 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Stepwise Domain Knowledge-Driven Reasoning Optimization and Reflection Improvement
Apr 12, 2025
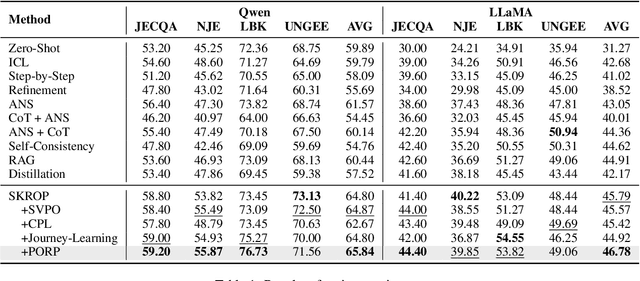
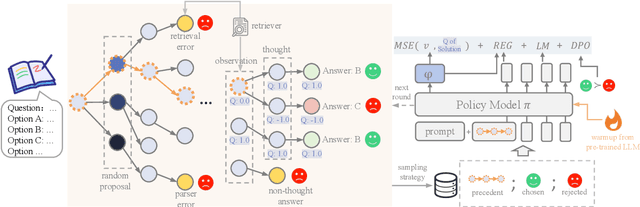
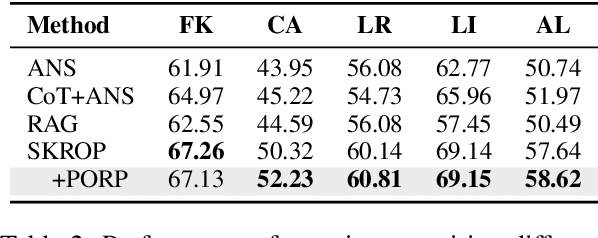
Recently, stepwise supervision on Chain of Thoughts (CoTs) presents an enhancement on the logical reasoning tasks such as coding and math, with the help of Monte Carlo Tree Search (MCTS). However, its contribution to tasks requiring domain-specific expertise and knowledge remains unexplored. Motivated by the interest, we identify several potential challenges of vanilla MCTS within this context, and propose the framework of Stepwise Domain Knowledge-Driven Reasoning Optimization, employing the MCTS algorithm to develop step-level supervision for problems that require essential comprehension, reasoning, and specialized knowledge. Additionally, we also introduce the Preference Optimization towards Reflection Paths, which iteratively learns self-reflection on the reasoning thoughts from better perspectives. We have conducted extensive experiments to evaluate the advantage of the methodologies. Empirical results demonstrate the effectiveness on various legal-domain problems. We also report a diverse set of valuable findings, hoping to encourage the enthusiasm to the research of domain-specific LLMs and MCTS.
Learning to Solve Domain-Specific Calculation Problems with Knowledge-Intensive Programs Generator
Dec 12, 2024Domain Large Language Models (LLMs) are developed for domain-specific tasks based on general LLMs. But it still requires professional knowledge to facilitate the expertise for some domain-specific tasks. In this paper, we investigate into knowledge-intensive calculation problems. We find that the math problems to be challenging for LLMs, when involving complex domain-specific rules and knowledge documents, rather than simple formulations of terminologies. Therefore, we propose a pipeline to solve the domain-specific calculation problems with Knowledge-Intensive Programs Generator more effectively, named as KIPG. It generates knowledge-intensive programs according to the domain-specific documents. For each query, key variables are extracted, then outcomes which are dependent on domain knowledge are calculated with the programs. By iterative preference alignment, the code generator learns to improve the logic consistency with the domain knowledge. Taking legal domain as an example, we have conducted experiments to prove the effectiveness of our pipeline, and extensive analysis on the modules. We also find that the code generator is also adaptable to other domains, without training on the new knowledge.
Gold Panning in Vocabulary: An Adaptive Method for Vocabulary Expansion of Domain-Specific LLMs
Oct 02, 2024



