 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise Projection: Closing the Prompt-Agnostic Gap Behind Text-to-Image Misalignment in Diffusion Models
Oct 16, 2025In text-to-image generation, different initial noises induce distinct denoising paths with a pretrained Stable Diffusion (SD) model. While this pattern could output diverse images, some of them may fail to align well with the prompt. Existing methods alleviate this issue either by altering the denoising dynamics or by drawing multiple noises and conducting post-selection. In this paper, we attribute the misalignment to a training-inference mismatch: during training, prompt-conditioned noises lie in a prompt-specific subset of the latent space, whereas at inference the noise is drawn from a prompt-agnostic Gaussian prior. To close this gap, we propose a noise projector that applies text-conditioned refinement to the initial noise before denoising. Conditioned on the prompt embedding, it maps the noise to a prompt-aware counterpart that better matches the distribution observed during SD training, without modifying the SD model. Our framework consists of these steps: we first sample some noises and obtain token-level feedback for their corresponding images from a vision-language model (VLM), then distill these signals into a reward model, and finally optimize the noise projector via a quasi-direct preference optimization. Our design has two benefits: (i) it requires no reference images or handcrafted priors, and (ii) it incurs small inference cost, replacing multi-sample selection with a single forward pass. Extensive experiments further show that our prompt-aware noise projection improves text-image alignment across diverse prompts.
Asynchronous Denoising Diffusion Models for Aligning Text-to-Image Generation
Oct 06, 2025Diffusion models have achieved impressive results in generating high-quality images. Yet, they often struggle to faithfully align the generated images with the input prompts. This limitation arises from synchronous denoising, where all pixels simultaneously evolve from random noise to clear images. As a result, during generation, the prompt-related regions can only reference the unrelated regions at the same noise level, failing to obtain clear context and ultimately impairing text-to-image alignment. To address this issue, we propose asynchronous diffusion models -- a novel framework that allocates distinct timesteps to different pixels and reformulates the pixel-wise denoising process. By dynamically modulating the timestep schedules of individual pixels, prompt-related regions are denoised more gradually than unrelated regions, thereby allowing them to leverage clearer inter-pixel context. Consequently, these prompt-related regions achieve better alignment in the final images. Extensive experiments demonstrate that our asynchronous diffusion models can significantly improve text-to-image alignment across diverse prompts. The code repository for this work is available at https://github.com/hu-zijing/AsynDM.
D-Fusion: Direct Preference Optimization for Aligning Diffusion Models with Visually Consistent Samples
May 28, 2025
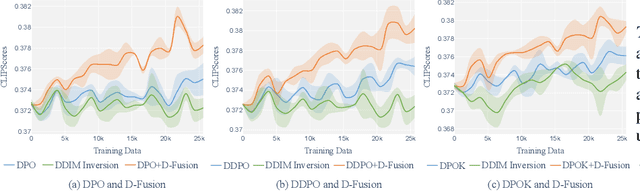
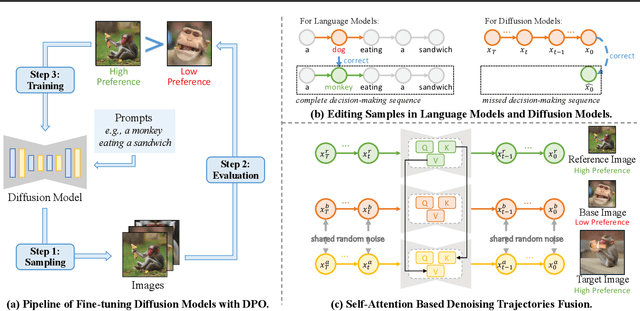
The practical applications of diffusion models have been limited by the misalignment between generated images and corresponding text prompts. Recent studies have introduced direct preference optimization (DPO) to enhance the alignment of these models. However, the effectiveness of DPO is constrained by the issue of visual inconsistency, where the significant visual disparity between well-aligned and poorly-aligned images prevents diffusion models from identifying which factors contribute positively to alignment during fine-tuning. To address this issue, this paper introduces D-Fusion, a method to construct DPO-trainable visually consistent samples. On one hand, by performing mask-guided self-attention fusion, the resulting images are not only well-aligned, but also visually consistent with given poorly-aligned images. On the other hand, D-Fusion can retain the denoising trajectories of the resulting images, which are essential for DPO training. Extensive experiments demonstrate the effectiveness of D-Fusion in improving prompt-image alignment when applied to different reinforcement learning algorithms.
Towards Better Alignment: Training Diffusion Models with Reinforcement Learning Against Sparse Rewards
Mar 14, 2025Diffusion models have achieved remarkable success in text-to-image generation. However, their practical applications are hindered by the misalignment between generated images and corresponding text prompts. To tackle this issue, reinforcement learning (RL) has been considered for diffusion model fine-tuning. Yet, RL's effectiveness is limited by the challenge of sparse reward, where feedback is only available at the end of the generation process. This makes it difficult to identify which actions during the denoising process contribute positively to the final generated image, potentially leading to ineffective or unnecessary denoising policies. To this end, this paper presents a novel RL-based framework that addresses the sparse reward problem when training diffusion models. Our framework, named $\text{B}^2\text{-DiffuRL}$, employs two strategies: \textbf{B}ackward progressive training and \textbf{B}ranch-based sampling. For one thing, backward progressive training focuses initially on the final timesteps of denoising process and gradually extends the training interval to earlier timesteps, easing the learning difficulty from sparse rewards. For another, we perform branch-based sampling for each training interval. By comparing the samples within the same branch, we can identify how much the policies of the current training interval contribute to the final image, which helps to learn effective policies instead of unnecessary ones. $\text{B}^2\text{-DiffuRL}$ is compatible with existing optimization algorithms. Extensive experiments demonstrate the effectiveness of $\text{B}^2\text{-DiffuRL}$ in improving prompt-image alignment and maintaining diversity in generated images. The code for this work is available.