 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIND: Benchmarking Memory Consistency and Action Control in World Models
Feb 08, 2026World models aim to understand, remember, and predict dynamic visual environments, yet a unified benchmark for evaluating their fundamental abilities remains lacking. To address this gap, we introduce MIND, the first open-domain closed-loop revisited benchmark for evaluating Memory consIstency and action coNtrol in worlD models. MIND contains 250 high-quality videos at 1080p and 24 FPS, including 100 (first-person) + 100 (third-person) video clips under a shared action space and 25 + 25 clips across varied action spaces covering eight diverse scenes. We design an efficient evaluation framework to measure two core abilities: memory consistency and action control, capturing temporal stability and contextual coherence across viewpoints. Furthermore, we design various action spaces, including different character movement speeds and camera rotation angles, to evaluate the action generalization capability across different action spaces under shared scenes. To facilitate future performance benchmarking on MIND, we introduce MIND-World, a novel interactive Video-to-World baseline. Extensive experiments demonstrate the completeness of MIND and reveal key challenges in current world models, including the difficulty of maintaining long-term memory consistency and generalizing across action spaces. Project page: https://csu-jpg.github.io/MIND.github.io/
WEAVE: Unleashing and Benchmarking the In-context Interleaved Comprehension and Generation
Nov 14, 2025



Recent advances in unified multimodal models (UMMs) have enabled impressive progress in visual comprehension and generation. However, existing datasets and benchmarks focus primarily on single-turn interactions, failing to capture the multi-turn, context-dependent nature of real-world image creation and editing. To address this gap, we present WEAVE, the first suite for in-context interleaved cross-modality comprehension and generation. Our suite consists of two complementary parts. WEAVE-100k is a large-scale dataset of 100K interleaved samples spanning over 370K dialogue turns and 500K images, covering comprehension, editing, and generation tasks that require reasoning over historical context. WEAVEBench is a human-annotated benchmark with 100 tasks based on 480 images, featuring a hybrid VLM judger evaluation framework based on both the reference image and the combination of the original image with editing instructions that assesses models' abilities in multi-turn generation, visual memory, and world-knowledge reasoning across diverse domains. Experiments demonstrate that training on WEAVE-100k enables vision comprehension, image editing, and comprehension-generation collaboration capabilities. Furthermore, it facilitates UMMs to develop emergent visual-memory capabilities, while extensive evaluations on WEAVEBench expose the persistent limitations and challenges of current approaches in multi-turn, context-aware image generation and editing. We believe WEAVE provides a view and foundation for studying in-context interleaved comprehension and generation for multi-modal community.
Asynchronous Denoising Diffusion Models for Aligning Text-to-Image Generation
Oct 06, 2025Diffusion models have achieved impressive results in generating high-quality images. Yet, they often struggle to faithfully align the generated images with the input prompts. This limitation arises from synchronous denoising, where all pixels simultaneously evolve from random noise to clear images. As a result, during generation, the prompt-related regions can only reference the unrelated regions at the same noise level, failing to obtain clear context and ultimately impairing text-to-image alignment. To address this issue, we propose asynchronous diffusion models -- a novel framework that allocates distinct timesteps to different pixels and reformulates the pixel-wise denoising process. By dynamically modulating the timestep schedules of individual pixels, prompt-related regions are denoised more gradually than unrelated regions, thereby allowing them to leverage clearer inter-pixel context. Consequently, these prompt-related regions achieve better alignment in the final images. Extensive experiments demonstrate that our asynchronous diffusion models can significantly improve text-to-image alignment across diverse prompts. The code repository for this work is available at https://github.com/hu-zijing/AsynDM.