While Large Language Models (LLMs) demonstrate impressive generation abilities, they frequently struggle when it comes to specialized domains due to their limited domain-specific knowledge. Studies on domain-specific LLMs resort to expanding the vocabulary before fine-tuning on domain-specific corpus, aiming to decrease the sequence length and enhance efficiency during decoding, without thoroughly investigating the results of vocabulary expansion to LLMs over different domains. Our pilot study reveals that expansion with only a subset of the entire vocabulary may lead to superior performance. Guided by the discovery, this paper explores how to identify a vocabulary subset to achieve the optimal results. We introduce VEGAD, an adaptive method that automatically identifies valuable words from a given domain vocabulary. Our method has been validated through experiments on three Chinese datasets, demonstrating its effectiveness. Additionally, we have undertaken comprehensive analyses of the method. The selection of a optimal subset for expansion has shown to enhance performance on both domain-specific tasks and general tasks, showcasing the potential of VEGAD.
More Than Catastrophic Forgetting: Integrating General Capabilities For Domain-Specific LLMs
May 28, 2024



The performance on general tasks decreases after Large Language Models (LLMs) are fine-tuned on domain-specific tasks, the phenomenon is known as Catastrophic Forgetting (CF). However, this paper presents a further challenge for real application of domain-specific LLMs beyond CF, called General Capabilities Integration (GCI), which necessitates the integration of both the general capabilities and domain knowledge within a single instance. The objective of GCI is not merely to retain previously acquired general capabilities alongside new domain knowledge, but to harmonize and utilize both sets of skills in a cohesive manner to enhance performance on domain-specific tasks. Taking legal domain as an example, we carefully design three groups of training and testing tasks without lacking practicability, and construct the corresponding datasets. To better incorporate general capabilities across domain-specific scenarios, we introduce ALoRA, which utilizes a multi-head attention module upon LoRA, facilitating direct information transfer from preceding tokens to the current one. This enhancement permits the representation to dynamically switch between domain-specific knowledge and general competencies according to the attention. Extensive experiments are conducted on the proposed tasks. The results exhibit the significance of our setting, and the effectiveness of our method.
Enhance Robustness of Language Models Against Variation Attack through Graph Integration
Apr 18, 2024



The widespread use of pre-trained language models (PLMs) in natural language processing (NLP) has greatly improved performance outcomes. However, these models' vulnerability to adversarial attacks (e.g., camouflaged hints from drug dealers), particularly in the Chinese language with its rich character diversity/variation and complex structures, hatches vital apprehension. In this study, we propose a novel method, CHinese vAriatioN Graph Enhancement (CHANGE), to increase the robustness of PLMs against character variation attacks in Chinese content. CHANGE presents a novel approach for incorporating a Chinese character variation graph into the PLMs. Through designing different supplementary tasks utilizing the graph structure, CHANGE essentially enhances PLMs' interpretation of adversarially manipulated text. Experiments conducted in a multitude of NLP tasks show that CHANGE outperforms current language models in combating against adversarial attacks and serves as a valuable contribution to robust language model research. These findings contribute to the groundwork on robust language models and highlight the substantial potential of graph-guided pre-training strategies for real-world applications.
From Model-centered to Human-Centered: Revision Distance as a Metric for Text Evaluation in LLMs-based Applications
Apr 11, 2024



Evaluating large language models (LLMs) is fundamental, particularly in the context of practical applications. Conventional evaluation methods, typically designed primarily for LLM development, yield numerical scores that ignore the user experience. Therefore, our study shifts the focus from model-centered to human-centered evaluation in the context of AI-powered writing assistance applications. Our proposed metric, termed ``Revision Distance,'' utilizes LLMs to suggest revision edits that mimic the human writing process. It is determined by counting the revision edits generated by LLMs. Benefiting from the generated revision edit details, our metric can provide a self-explained text evaluation result in a human-understandable manner beyond the context-independent score. Our results show that for the easy-writing task, ``Revision Distance'' is consistent with established metrics (ROUGE, Bert-score, and GPT-score), but offers more insightful, detailed feedback and better distinguishes between texts. Moreover, in the context of challenging academic writing tasks, our metric still delivers reliable evaluations where other metrics tend to struggle. Furthermore, our metric also holds significant potential for scenarios lacking reference texts.
Personalized LLM Response Generation with Parameterized Memory Injection
Apr 04, 2024



