vector Merging method that incorporates outlier-aware parameter weighting and sparsity-adaptive rank selection strategies adapted to the heavy-tailed parameter distribution and sparsity for LLMs, further improving LLM alignment across multiple evaluations. We release our trained models for further exploration.
Merging Models on the Fly Without Retraining: A Sequential Approach to Scalable Continual Model Merging
Jan 16, 2025



Deep model merging represents an emerging research direction that combines multiple fine-tuned models to harness their specialized capabilities across different tasks and domains. Current model merging techniques focus on merging all available models simultaneously, with weight interpolation-based methods being the predominant approaches. However, these conventional approaches are not well-suited for scenarios where models become available sequentially, and they often suffer from high memory requirements and potential interference between tasks. In this study, we propose a training-free projection-based continual merging method that processes models sequentially through orthogonal projections of weight matrices and adaptive scaling mechanisms. Our method operates by projecting new parameter updates onto subspaces orthogonal to existing merged parameter updates while using an adaptive scaling mechanism to maintain stable parameter distances, enabling efficient sequential integration of task-specific knowledge. Our approach maintains constant memory complexity to the number of models, minimizes interference between tasks through orthogonal projections, and retains the performance of previously merged models through adaptive task vector scaling. Extensive experiments on CLIP-ViT models demonstrate that our method achieves a 5-8% average accuracy improvement while maintaining robust performance in different task orderings.
Modeling Multi-Task Model Merging as Adaptive Projective Gradient Descent
Jan 02, 2025



Merging multiple expert models offers a promising approach for performing multi-task learning without accessing their original data. Existing methods attempt to alleviate task conflicts by sparsifying task vectors or promoting orthogonality among them. However, they overlook the fundamental requirement of model merging: ensuring the merged model performs comparably to task-specific models on respective tasks. We find these methods inevitably discard task-specific information that, while causing conflicts, is crucial for performance. Based on our findings, we frame model merging as a constrained optimization problem ($\textit{i.e.}$, minimizing the gap between the merged model and individual models, subject to the constraint of retaining shared knowledge) and solve it via adaptive projective gradient descent. Specifically, we align the merged model with individual models by decomposing and reconstituting the loss function, alleviating conflicts through $\textit{data-free}$ optimization of task vectors. To retain shared knowledge, we optimize this objective by projecting gradients within a $\textit{shared subspace}$ spanning all tasks. Moreover, we view merging coefficients as adaptive learning rates and propose a task-aware, training-free strategy. Experiments show that our plug-and-play approach consistently outperforms previous methods, achieving state-of-the-art results across diverse architectures and tasks in both vision and NLP domains.
Efficient and Effective Weight-Ensembling Mixture of Experts for Multi-Task Model Merging
Oct 29, 2024Multi-task learning (MTL) leverages a shared model to accomplish multiple tasks and facilitate knowledge transfer. Recent research on task arithmetic-based MTL demonstrates that merging the parameters of independently fine-tuned models can effectively achieve MTL. However, existing merging methods primarily seek a static optimal solution within the original model parameter space, which often results in performance degradation due to the inherent diversity among tasks and potential interferences. To address this challenge, in this paper, we propose a Weight-Ensembling Mixture of Experts (WEMoE) method for multi-task model merging. Specifically, we first identify critical (or sensitive) modules by analyzing parameter variations in core modules of Transformer-based models before and after finetuning. Then, our WEMoE statically merges non-critical modules while transforming critical modules into a mixture-of-experts (MoE) structure. During inference, expert modules in the MoE are dynamically merged based on input samples, enabling a more flexible and adaptive merging approach. Building on WEMoE, we further introduce an efficient-and-effective WEMoE (E-WEMoE) method, whose core mechanism involves eliminating non-essential elements in the critical modules of WEMoE and implementing shared routing across multiple MoE modules, thereby significantly reducing both the trainable parameters, the overall parameter count, and computational overhead of the merged model by WEMoE. Experimental results across various architectures and tasks demonstrate that both WEMoE and E-WEMoE outperform state-of-the-art (SOTA) model merging methods in terms of MTL performance, generalization, and robustness.
Mitigating the Backdoor Effect for Multi-Task Model Merging via Safety-Aware Subspace
Oct 17, 2024



Model merging has gained significant attention as a cost-effective approach to integrate multiple single-task fine-tuned models into a unified one that can perform well on multiple tasks. However, existing model merging techniques primarily focus on resolving conflicts between task-specific models, they often overlook potential security threats, particularly the risk of backdoor attacks in the open-source model ecosystem. In this paper, we first investigate the vulnerabilities of existing model merging methods to backdoor attacks, identifying two critical challenges: backdoor succession and backdoor transfer. To address these issues, we propose a novel Defense-Aware Merging (DAM) approach that simultaneously mitigates task interference and backdoor vulnerabilities. Specifically, DAM employs a meta-learning-based optimization method with dual masks to identify a shared and safety-aware subspace for model merging. These masks are alternately optimized: the Task-Shared mask identifies common beneficial parameters across tasks, aiming to preserve task-specific knowledge while reducing interference, while the Backdoor-Detection mask isolates potentially harmful parameters to neutralize security threats. This dual-mask design allows us to carefully balance the preservation of useful knowledge and the removal of potential vulnerabilities. Compared to existing merging methods, DAM achieves a more favorable balance between performance and security, reducing the attack success rate by 2-10 percentage points while sacrificing only about 1% in accuracy. Furthermore, DAM exhibits robust performance and broad applicability across various types of backdoor attacks and the number of compromised models involved in the merging process. We will release the codes and models soon.
SMILE: Zero-Shot Sparse Mixture of Low-Rank Experts Construction From Pre-Trained Foundation Models
Aug 19, 2024