Heartcare Suite: Multi-dimensional Understanding of ECG with Raw Multi-lead Signal Modeling
Jun 06, 2025We present Heartcare Suite, a multimodal comprehensive framework for finegrained electrocardiogram (ECG) understanding. It comprises three key components: (i) Heartcare-220K, a high-quality, structured, and comprehensive multimodal ECG dataset covering essential tasks such as disease diagnosis, waveform morphology analysis, and rhythm interpretation. (ii) Heartcare-Bench, a systematic and multi-dimensional benchmark designed to evaluate diagnostic intelligence and guide the optimization of Medical Multimodal Large Language Models (Med-MLLMs) in ECG scenarios. and (iii) HeartcareGPT with a tailored tokenizer Bidirectional ECG Abstract Tokenization (Beat), which compresses raw multi-lead signals into semantically rich discrete tokens via duallevel vector quantization and query-guided bidirectional diffusion mechanism. Built upon Heartcare-220K, HeartcareGPT achieves strong generalization and SoTA performance across multiple clinically meaningful tasks. Extensive experiments demonstrate that Heartcare Suite is highly effective in advancing ECGspecific multimodal understanding and evaluation. Our project is available at https://github.com/Wznnnnn/Heartcare-Suite .
D-Fusion: Direct Preference Optimization for Aligning Diffusion Models with Visually Consistent Samples
May 28, 2025
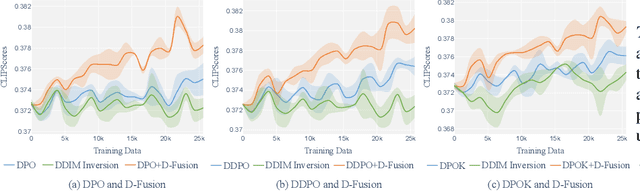
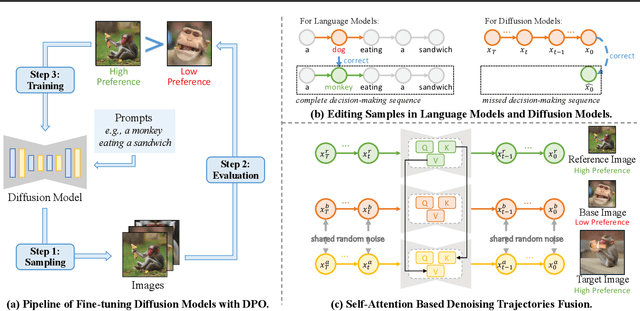
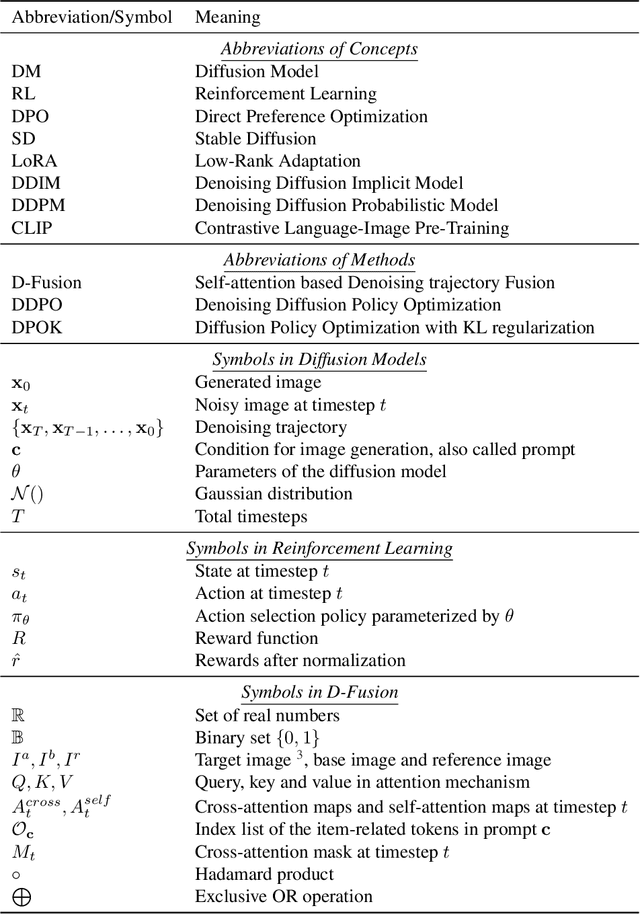
The practical applications of diffusion models have been limited by the misalignment between generated images and corresponding text prompts. Recent studies have introduced direct preference optimization (DPO) to enhance the alignment of these models. However, the effectiveness of DPO is constrained by the issue of visual inconsistency, where the significant visual disparity between well-aligned and poorly-aligned images prevents diffusion models from identifying which factors contribute positively to alignment during fine-tuning. To address this issue, this paper introduces D-Fusion, a method to construct DPO-trainable visually consistent samples. On one hand, by performing mask-guided self-attention fusion, the resulting images are not only well-aligned, but also visually consistent with given poorly-aligned images. On the other hand, D-Fusion can retain the denoising trajectories of the resulting images, which are essential for DPO training. Extensive experiments demonstrate the effectiveness of D-Fusion in improving prompt-image alignment when applied to different reinforcement learning algorithms.