Large Language Models (LLMs) have exhibited remarkable proficiency in comprehending and generating natural language. On the other hand, personalized LLM response generation holds the potential to offer substantial benefits for individuals in critical areas such as medical. Existing research has explored memory-augmented methods to prompt the LLM with pre-stored user-specific knowledge for personalized response generation in terms of new queries. We contend that such paradigm is unable to perceive fine-granularity information. In this study, we propose a novel \textbf{M}emory-\textbf{i}njected approach using parameter-efficient fine-tuning (PEFT) and along with a Bayesian Optimisation searching strategy to achieve \textbf{L}LM \textbf{P}ersonalization(\textbf{MiLP}).
A Chinese Prompt Attack Dataset for LLMs with Evil Content
Sep 21, 2023



Large Language Models (LLMs) present significant priority in text understanding and generation. However, LLMs suffer from the risk of generating harmful contents especially while being employed to applications. There are several black-box attack methods, such as Prompt Attack, which can change the behaviour of LLMs and induce LLMs to generate unexpected answers with harmful contents. Researchers are interested in Prompt Attack and Defense with LLMs, while there is no publicly available dataset to evaluate the abilities of defending prompt attack. In this paper, we introduce a Chinese Prompt Attack Dataset for LLMs, called CPAD. Our prompts aim to induce LLMs to generate unexpected outputs with several carefully designed prompt attack approaches and widely concerned attacking contents. Different from previous datasets involving safety estimation, We construct the prompts considering three dimensions: contents, attacking methods and goals, thus the responses can be easily evaluated and analysed. We run several well-known Chinese LLMs on our dataset, and the results show that our prompts are significantly harmful to LLMs, with around 70% attack success rate. We will release CPAD to encourage further studies on prompt attack and defense.
Constructing Multiple Tasks for Augmentation: Improving Neural Image Classification With K-means Features
Nov 18, 2019

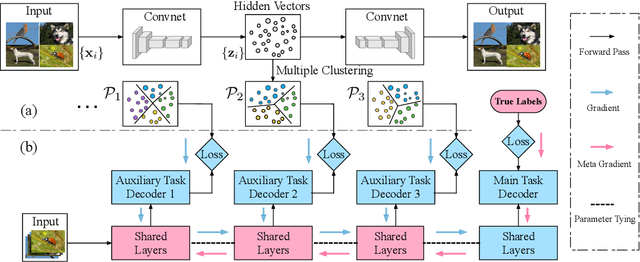

Multi-task learning (MTL) has received considerable attention, and numerous deep learning applications benefit from MTL with multiple objectives. However, constructing multiple related tasks is difficult, and sometimes only a single task is available for training in a dataset. To tackle this problem, we explored the idea of using unsupervised clustering to construct a variety of auxiliary tasks from unlabeled data or existing labeled data. We found that some of these newly constructed tasks could exhibit semantic meanings corresponding to certain human-specific attributes, but some were non-ideal. In order to effectively reduce the impact of non-ideal auxiliary tasks on the main task, we further proposed a novel meta-learning-based multi-task learning approach, which trained the shared hidden layers on auxiliary tasks, while the meta-optimization objective was to minimize the loss on the main task, ensuring that the optimizing direction led to an improvement on the main task. Experimental results across five image datasets demonstrated that the proposed method significantly outperformed existing single task learning, semi-supervised learning, and some data augmentation methods, including an improvement of more than 9% on the Omniglot dataset.