Deep model training on extensive datasets is increasingly becoming cost-prohibitive, prompting the widespread adoption of deep model fusion techniques to leverage knowledge from pre-existing models. From simple weight averaging to more sophisticated methods like AdaMerging, model fusion effectively improves model performance and accelerates the development of new models. However, potential interference between parameters of individual models and the lack of interpretability in the fusion progress remain significant challenges. Existing methods often try to resolve the parameter interference issue by evaluating attributes of parameters, such as their magnitude or sign, or by parameter pruning. In this study, we begin by examining the fine-tuning of linear layers through the lens of subspace analysis and explicitly define parameter interference as an optimization problem to shed light on this subject. Subsequently, we introduce an innovative approach to model fusion called zero-shot Sparse MIxture of Low-rank Experts (SMILE) construction, which allows for the upscaling of source models into an MoE model without extra data or further training. Our approach relies on the observation that fine-tuning mostly keeps the important parts from the pre-training, but it uses less significant or unused areas to adapt to new tasks. Also, the issue of parameter interference, which is intrinsically intractable in the original parameter space, can be managed by expanding the dimensions. We conduct extensive experiments across diverse scenarios, such as image classification and text generalization tasks, using full fine-tuning and LoRA fine-tuning, and we apply our method to large language models (CLIP models, Flan-T5 models, and Mistral-7B models), highlighting the adaptability and scalability of SMILE. Code is available at https://github.com/tanganke/fusion_bench
Towards Efficient Pareto Set Approximation via Mixture of Experts Based Model Fusion
Jun 14, 2024Solving multi-objective optimization problems for large deep neural networks is a challenging task due to the complexity of the loss landscape and the expensive computational cost of training and evaluating models. Efficient Pareto front approximation of large models enables multi-objective optimization for various tasks such as multi-task learning and trade-off analysis. Existing algorithms for learning Pareto set, including (1) evolutionary, hypernetworks, and hypervolume-maximization methods, are computationally expensive and have restricted scalability to large models; (2) Scalarization algorithms, where a separate model is trained for each objective ray, which is inefficient for learning the entire Pareto set and fails to capture the objective trade-offs effectively. Inspired by the recent success of model merging, we propose a practical and scalable approach to Pareto set learning problem via mixture of experts (MoE) based model fusion. By ensembling the weights of specialized single-task models, the MoE module can effectively capture the trade-offs between multiple objectives and closely approximate the entire Pareto set of large neural networks. Once the routers are learned and a preference vector is set, the MoE module can be unloaded, thus no additional computational cost is introduced during inference. We conduct extensive experiments on vision and language tasks using large-scale models such as CLIP-ViT and GPT-2. The experimental results demonstrate that our method efficiently approximates the entire Pareto front of large models. Using only hundreds of trainable parameters of the MoE routers, our method even has lower memory usage compared to linear scalarization and algorithms that learn a single Pareto optimal solution, and are scalable to both the number of objectives and the size of the model.
FusionBench: A Comprehensive Benchmark of Deep Model Fusion
Jun 07, 2024Deep model fusion is an emerging technique that unifies the predictions or parameters of several deep neural networks into a single model in a cost-effective and data-efficient manner. This enables the unified model to take advantage of the original models' strengths, potentially exceeding their performance. Although a variety of deep model fusion techniques have been introduced, their evaluations tend to be inconsistent and often inadequate to validate their effectiveness and robustness against distribution shifts. To address this issue, we introduce FusionBench, which is the first comprehensive benchmark dedicated to deep model fusion. FusionBench covers a wide range of tasks, including open-vocabulary image classification, text classification, and text-to-text generation. Each category includes up to eight tasks with corresponding task-specific models, featuring both full fine-tuning and LoRA fine-tuning, as well as models of different sizes, to ensure fair and balanced comparisons of various multi-task model fusion techniques across different tasks, model scales, and fine-tuning strategies. We implement and evaluate a broad spectrum of deep model fusion techniques. These techniques range from model ensemble methods, which combine the predictions to improve the overall performance, to model merging, which integrates different models into a single one, and model mixing methods, which upscale or recombine the components of the original models. FusionBench now contains 26 distinct tasks, 74 fine-tuned models, and 16 fusion techniques, and we are committed to consistently expanding the benchmark with more tasks, models, and fusion techniques. In addition, we offer a well-documented set of resources and guidelines to aid researchers in understanding and replicating the benchmark results. Homepage https://github.com/tanganke/fusion_bench