Selftok: Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 18, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 12, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Towards Better Alignment: Training Diffusion Models with Reinforcement Learning Against Sparse Rewards
Mar 14, 2025Diffusion models have achieved remarkable success in text-to-image generation. However, their practical applications are hindered by the misalignment between generated images and corresponding text prompts. To tackle this issue, reinforcement learning (RL) has been considered for diffusion model fine-tuning. Yet, RL's effectiveness is limited by the challenge of sparse reward, where feedback is only available at the end of the generation process. This makes it difficult to identify which actions during the denoising process contribute positively to the final generated image, potentially leading to ineffective or unnecessary denoising policies. To this end, this paper presents a novel RL-based framework that addresses the sparse reward problem when training diffusion models. Our framework, named $\text{B}^2\text{-DiffuRL}$, employs two strategies: \textbf{B}ackward progressive training and \textbf{B}ranch-based sampling. For one thing, backward progressive training focuses initially on the final timesteps of denoising process and gradually extends the training interval to earlier timesteps, easing the learning difficulty from sparse rewards. For another, we perform branch-based sampling for each training interval. By comparing the samples within the same branch, we can identify how much the policies of the current training interval contribute to the final image, which helps to learn effective policies instead of unnecessary ones. $\text{B}^2\text{-DiffuRL}$ is compatible with existing optimization algorithms. Extensive experiments demonstrate the effectiveness of $\text{B}^2\text{-DiffuRL}$ in improving prompt-image alignment and maintaining diversity in generated images. The code for this work is available.
R3HF: Reward Redistribution for Enhancing Reinforcement Learning from Human Feedback
Nov 13, 2024Reinforcement learning from human feedback (RLHF) provides a paradigm for aligning large language models (LLMs) with human preferences. This involves the initial training of a reward model based on pairwise human feedback. The reward model is subsequently utilized in reinforcement learning to assess the scores of each generated sentence as a whole, further guiding the optimization of LLMs. However, current approaches have a significant shortcoming: \emph{They allocate a single, sparse, and delayed reward to an entire sequence of output}. This may overlook some significant individual contributions of each token towards the desired outcome. To overcome this limitation, our paper proposes a novel reward redistribution method called R3HF, which facilitates a more fine-grained, token-level reward allocation. Specifically, our method treats the reward prediction task of the reward model as a regression problem. As a result, the redistributed rewards are computed by evaluating the specific contribution of each token to the reward model's output. This detailed approach improves the model's understanding of language nuances, leading to more precise enhancements in its performance. Our method is crafted to integrate seamlessly with most current techniques while incurring minimal computational costs. Through comprehensive experiments across diverse datasets and tasks, we have verified the effectiveness and superiority of our approach.
Distributionally Generative Augmentation for Fair Facial Attribute Classification
Mar 11, 2024



Facial Attribute Classification (FAC) holds substantial promise in widespread applications. However, FAC models trained by traditional methodologies can be unfair by exhibiting accuracy inconsistencies across varied data subpopulations. This unfairness is largely attributed to bias in data, where some spurious attributes (e.g., Male) statistically correlate with the target attribute (e.g., Smiling). Most of existing fairness-aware methods rely on the labels of spurious attributes, which may be unavailable in practice. This work proposes a novel, generation-based two-stage framework to train a fair FAC model on biased data without additional annotation. Initially, we identify the potential spurious attributes based on generative models. Notably, it enhances interpretability by explicitly showing the spurious attributes in image space. Following this, for each image, we first edit the spurious attributes with a random degree sampled from a uniform distribution, while keeping target attribute unchanged. Then we train a fair FAC model by fostering model invariance to these augmentation. Extensive experiments on three common datasets demonstrate the effectiveness of our method in promoting fairness in FAC without compromising accuracy. Codes are in https://github.com/heqianpei/DiGA.